 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALED : Surrogate-gradient for Codec-Aware Learning of Downsampling in ABR Streaming
Jan 30, 2026The rapid growth in video consumption has introduced significant challenges to modern streaming architectures. Over-the-Top (OTT) video delivery now predominantly relies on Adaptive Bitrate (ABR) streaming, which dynamically adjusts bitrate and resolution based on client-side constraints such as display capabilities and network bandwidth. This pipeline typically involves downsampling the original high-resolution content, encoding and transmitting it, followed by decoding and upsampling on the client side. Traditionally, these processing stages have been optimized in isolation, leading to suboptimal end-to-end rate-distortion (R-D) performance. The advent of deep learning has spurred interest in jointly optimizing the ABR pipeline using learned resampling methods. However, training such systems end-to-end remains challenging due to the non-differentiable nature of standard video codecs, which obstructs gradient-based optimization. Recent works have addressed this issue using differentiable proxy models, based either on deep neural networks or hybrid coding schemes with differentiable components such as soft quantization, to approximate the codec behavior. While differentiable proxy codecs have enabled progress in compression-aware learning, they remain approximations that may not fully capture the behavior of standard, non-differentiable codecs. To our knowledge, there is no prior evidence demonstrating the inefficiencies of using standard codecs during training. In this work, we introduce a novel framework that enables end-to-end training with real, non-differentiable codecs by leveraging data-driven surrogate gradients derived from actual compression errors. It facilitates the alignment between training objectives and deployment performance. Experimental results show a 5.19\% improvement in BD-BR (PSNR) compared to codec-agnostic training approaches, consistently across the entire rate-distortion convex hull spanning multiple downsampling ratios.
Compressing image encoders via latent distillation
Jan 09, 2026Deep learning models for image compression often face practical limitations in hardware-constrained applications. Although these models achieve high-quality reconstructions, they are typically complex, heavyweight, and require substantial training data and computational resources. We propose a methodology to partially compress these networks by reducing the size of their encoders. Our approach uses a simplified knowledge distillation strategy to approximate the latent space of the original models with less data and shorter training, yielding lightweight encoders from heavyweight ones. We evaluate the resulting lightweight encoders across two different architectures on the image compression task. Experiments show that our method preserves reconstruction quality and statistical fidelity better than training lightweight encoders with the original loss, making it practical for resource-limited environments.
OSLO-IC: On-the-Sphere Learned Omnidirectional Image Compression with Attention Modules and Spatial Context
Mar 17, 2025
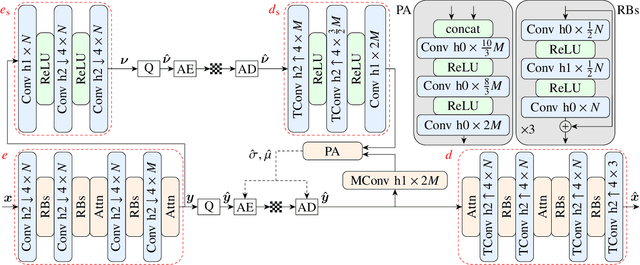
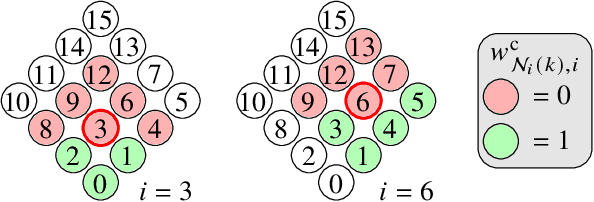
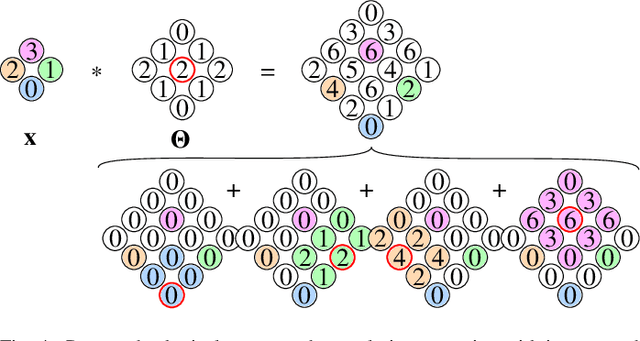
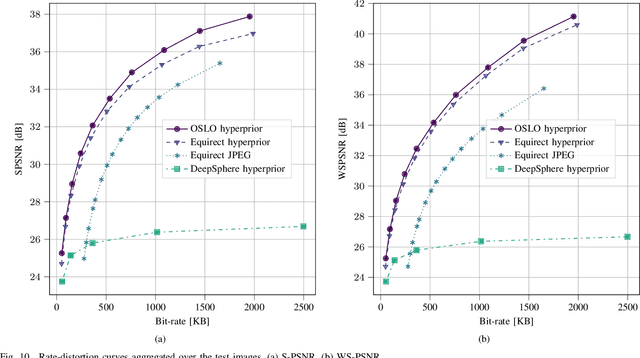
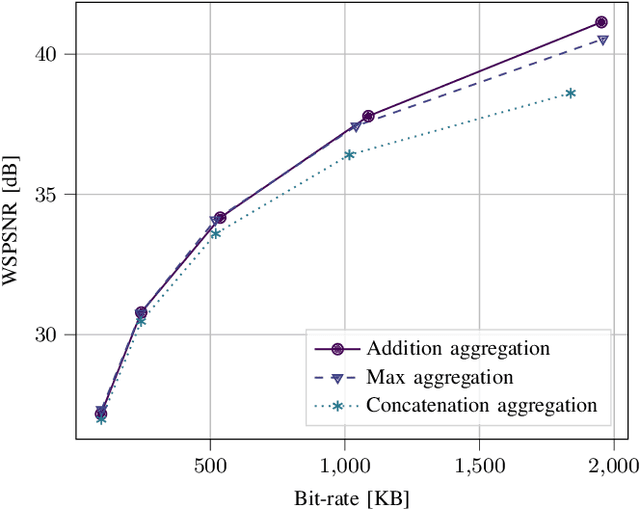
Developing effective 360-degree (spherical) image compression techniques is crucial for technologies like virtual reality and automated driving. This paper advances the state-of-the-art in on-the-sphere learning (OSLO) for omnidirectional image compression framework by proposing spherical attention modules, residual blocks, and a spatial autoregressive context model. These improvements achieve a 23.1% bit rate reduction in terms of WS-PSNR BD rate. Additionally, we introduce a spherical transposed convolution operator for upsampling, which reduces trainable parameters by a factor of four compared to the pixel shuffling used in the OSLO framework, while maintaining similar compression performance. Therefore, in total, our proposed method offers significant rate savings with a smaller architecture and can be applied to any spherical convolutional application.
SMIC: Semantic Multi-Item Compression based on CLIP dictionary
Dec 06, 2024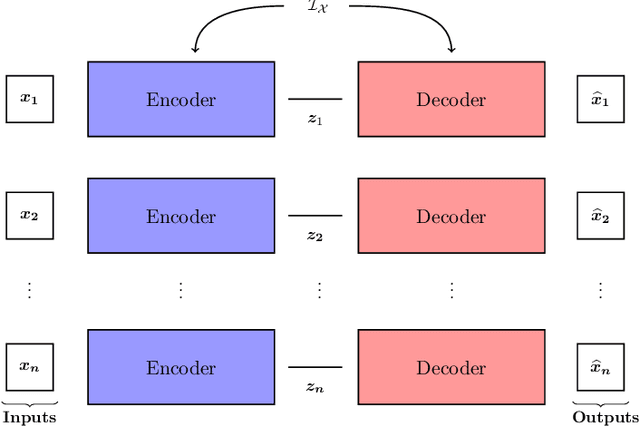

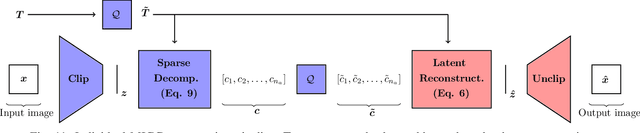
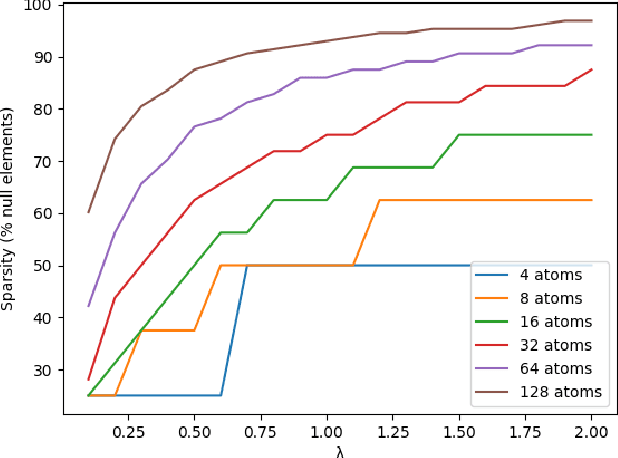
Semantic compression, a compression scheme where the distortion metric, typically MSE, is replaced with semantic fidelity metrics, tends to become more and more popular. Most recent semantic compression schemes rely on the foundation model CLIP. In this work, we extend such a scheme to image collection compression, where inter-item redundancy is taken into account during the coding phase. For that purpose, we first show that CLIP's latent space allows for easy semantic additions and subtractions. From this property, we define a dictionary-based multi-item codec that outperforms state-of-the-art generative codec in terms of compression rate, around $10^{-5}$ BPP per image, while not sacrificing semantic fidelity. We also show that the learned dictionary is of a semantic nature and works as a semantic projector for the semantic content of images.
Fine color guidance in diffusion models and its application to image compression at extremely low bitrates
Apr 10, 2024


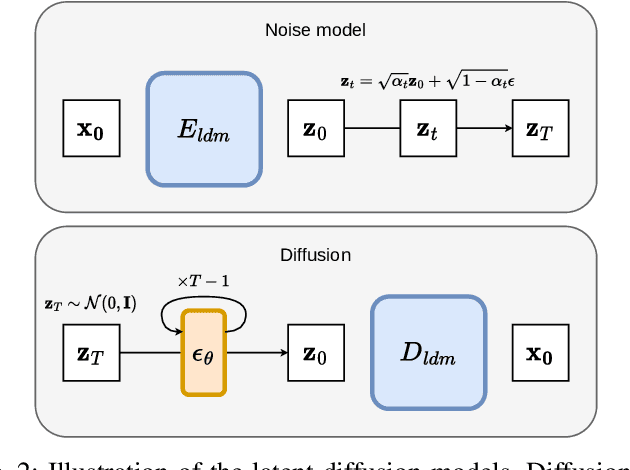
This study addresses the challenge of, without training or fine-tuning, controlling the global color aspect of images generated with a diffusion model. We rewrite the guidance equations to ensure that the outputs are closer to a known color map, and this without hindering the quality of the generation. Our method leads to new guidance equations. We show in the color guidance context that, the scaling of the guidance should not decrease but remains high throughout the diffusion process. In a second contribution, our guidance is applied in a compression framework, we combine both semantic and general color information on the image to decode the images at low cost. We show that our method is effective at improving fidelity and realism of compressed images at extremely low bit rates, when compared to other classical or more semantic oriented approaches.
OSLO: On-the-Sphere Learning for Omnidirectional images and its application to 360-degree image compression
Jul 19, 2021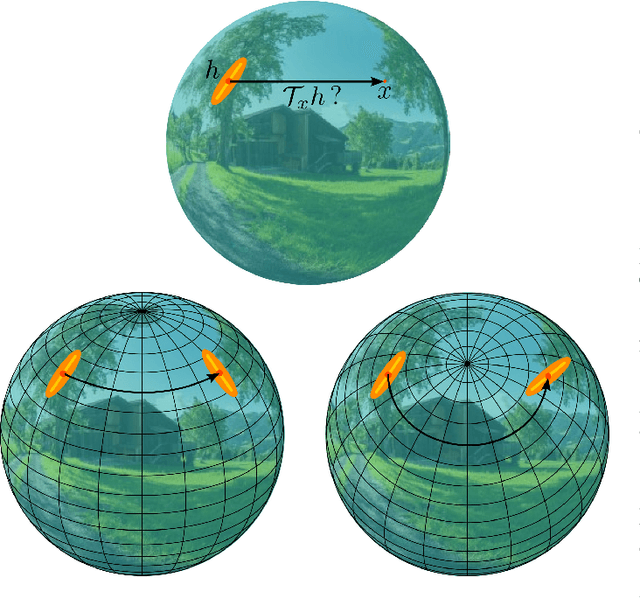
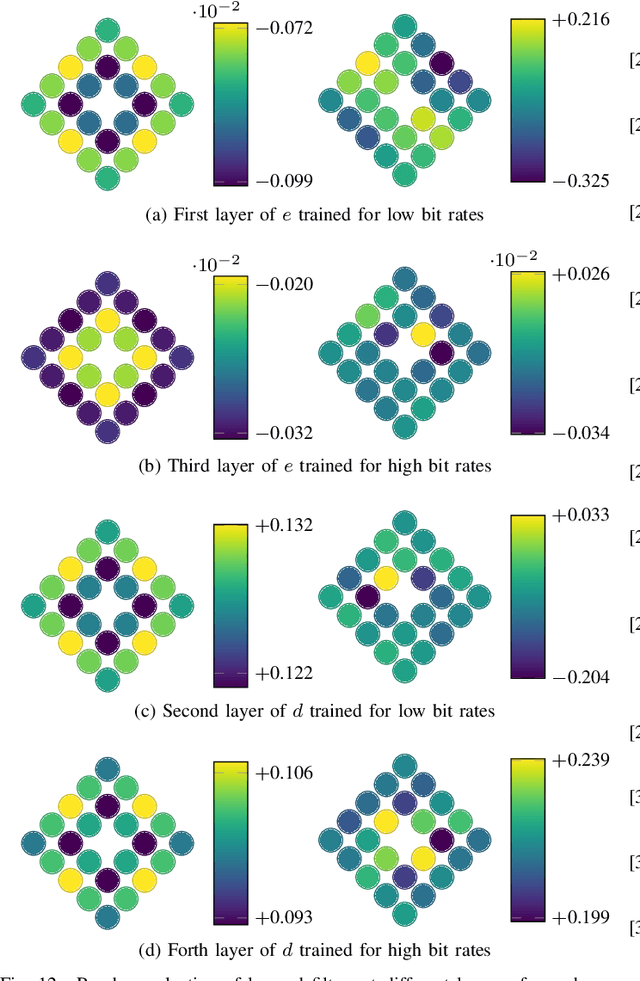
State-of-the-art 2D image compression schemes rely on the power of convolutional neural networks (CNNs). Although CNNs offer promising perspectives for 2D image compression, extending such models to omnidirectional images is not straightforward. First, omnidirectional images have specific spatial and statistical properties that can not be fully captured by current CNN models. Second, basic mathematical operations composing a CNN architecture, e.g., translation and sampling, are not well-defined on the sphere. In this paper, we study the learning of representation models for omnidirectional images and propose to use the properties of HEALPix uniform sampling of the sphere to redefine the mathematical tools used in deep learning models for omnidirectional images. In particular, we: i) propose the definition of a new convolution operation on the sphere that keeps the high expressiveness and the low complexity of a classical 2D convolution; ii) adapt standard CNN techniques such as stride, iterative aggregation, and pixel shuffling to the spherical domain; and then iii) apply our new framework to the task of omnidirectional image compression. Our experiments show that our proposed on-the-sphere solution leads to a better compression gain that can save 13.7% of the bit rate compared to similar learned models applied to equirectangular images. Also, compared to learning models based on graph convolutional networks, our solution supports more expressive filters that can preserve high frequencies and provide a better perceptual quality of the compressed images. Such results demonstrate the efficiency of the proposed framework, which opens new research venues for other omnidirectional vision tasks to be effectively implemented on the sphere manifold.
Fine granularity access in interactive compression of 360-degree images based on rate adaptive channel codes
Jun 25, 2020
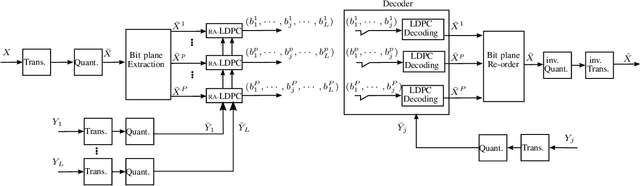

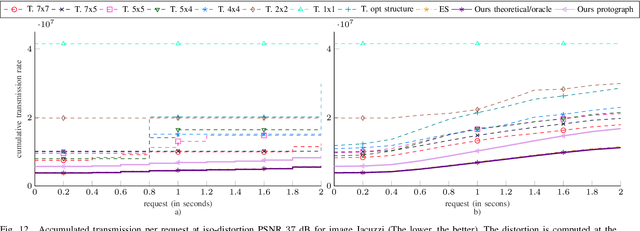
In this paper, we propose a new interactive compression scheme for omnidirectional images. This requires two characteristics: efficient compression of data, to lower the storage cost, and random access ability to extract part of the compressed stream requested by the user (for reducing the transmission rate). For efficient compression, data needs to be predicted by a series of references that have been pre-defined and compressed. This contrasts with the spirit of random accessibility. We propose a solution for this problem based on incremental codes implemented by rate adaptive channel codes. This scheme encodes the image while adapting to any user request and leads to an efficient coding that is flexible in extracting data depending on the available information at the decoder. Therefore, only the information that is needed to be displayed at the user's side is transmitted during the user's request as if the request was already known at the encoder. The experimental results demonstrate that our coder obtains better transmission rate than the state-of-the-art tile-based methods at a small cost in storage. Moreover, the transmission rate grows gradually with the size of the request and avoids a staircase effect, which shows the perfect suitability of our coder for interactive transmission.
Geometry-Aware Graph Transforms for Light Field Compact Representation
Mar 08, 2019
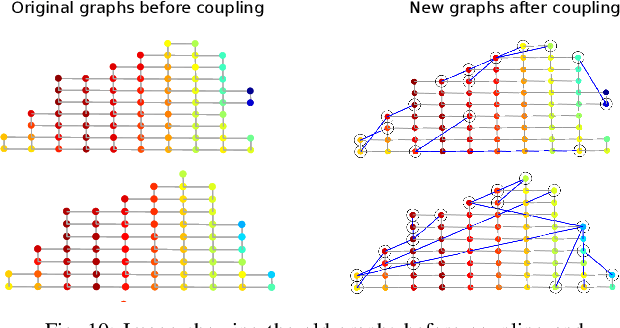
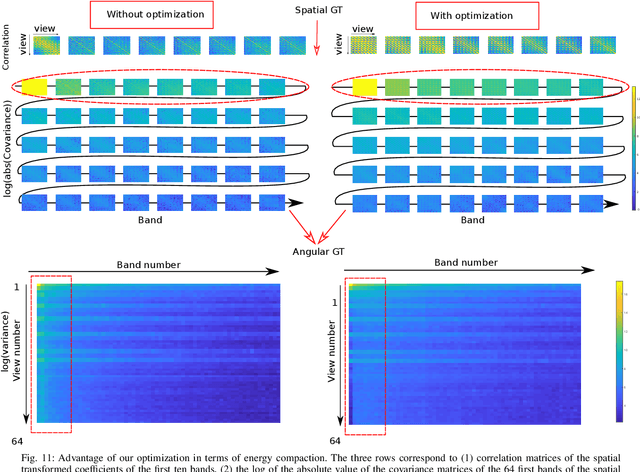
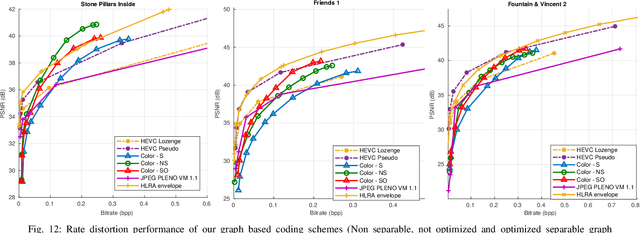
The paper addresses the problem of energy compaction of dense 4D light fields by designing geometry-aware local graph-based transforms. Local graphs are constructed on super-rays that can be seen as a grouping of spatially and geometry-dependent angularly correlated pixels. Both non separable and separable transforms are considered. Despite the local support of limited size defined by the super-rays, the Laplacian matrix of the non separable graph remains of high dimension and its diagonalization to compute the transform eigen vectors remains computationally expensive. To solve this problem, we then perform the local spatio-angular transform in a separable manner. We show that when the shape of corresponding super-pixels in the different views is not isometric, the basis functions of the spatial transforms are not coherent, resulting in decreased correlation between spatial transform coefficients. We hence propose a novel transform optimization method that aims at preserving angular correlation even when the shapes of the super-pixels are not isometric. Experimental results show the benefit of the approach in terms of energy compaction. A coding scheme is also described to assess the rate-distortion perfomances of the proposed transforms and is compared to state of the art encoders namely HEVC and JPEG Pleno VM 1.1.
Prediction and Sampling with Local Graph Transforms for Quasi-Lossless Light Field Compression
Mar 08, 2019
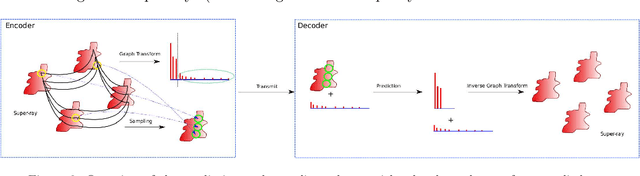

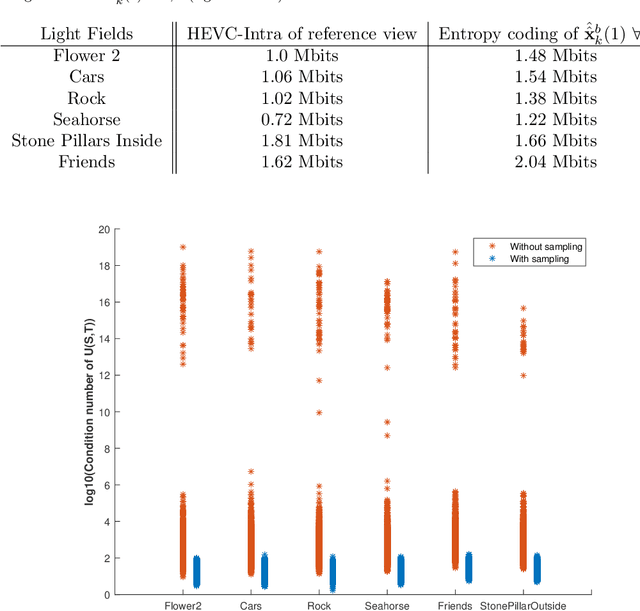
Graph-based transforms have been shown to be powerful tools in terms of image energy compaction. However, when the support increases to best capture signal dependencies, the computation of the basis functions becomes rapidly untractable. This problem is in particular compelling for high dimensional imaging data such as light fields. The use of local transforms with limited supports is a way to cope with this computational difficulty. Unfortunately, the locality of the support may not allow us to fully exploit long term signal dependencies present in both the spatial and angular dimensions in the case of light fields. This paper describes sampling and prediction schemes with local graph-based transforms enabling to efficiently compact the signal energy and exploit dependencies beyond the local graph support. The proposed approach is investigated and is shown to be very efficient in the context of spatio-angular transforms for quasi-lossless compression of light fields.
Navigation domain representation for interactive multiview imaging
Jun 17, 2013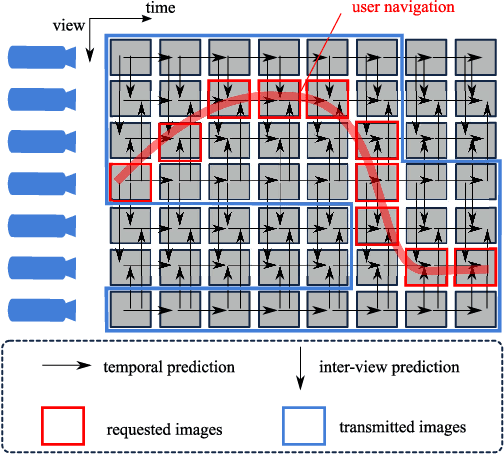
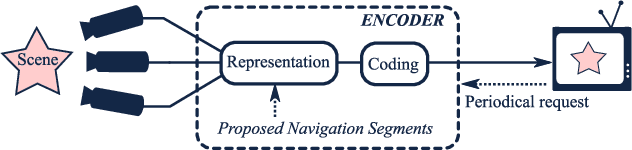
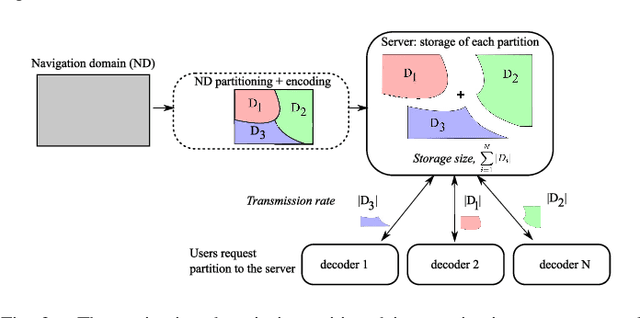
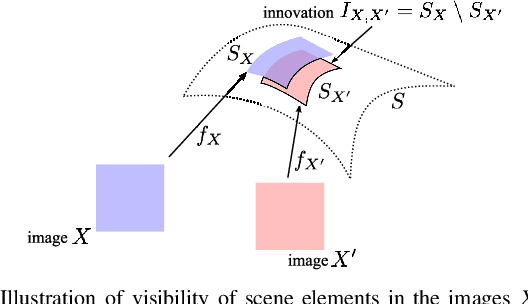
Enabling users to interactively navigate through different viewpoints of a static scene is a new interesting functionality in 3D streaming systems. While it opens exciting perspectives towards rich multimedia applications, it requires the design of novel representations and coding techniques in order to solve the new challenges imposed by interactive navigation. Interactivity clearly brings new design constraints: the encoder is unaware of the exact decoding process, while the decoder has to reconstruct information from incomplete subsets of data since the server can generally not transmit images for all possible viewpoints due to resource constrains. In this paper, we propose a novel multiview data representation that permits to satisfy bandwidth and storage constraints in an interactive multiview streaming system. In particular, we partition the multiview navigation domain into segments, each of which is described by a reference image and some auxiliary information. The auxiliary information enables the client to recreate any viewpoint in the navigation segment via view synthesis. The decoder is then able to navigate freely in the segment without further data request to the server; it requests additional data only when it moves to a different segment. We discuss the benefits of this novel representation in interactive navigation systems and further propose a method to optimize the partitioning of the navigation domain into independent segments, under bandwidth and storage constraints. Experimental results confirm the potential of the proposed representation; namely, our system leads to similar compression performance as classical inter-view coding, while it provides the high level of flexibility that is required for interactive streaming. Hence, our new framework represents a promising solution for 3D data representation in novel interactive multimedia services.