 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba-ST: State Space Model for Efficient Style Transfer
Paper and Code

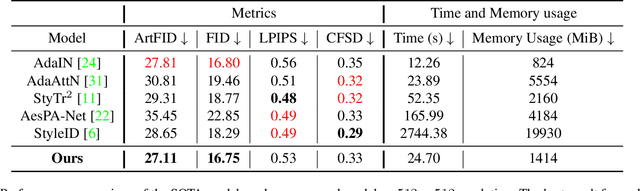
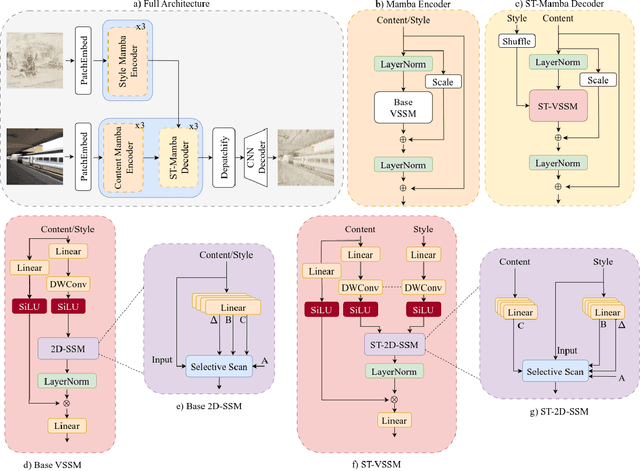
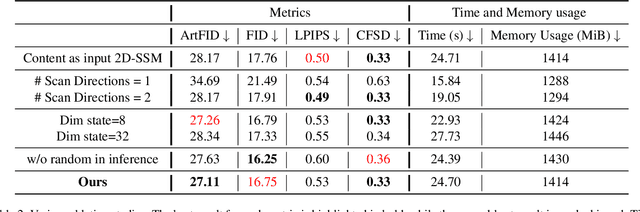
The goal of style transfer is, given a content image and a style source, generating a new image preserving the content but with the artistic representation of the style source. Most of the state-of-the-art architectures use transformers or diffusion-based models to perform this task, despite the heavy computational burden that they require. In particular, transformers use self- and cross-attention layers which have large memory footprint, while diffusion models require high inference time. To overcome the above, this paper explores a novel design of Mamba, an emergent State-Space Model (SSM), called Mamba-ST, to perform style transfer. To do so, we adapt Mamba linear equation to simulate the behavior of cross-attention layers, which are able to combine two separate embeddings into a single output, but drastically reducing memory usage and time complexity. We modified the Mamba's inner equations so to accept inputs from, and combine, two separate data streams. To the best of our knowledge, this is the first attempt to adapt the equations of SSMs to a vision task like style transfer without requiring any other module like cross-attention or custom normalization layers. An extensive set of experiments demonstrates the superiority and efficiency of our method in performing style transfer compared to transformers and diffusion models. Results show improved quality in terms of both ArtFID and FID metrics. Code is available at https://github.com/FilippoBotti/MambaST.