 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveMAE: Wavelet decomposition Masked Auto-Encoder for Remote Sensing
Oct 26, 2025Self-supervised learning (SSL) has recently emerged as a key strategy for building foundation models in remote sensing, where the scarcity of annotated data limits the applicability of fully supervised approaches. In this work, we introduce WaveMAE, a masked autoencoding framework tailored for multispectral satellite imagery. Unlike conventional pixel-based reconstruction, WaveMAE leverages a multi-level Discrete Wavelet Transform (DWT) to disentangle frequency components and guide the encoder toward learning scale-aware high-frequency representations. We further propose a Geo-conditioned Positional Encoding (GPE), which incorporates geographical priors via Spherical Harmonics, encouraging embeddings that respect both semantic and geospatial structure. To ensure fairness in evaluation, all methods are pretrained on the same dataset (fMoW-S2) and systematically evaluated on the diverse downstream tasks of the PANGAEA benchmark, spanning semantic segmentation, regression, change detection, and multilabel classification. Extensive experiments demonstrate that WaveMAE achieves consistent improvements over prior state-of-the-art approaches, with substantial gains on segmentation and regression benchmarks. The effectiveness of WaveMAE pretraining is further demonstrated by showing that even a lightweight variant, containing only 26.4% of the parameters, achieves state-of-the-art performance. Our results establish WaveMAE as a strong and geographically informed foundation model for multispectral remote sensing imagery.
Swin2-MoSE: A New Single Image Super-Resolution Model for Remote Sensing
Apr 29, 2024
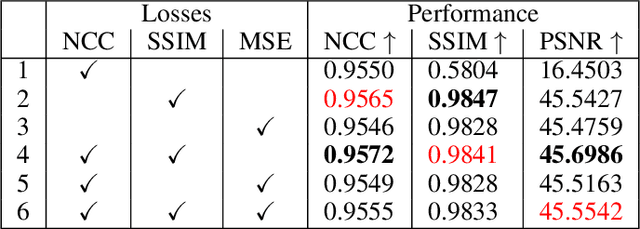
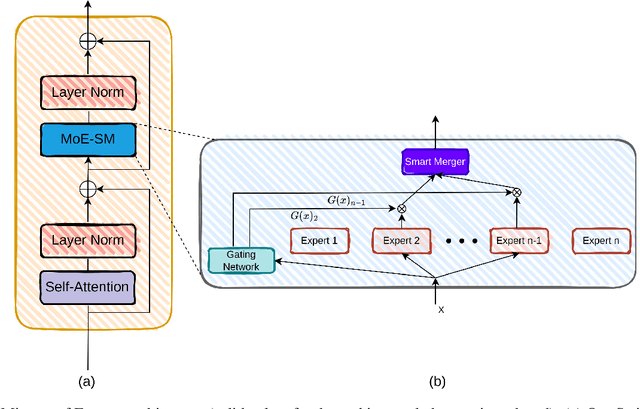
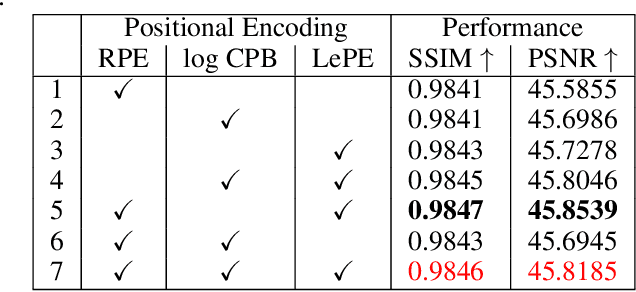
Due to the limitations of current optical and sensor technologies and the high cost of updating them, the spectral and spatial resolution of satellites may not always meet desired requirements. For these reasons, Remote-Sensing Single-Image Super-Resolution (RS-SISR) techniques have gained significant interest. In this paper, we propose Swin2-MoSE model, an enhanced version of Swin2SR. Our model introduces MoE-SM, an enhanced Mixture-of-Experts (MoE) to replace the Feed-Forward inside all Transformer block. MoE-SM is designed with Smart-Merger, and new layer for merging the output of individual experts, and with a new way to split the work between experts, defining a new per-example strategy instead of the commonly used per-token one. Furthermore, we analyze how positional encodings interact with each other, demonstrating that per-channel bias and per-head bias can positively cooperate. Finally, we propose to use a combination of Normalized-Cross-Correlation (NCC) and Structural Similarity Index Measure (SSIM) losses, to avoid typical MSE loss limitations. Experimental results demonstrate that Swin2-MoSE outperforms SOTA by up to 0.377 ~ 0.958 dB (PSNR) on task of 2x, 3x and 4x resolution-upscaling (Sen2Venus and OLI2MSI datasets). We show the efficacy of Swin2-MoSE, applying it to a semantic segmentation task (SeasoNet dataset). Code and pretrained are available on https://github.com/IMPLabUniPr/swin2-mose/tree/official_code
Memory-augmented Online Video Anomaly Detection
Feb 21, 2023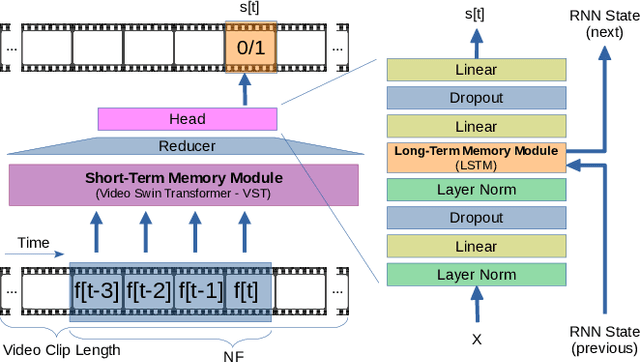
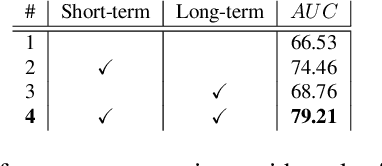
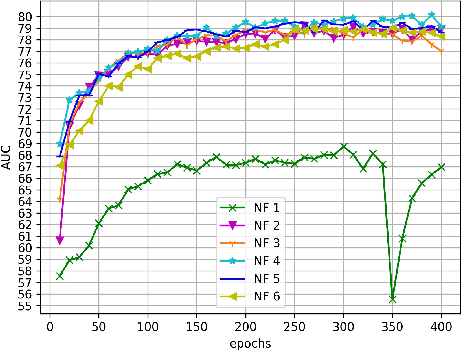

The ability to understand the surrounding scene is of paramount importance for Autonomous Vehicles (AVs). This paper presents a system capable to work in a real time guaranteed response times and online fashion, giving an immediate response to the arise of anomalies surrounding the AV, exploiting only the videos captured by a dash-mounted camera. Our architecture, called MOVAD, relies on two main modules: a short-term memory to extract information related to the ongoing action, implemented by a Video Swin Transformer adapted to work in an online scenario, and a long-term memory module that considers also remote past information thanks to the use of a Long-Short Term Memory (LSTM) network. We evaluated the performance of our method on Detection of Traffic Anomaly (DoTA) dataset, a challenging collection of dash-mounted camera videos of accidents. After an extensive ablation study, MOVAD is able to reach an AUC score of 82.11%, surpassing the current state-of-the-art by +2.81 AUC. Our code will be available on https://github.com/IMPLabUniPr/movad/tree/icip