 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilled Low Rank Neural Radiance Field with Quantization for Light Field Compression
Paper and Code
Jul 30, 2022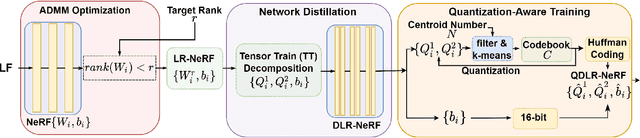


In this paper, we propose a novel light field compression method based on a Quantized Distilled Low Rank Neural Radiance Field (QDLR-NeRF) representation. While existing compression methods encode the set of light field sub-aperture images, our proposed method instead learns an implicit scene representation in the form of a Neural Radiance Field (NeRF), which also enables view synthesis. For reducing its size, the model is first learned under a Low Rank (LR) constraint using a Tensor Train (TT) decomposition in an Alternating Direction Method of Multipliers (ADMM) optimization framework. To further reduce the model size, the components of the tensor train decomposition need to be quantized. However, performing the optimization of the NeRF model by simultaneously taking the low rank constraint and the rate-constrained weight quantization into consideration is challenging. To deal with this difficulty, we introduce a network distillation operation that separates the low rank approximation and the weight quantization in the network training. The information from the initial LR constrained NeRF (LR-NeRF) is distilled to a model of a much smaller dimension (DLR-NeRF) based on the TT decomposition of the LR-NeRF. An optimized global codebook is then learned to quantize all TT components, producing the final QDLRNeRF. Experimental results show that our proposed method yields better compression efficiency compared with state-of-the-art methods, and it additionally has the advantage of allowing the synthesis of any light field view with a high quality.