 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Through the Rain: Resolving High-Frequency Conflicts in Deraining and Super-Resolution via Diffusion Guidance
Nov 16, 2025Clean images are crucial for visual tasks such as small object detection, especially at high resolutions. However, real-world images are often degraded by adverse weather, and weather restoration methods may sacrifice high-frequency details critical for analyzing small objects. A natural solution is to apply super-resolution (SR) after weather removal to recover both clarity and fine structures. However, simply cascading restoration and SR struggle to bridge their inherent conflict: removal aims to remove high-frequency weather-induced noise, while SR aims to hallucinate high-frequency textures from existing details, leading to inconsistent restoration contents. In this paper, we take deraining as a case study and propose DHGM, a Diffusion-based High-frequency Guided Model for generating clean and high-resolution images. DHGM integrates pre-trained diffusion priors with high-pass filters to simultaneously remove rain artifacts and enhance structural details. Extensive experiments demonstrate that DHGM achieves superior performance over existing methods, with lower costs.
Devil is in the Uniformity: Exploring Diverse Learners within Transformer for Image Restoration
Mar 26, 2025Transformer-based approaches have gained significant attention in image restoration, where the core component, i.e, Multi-Head Attention (MHA), plays a crucial role in capturing diverse features and recovering high-quality results. In MHA, heads perform attention calculation independently from uniform split subspaces, and a redundancy issue is triggered to hinder the model from achieving satisfactory outputs. In this paper, we propose to improve MHA by exploring diverse learners and introducing various interactions between heads, which results in a Hierarchical multI-head atteNtion driven Transformer model, termed HINT, for image restoration. HINT contains two modules, i.e., the Hierarchical Multi-Head Attention (HMHA) and the Query-Key Cache Updating (QKCU) module, to address the redundancy problem that is rooted in vanilla MHA. Specifically, HMHA extracts diverse contextual features by employing heads to learn from subspaces of varying sizes and containing different information. Moreover, QKCU, comprising intra- and inter-layer schemes, further reduces the redundancy problem by facilitating enhanced interactions between attention heads within and across layers. Extensive experiments are conducted on 12 benchmarks across 5 image restoration tasks, including low-light enhancement, dehazing, desnowing, denoising, and deraining, to demonstrate the superiority of HINT. The source code is available in the supplementary materials.
ICFRNet: Image Complexity Prior Guided Feature Refinement for Real-time Semantic Segmentation
Aug 25, 2024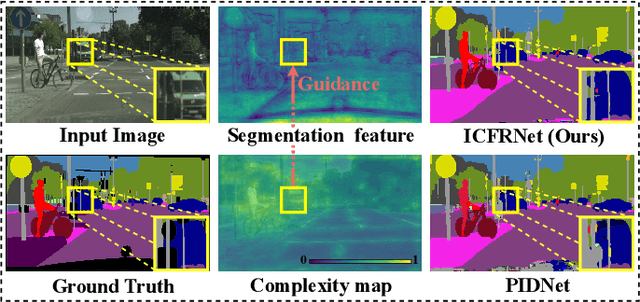
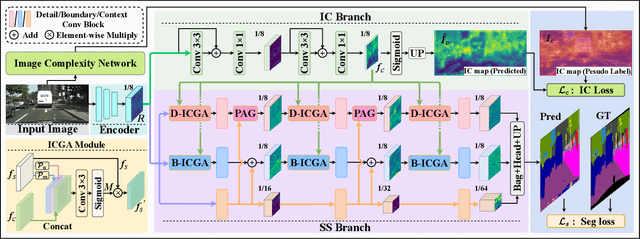
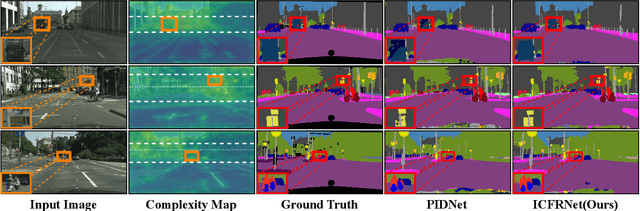
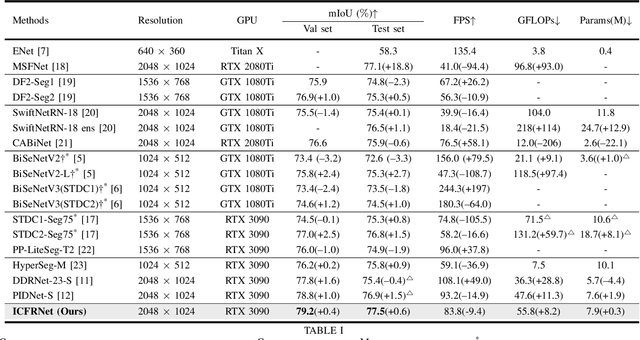
In this paper, we leverage image complexity as a prior for refining segmentation features to achieve accurate real-time semantic segmentation. The design philosophy is based on the observation that different pixel regions within an image exhibit varying levels of complexity, with higher complexities posing a greater challenge for accurate segmentation. We thus introduce image complexity as prior guidance and propose the Image Complexity prior-guided Feature Refinement Network (ICFRNet). This network aggregates both complexity and segmentation features to produce an attention map for refining segmentation features within an Image Complexity Guided Attention (ICGA) module. We optimize the network in terms of both segmentation and image complexity prediction tasks with a combined loss function. Experimental results on the Cityscapes and CamViD datasets have shown that our ICFRNet achieves higher accuracy with a competitive efficiency for real-time segmentation.
Harmonizing Light and Darkness: A Symphony of Prior-guided Data Synthesis and Adaptive Focus for Nighttime Flare Removal
Mar 30, 2024


Intense light sources often produce flares in captured images at night, which deteriorates the visual quality and negatively affects downstream applications. In order to train an effective flare removal network, a reliable dataset is essential. The mainstream flare removal datasets are semi-synthetic to reduce human labour, but these datasets do not cover typical scenarios involving multiple scattering flares. To tackle this issue, we synthesize a prior-guided dataset named Flare7K*, which contains multi-flare images where the brightness of flares adheres to the laws of illumination. Besides, flares tend to occupy localized regions of the image but existing networks perform flare removal on the entire image and sometimes modify clean areas incorrectly. Therefore, we propose a plug-and-play Adaptive Focus Module (AFM) that can adaptively mask the clean background areas and assist models in focusing on the regions severely affected by flares. Extensive experiments demonstrate that our data synthesis method can better simulate real-world scenes and several models equipped with AFM achieve state-of-the-art performance on the real-world test dataset.
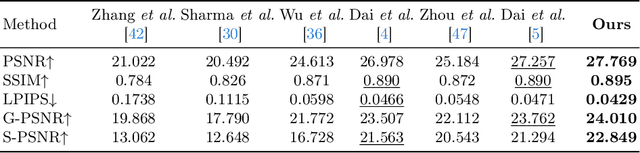
Seeing the Unseen: A Frequency Prompt Guided Transformer for Image Restoration
Mar 30, 2024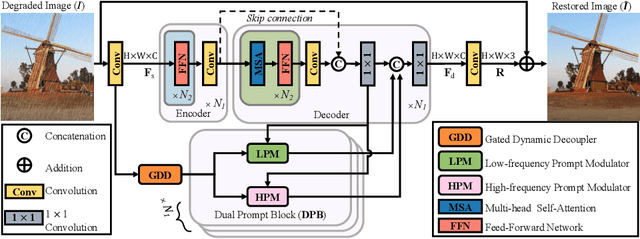
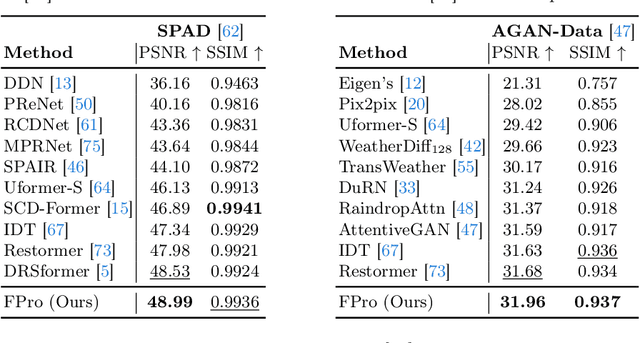
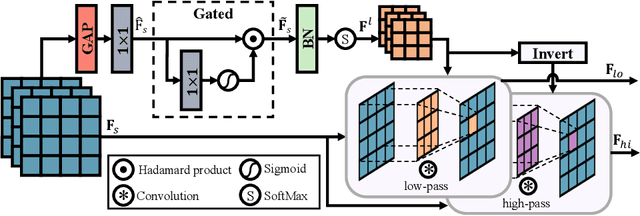
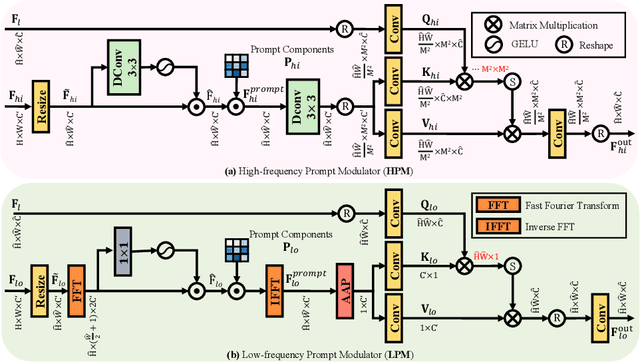
How to explore useful features from images as prompts to guide the deep image restoration models is an effective way to solve image restoration. In contrast to mining spatial relations within images as prompt, which leads to characteristics of different frequencies being neglected and further remaining subtle or undetectable artifacts in the restored image, we develop a Frequency Prompting image restoration method, dubbed FPro, which can effectively provide prompt components from a frequency perspective to guild the restoration model address these differences. Specifically, we first decompose input features into separate frequency parts via dynamically learned filters, where we introduce a gating mechanism for suppressing the less informative elements within the kernels. To propagate useful frequency information as prompt, we then propose a dual prompt block, consisting of a low-frequency prompt modulator (LPM) and a high-frequency prompt modulator (HPM), to handle signals from different bands respectively. Each modulator contains a generation process to incorporate prompting components into the extracted frequency maps, and a modulation part that modifies the prompt feature with the guidance of the decoder features. Experimental results on commonly used benchmarks have demonstrated the favorable performance of our pipeline against SOTA methods on 5 image restoration tasks, including deraining, deraindrop, demoir\'eing, deblurring, and dehazing. The source code and pre-trained models will be available at https://github.com/joshyZhou/FPro.
Spread Your Wings: A Radial Strip Transformer for Image Deblurring
Mar 30, 2024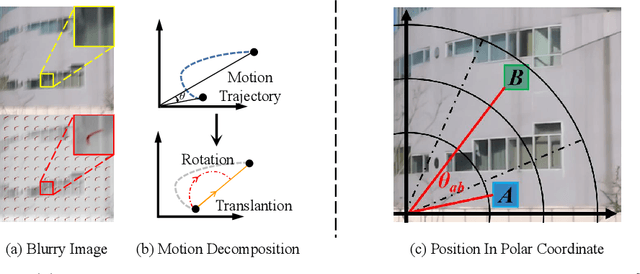
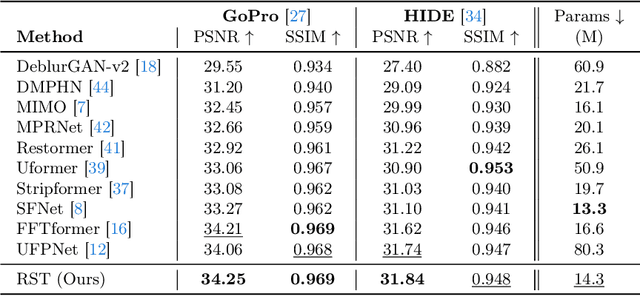
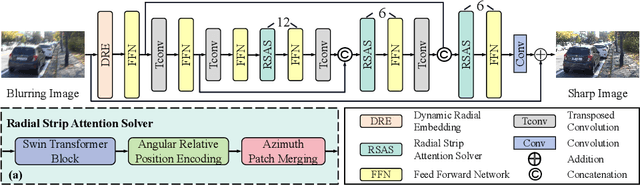
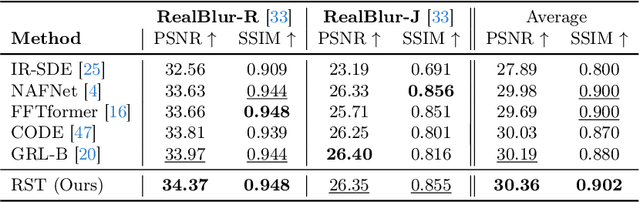
Exploring motion information is important for the motion deblurring task. Recent the window-based transformer approaches have achieved decent performance in image deblurring. Note that the motion causing blurry results is usually composed of translation and rotation movements and the window-shift operation in the Cartesian coordinate system by the window-based transformer approaches only directly explores translation motion in orthogonal directions. Thus, these methods have the limitation of modeling the rotation part. To alleviate this problem, we introduce the polar coordinate-based transformer, which has the angles and distance to explore rotation motion and translation information together. In this paper, we propose a Radial Strip Transformer (RST), which is a transformer-based architecture that restores the blur images in a polar coordinate system instead of a Cartesian one. RST contains a dynamic radial embedding module (DRE) to extract the shallow feature by a radial deformable convolution. We design a polar mask layer to generate the offsets for the deformable convolution, which can reshape the convolution kernel along the radius to better capture the rotation motion information. Furthermore, we proposed a radial strip attention solver (RSAS) as deep feature extraction, where the relationship of windows is organized by azimuth and radius. This attention module contains radial strip windows to reweight image features in the polar coordinate, which preserves more useful information in rotation and translation motion together for better recovering the sharp images. Experimental results on six synthesis and real-world datasets prove that our method performs favorably against other SOTA methods for the image deblurring task.
Learning Kernel-Modulated Neural Representation for Efficient Light Field Compression
Jul 12, 2023



Light field is a type of image data that captures the 3D scene information by recording light rays emitted from a scene at various orientations. It offers a more immersive perception than classic 2D images but at the cost of huge data volume. In this paper, we draw inspiration from the visual characteristics of Sub-Aperture Images (SAIs) of light field and design a compact neural network representation for the light field compression task. The network backbone takes randomly initialized noise as input and is supervised on the SAIs of the target light field. It is composed of two types of complementary kernels: descriptive kernels (descriptors) that store scene description information learned during training, and modulatory kernels (modulators) that control the rendering of different SAIs from the queried perspectives. To further enhance compactness of the network meanwhile retain high quality of the decoded light field, we accordingly introduce modulator allocation and kernel tensor decomposition mechanisms, followed by non-uniform quantization and lossless entropy coding techniques, to finally form an efficient compression pipeline. Extensive experiments demonstrate that our method outperforms other state-of-the-art (SOTA) methods by a significant margin in the light field compression task. Moreover, after aligning descriptors, the modulators learned from one light field can be transferred to new light fields for rendering dense views, indicating a potential solution for view synthesis task.
Learning-based Spatial and Angular Information Separation for Light Field Compression
Apr 13, 2023



Light fields are a type of image data that capture both spatial and angular scene information by recording light rays emitted by a scene from different orientations. In this context, spatial information is defined as features that remain static regardless of perspectives, while angular information refers to features that vary between viewpoints. We propose a novel neural network that, by design, can separate angular and spatial information of a light field. The network represents spatial information using spatial kernels shared among all Sub-Aperture Images (SAIs), and angular information using sets of angular kernels for each SAI. To further improve the representation capability of the network without increasing parameter number, we also introduce angular kernel allocation and kernel tensor decomposition mechanisms. Extensive experiments demonstrate the benefits of information separation: when applied to the compression task, our network outperforms other state-of-the-art methods by a large margin. And angular information can be easily transferred to other scenes for rendering dense views, showing the successful separation and the potential use case for the view synthesis task. We plan to release the code upon acceptance of the paper to encourage further research on this topic.
JAWS: Just A Wild Shot for Cinematic Transfer in Neural Radiance Fields
Mar 27, 2023



This paper presents JAWS, an optimization-driven approach that achieves the robust transfer of visual cinematic features from a reference in-the-wild video clip to a newly generated clip. To this end, we rely on an implicit-neural-representation (INR) in a way to compute a clip that shares the same cinematic features as the reference clip. We propose a general formulation of a camera optimization problem in an INR that computes extrinsic and intrinsic camera parameters as well as timing. By leveraging the differentiability of neural representations, we can back-propagate our designed cinematic losses measured on proxy estimators through a NeRF network to the proposed cinematic parameters directly. We also introduce specific enhancements such as guidance maps to improve the overall quality and efficiency. Results display the capacity of our system to replicate well known camera sequences from movies, adapting the framing, camera parameters and timing of the generated video clip to maximize the similarity with the reference clip.
Distilled Low Rank Neural Radiance Field with Quantization for Light Field Compression
Jul 30, 2022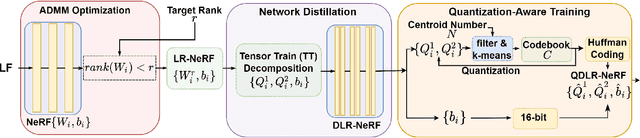


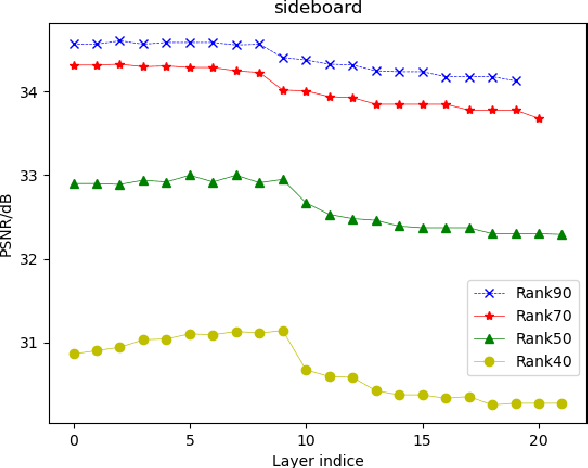
In this paper, we propose a novel light field compression method based on a Quantized Distilled Low Rank Neural Radiance Field (QDLR-NeRF) representation. While existing compression methods encode the set of light field sub-aperture images, our proposed method instead learns an implicit scene representation in the form of a Neural Radiance Field (NeRF), which also enables view synthesis. For reducing its size, the model is first learned under a Low Rank (LR) constraint using a Tensor Train (TT) decomposition in an Alternating Direction Method of Multipliers (ADMM) optimization framework. To further reduce the model size, the components of the tensor train decomposition need to be quantized. However, performing the optimization of the NeRF model by simultaneously taking the low rank constraint and the rate-constrained weight quantization into consideration is challenging. To deal with this difficulty, we introduce a network distillation operation that separates the low rank approximation and the weight quantization in the network training. The information from the initial LR constrained NeRF (LR-NeRF) is distilled to a model of a much smaller dimension (DLR-NeRF) based on the TT decomposition of the LR-NeRF. An optimized global codebook is then learned to quantize all TT components, producing the final QDLRNeRF. Experimental results show that our proposed method yields better compression efficiency compared with state-of-the-art methods, and it additionally has the advantage of allowing the synthesis of any light field view with a high quality.