 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeadset: Human emotion awareness under partial occlusions multimodal dataset
Feb 14, 2024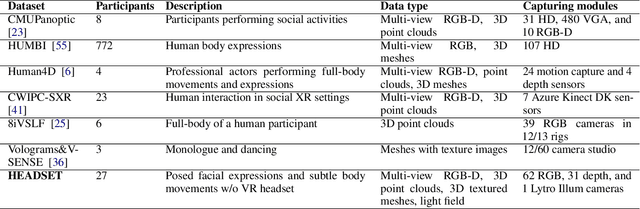


The volumetric representation of human interactions is one of the fundamental domains in the development of immersive media productions and telecommunication applications. Particularly in the context of the rapid advancement of Extended Reality (XR) applications, this volumetric data has proven to be an essential technology for future XR elaboration. In this work, we present a new multimodal database to help advance the development of immersive technologies. Our proposed database provides ethically compliant and diverse volumetric data, in particular 27 participants displaying posed facial expressions and subtle body movements while speaking, plus 11 participants wearing head-mounted displays (HMDs). The recording system consists of a volumetric capture (VoCap) studio, including 31 synchronized modules with 62 RGB cameras and 31 depth cameras. In addition to textured meshes, point clouds, and multi-view RGB-D data, we use one Lytro Illum camera for providing light field (LF) data simultaneously. Finally, we also provide an evaluation of our dataset employment with regard to the tasks of facial expression classification, HMDs removal, and point cloud reconstruction. The dataset can be helpful in the evaluation and performance testing of various XR algorithms, including but not limited to facial expression recognition and reconstruction, facial reenactment, and volumetric video. HEADSET and its all associated raw data and license agreement will be publicly available for research purposes.
Light-weight CNN-based VVC Inter Partitioning Acceleration
Dec 17, 2023



The Versatile Video Coding (VVC) standard has been finalized by Joint Video Exploration Team (JVET) in 2020. Compared to the High Efficiency Video Coding (HEVC) standard, VVC offers about 50% compression efficiency gain, in terms of Bjontegaard Delta-Rate (BD-rate), at the cost of about 10x more encoder complexity. In this paper, we propose a Convolutional Neural Network (CNN)-based method to speed up inter partitioning in VVC. Our method operates at the Coding Tree Unit (CTU) level, by splitting each CTU into a fixed grid of 8x8 blocks. Then each cell in this grid is associated with information about the partitioning depth within that area. A lightweight network for predicting this grid is employed during the rate-distortion optimization to limit the Quaternary Tree (QT)-split search and avoid partitions that are unlikely to be selected. Experiments show that the proposed method can achieve acceleration ranging from 17% to 30% in the RandomAccess Group Of Picture 32 (RAGOP32) mode of VVC Test Model (VTM)10 with a reasonable efficiency drop ranging from 0.37% to 1.18% in terms of BD-rate increase.
CNN-based Prediction of Partition Path for VVC Fast Inter Partitioning Using Motion Fields
Oct 20, 2023



The Versatile Video Coding (VVC) standard has been recently finalized by the Joint Video Exploration Team (JVET). Compared to the High Efficiency Video Coding (HEVC) standard, VVC offers about 50% compression efficiency gain, in terms of Bjontegaard Delta-Rate (BD-rate), at the cost of a 10-fold increase in encoding complexity. In this paper, we propose a method based on Convolutional Neural Network (CNN) to speed up the inter partitioning process in VVC. Firstly, a novel representation for the quadtree with nested multi-type tree (QTMT) partition is introduced, derived from the partition path. Secondly, we develop a U-Net-based CNN taking a multi-scale motion vector field as input at the Coding Tree Unit (CTU) level. The purpose of CNN inference is to predict the optimal partition path during the Rate-Distortion Optimization (RDO) process. To achieve this, we divide CTU into grids and predict the Quaternary Tree (QT) depth and Multi-type Tree (MT) split decisions for each cell of the grid. Thirdly, an efficient partition pruning algorithm is introduced to employ the CNN predictions at each partitioning level to skip RDO evaluations of unnecessary partition paths. Finally, an adaptive threshold selection scheme is designed, making the trade-off between complexity and efficiency scalable. Experiments show that the proposed method can achieve acceleration ranging from 16.5% to 60.2% under the RandomAccess Group Of Picture 32 (RAGOP32) configuration with a reasonable efficiency drop ranging from 0.44% to 4.59% in terms of BD-rate, which surpasses other state-of-the-art solutions. Additionally, our method stands out as one of the lightest approaches in the field, which ensures its applicability to other encoders.
Learning Kernel-Modulated Neural Representation for Efficient Light Field Compression
Jul 12, 2023



Light field is a type of image data that captures the 3D scene information by recording light rays emitted from a scene at various orientations. It offers a more immersive perception than classic 2D images but at the cost of huge data volume. In this paper, we draw inspiration from the visual characteristics of Sub-Aperture Images (SAIs) of light field and design a compact neural network representation for the light field compression task. The network backbone takes randomly initialized noise as input and is supervised on the SAIs of the target light field. It is composed of two types of complementary kernels: descriptive kernels (descriptors) that store scene description information learned during training, and modulatory kernels (modulators) that control the rendering of different SAIs from the queried perspectives. To further enhance compactness of the network meanwhile retain high quality of the decoded light field, we accordingly introduce modulator allocation and kernel tensor decomposition mechanisms, followed by non-uniform quantization and lossless entropy coding techniques, to finally form an efficient compression pipeline. Extensive experiments demonstrate that our method outperforms other state-of-the-art (SOTA) methods by a significant margin in the light field compression task. Moreover, after aligning descriptors, the modulators learned from one light field can be transferred to new light fields for rendering dense views, indicating a potential solution for view synthesis task.
Learning-based Spatial and Angular Information Separation for Light Field Compression
Apr 13, 2023



Light fields are a type of image data that capture both spatial and angular scene information by recording light rays emitted by a scene from different orientations. In this context, spatial information is defined as features that remain static regardless of perspectives, while angular information refers to features that vary between viewpoints. We propose a novel neural network that, by design, can separate angular and spatial information of a light field. The network represents spatial information using spatial kernels shared among all Sub-Aperture Images (SAIs), and angular information using sets of angular kernels for each SAI. To further improve the representation capability of the network without increasing parameter number, we also introduce angular kernel allocation and kernel tensor decomposition mechanisms. Extensive experiments demonstrate the benefits of information separation: when applied to the compression task, our network outperforms other state-of-the-art methods by a large margin. And angular information can be easily transferred to other scenes for rendering dense views, showing the successful separation and the potential use case for the view synthesis task. We plan to release the code upon acceptance of the paper to encourage further research on this topic.
Distilled Low Rank Neural Radiance Field with Quantization for Light Field Compression
Jul 30, 2022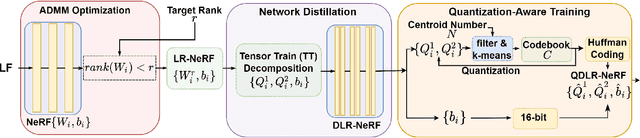


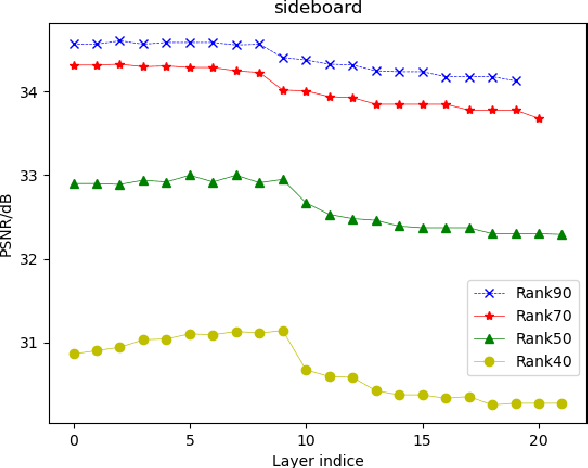
In this paper, we propose a novel light field compression method based on a Quantized Distilled Low Rank Neural Radiance Field (QDLR-NeRF) representation. While existing compression methods encode the set of light field sub-aperture images, our proposed method instead learns an implicit scene representation in the form of a Neural Radiance Field (NeRF), which also enables view synthesis. For reducing its size, the model is first learned under a Low Rank (LR) constraint using a Tensor Train (TT) decomposition in an Alternating Direction Method of Multipliers (ADMM) optimization framework. To further reduce the model size, the components of the tensor train decomposition need to be quantized. However, performing the optimization of the NeRF model by simultaneously taking the low rank constraint and the rate-constrained weight quantization into consideration is challenging. To deal with this difficulty, we introduce a network distillation operation that separates the low rank approximation and the weight quantization in the network training. The information from the initial LR constrained NeRF (LR-NeRF) is distilled to a model of a much smaller dimension (DLR-NeRF) based on the TT decomposition of the LR-NeRF. An optimized global codebook is then learned to quantize all TT components, producing the final QDLRNeRF. Experimental results show that our proposed method yields better compression efficiency compared with state-of-the-art methods, and it additionally has the advantage of allowing the synthesis of any light field view with a high quality.
Learned Gradient of a Regularizer for Plug-and-Play Gradient Descent
Apr 29, 2022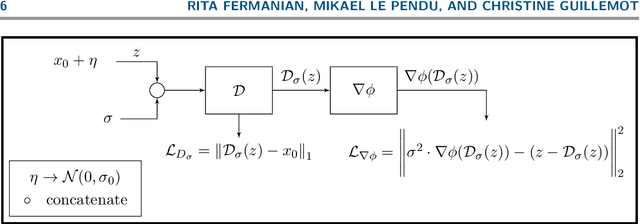
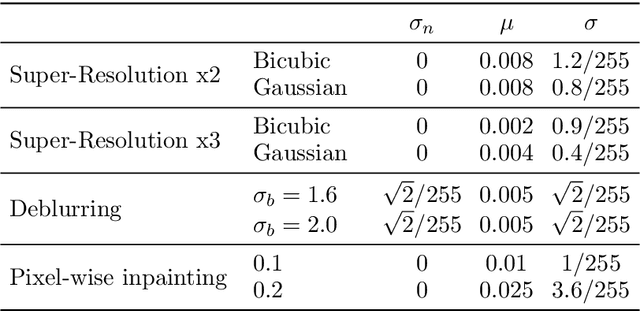
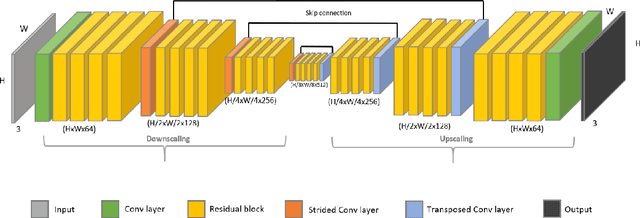

The Plug-and-Play (PnP) framework allows integrating advanced image denoising priors into optimization algorithms, to efficiently solve a variety of image restoration tasks. The Plug-and-Play alternating direction method of multipliers (ADMM) and the Regularization by Denoising (RED) algorithms are two examples of such methods that made a breakthrough in image restoration. However, while the former method only applies to proximal algorithms, it has recently been shown that there exists no regularization that explains the RED algorithm when the denoisers lack Jacobian symmetry, which happen to be the case of most practical denoisers. To the best of our knowledge, there exists no method for training a network that directly represents the gradient of a regularizer, which can be directly used in Plug-and-Play gradient-based algorithms. We show that it is possible to train a denoiser along with a network that corresponds to the gradient of its regularizer. We use this gradient of the regularizer in gradient-based optimization methods and obtain better results comparing to other generic Plug-and-Play approaches. We also show that the regularizer can be used as a pre-trained network for unrolled gradient descent. Lastly, we show that the resulting denoiser allows for a quick convergence of the Plug-and-Play ADMM.
Preconditioned Plug-and-Play ADMM with Locally Adjustable Denoiser for Image Restoration
Oct 01, 2021
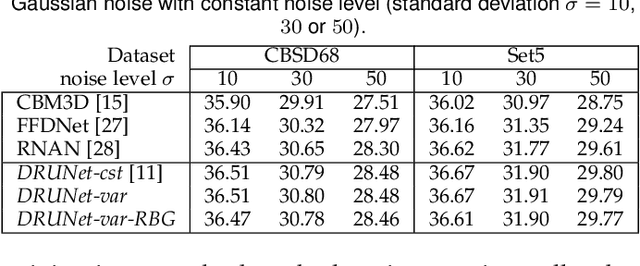
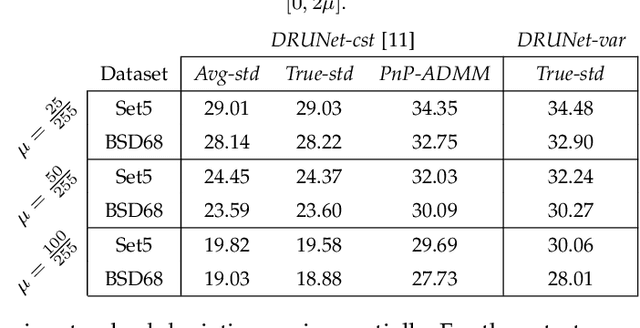
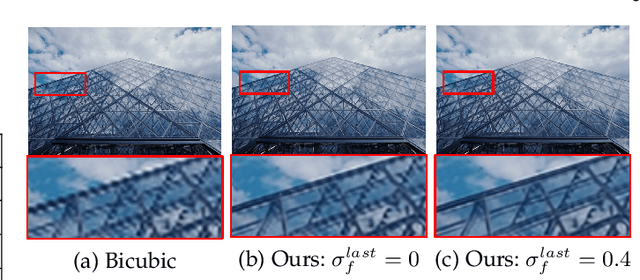
Plug-and-Play optimization recently emerged as a powerful technique for solving inverse problems by plugging a denoiser into a classical optimization algorithm. The denoiser accounts for the regularization and therefore implicitly determines the prior knowledge on the data, hence replacing typical handcrafted priors. In this paper, we extend the concept of plug-and-play optimization to use denoisers that can be parameterized for non-constant noise variance. In that aim, we introduce a preconditioning of the ADMM algorithm, which mathematically justifies the use of such an adjustable denoiser. We additionally propose a procedure for training a convolutional neural network for high quality non-blind image denoising that also allows for pixel-wise control of the noise standard deviation. We show that our pixel-wise adjustable denoiser, along with a suitable preconditioning strategy, can further improve the plug-and-play ADMM approach for several applications, including image completion, interpolation, demosaicing and Poisson denoising.
A learning-based view extrapolation method for axial super-resolution
Mar 11, 2021



Axial light field resolution refers to the ability to distinguish features at different depths by refocusing. The axial refocusing precision corresponds to the minimum distance in the axial direction between two distinguishable refocusing planes. High refocusing precision can be essential for some light field applications like microscopy. In this paper, we propose a learning-based method to extrapolate novel views from axial volumes of sheared epipolar plane images (EPIs). As extended numerical aperture (NA) in classical imaging, the extrapolated light field gives re-focused images with a shallower depth of field (DOF), leading to more accurate refocusing results. Most importantly, the proposed approach does not need accurate depth estimation. Experimental results with both synthetic and real light fields show that the method not only works well for light fields with small baselines as those captured by plenoptic cameras (especially for the plenoptic 1.0 cameras), but also applies to light fields with larger baselines.
A Lightweight Neural Network for Monocular View Generation with Occlusion Handling
Jul 24, 2020

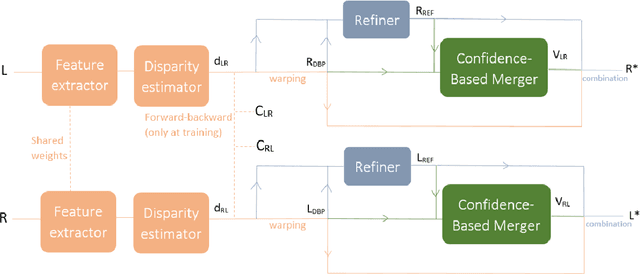

In this article, we present a very lightweight neural network architecture, trained on stereo data pairs, which performs view synthesis from one single image. With the growing success of multi-view formats, this problem is indeed increasingly relevant. The network returns a prediction built from disparity estimation, which fills in wrongly predicted regions using a occlusion handling technique. To do so, during training, the network learns to estimate the left-right consistency structural constraint on the pair of stereo input images, to be able to replicate it at test time from one single image. The method is built upon the idea of blending two predictions: a prediction based on disparity estimation, and a prediction based on direct minimization in occluded regions. The network is also able to identify these occluded areas at training and at test time by checking the pixelwise left-right consistency of the produced disparity maps. At test time, the approach can thus generate a left-side and a right-side view from one input image, as well as a depth map and a pixelwise confidence measure in the prediction. The work outperforms visually and metric-wise state-of-the-art approaches on the challenging KITTI dataset, all while reducing by a very significant order of magnitude (5 or 10 times) the required number of parameters (6.5 M).