 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt Takes Two: A Duet of Periodicity and Directionality for Burst Flicker Removal
Mar 24, 2026Flicker artifacts, arising from unstable illumination and row-wise exposure inconsistencies, pose a significant challenge in short-exposure photography, severely degrading image quality. Unlike typical artifacts, e.g., noise and low-light, flicker is a structured degradation with specific spatial-temporal patterns, which are not accounted for in current generic restoration frameworks, leading to suboptimal flicker suppression and ghosting artifacts. In this work, we reveal that flicker artifacts exhibit two intrinsic characteristics, periodicity and directionality, and propose Flickerformer, a transformer-based architecture that effectively removes flicker without introducing ghosting. Specifically, Flickerformer comprises three key components: a phase-based fusion module (PFM), an autocorrelation feed-forward network (AFFN), and a wavelet-based directional attention module (WDAM). Based on the periodicity, PFM performs inter-frame phase correlation to adaptively aggregate burst features, while AFFN exploits intra-frame structural regularities through autocorrelation, jointly enhancing the network's ability to perceive spatially recurring patterns. Moreover, motivated by the directionality of flicker artifacts, WDAM leverages high-frequency variations in the wavelet domain to guide the restoration of low-frequency dark regions, yielding precise localization of flicker artifacts. Extensive experiments demonstrate that Flickerformer outperforms state-of-the-art approaches in both quantitative metrics and visual quality. The source code is available at https://github.com/qulishen/Flickerformer.
Translating Informal Proofs into Formal Proofs Using a Chain of States
Dec 12, 2025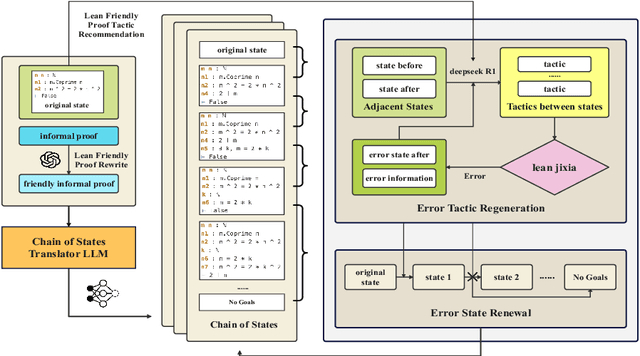
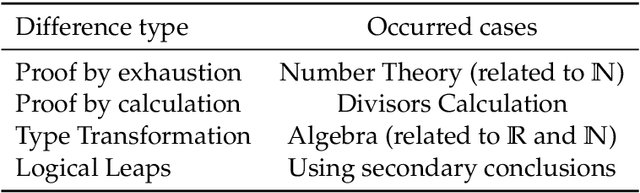

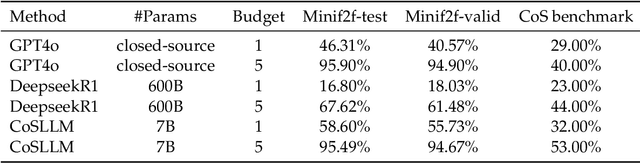
We address the problem of translating informal mathematical proofs expressed in natural language into formal proofs in Lean4 under a constrained computational budget. Our approach is grounded in two key insights. First, informal proofs tend to proceed via a sequence of logical transitions - often implications or equivalences - without explicitly specifying intermediate results or auxiliary lemmas. In contrast, formal systems like Lean require an explicit representation of each proof state and the tactics that connect them. Second, each informal reasoning step can be viewed as an abstract transformation between proof states, but identifying the corresponding formal tactics often requires nontrivial domain knowledge and precise control over proof context. To bridge this gap, we propose a two stage framework. Rather than generating formal tactics directly, we first extract a Chain of States (CoS), a sequence of intermediate formal proof states aligned with the logical structure of the informal argument. We then generate tactics to transition between adjacent states in the CoS, thereby constructing the full formal proof. This intermediate representation significantly reduces the complexity of tactic generation and improves alignment with informal reasoning patterns. We build dedicated datasets and benchmarks for training and evaluation, and introduce an interactive framework to support tactic generation from formal states. Empirical results show that our method substantially outperforms existing baselines, achieving higher proof success rates.
Devil is in the Uniformity: Exploring Diverse Learners within Transformer for Image Restoration
Mar 26, 2025Transformer-based approaches have gained significant attention in image restoration, where the core component, i.e, Multi-Head Attention (MHA), plays a crucial role in capturing diverse features and recovering high-quality results. In MHA, heads perform attention calculation independently from uniform split subspaces, and a redundancy issue is triggered to hinder the model from achieving satisfactory outputs. In this paper, we propose to improve MHA by exploring diverse learners and introducing various interactions between heads, which results in a Hierarchical multI-head atteNtion driven Transformer model, termed HINT, for image restoration. HINT contains two modules, i.e., the Hierarchical Multi-Head Attention (HMHA) and the Query-Key Cache Updating (QKCU) module, to address the redundancy problem that is rooted in vanilla MHA. Specifically, HMHA extracts diverse contextual features by employing heads to learn from subspaces of varying sizes and containing different information. Moreover, QKCU, comprising intra- and inter-layer schemes, further reduces the redundancy problem by facilitating enhanced interactions between attention heads within and across layers. Extensive experiments are conducted on 12 benchmarks across 5 image restoration tasks, including low-light enhancement, dehazing, desnowing, denoising, and deraining, to demonstrate the superiority of HINT. The source code is available in the supplementary materials.
Spread Your Wings: A Radial Strip Transformer for Image Deblurring
Mar 30, 2024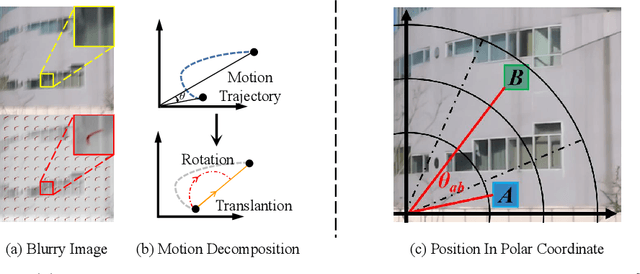
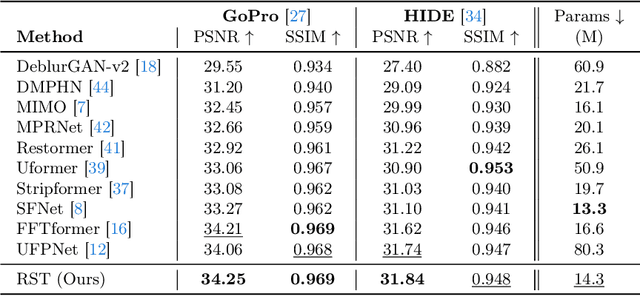
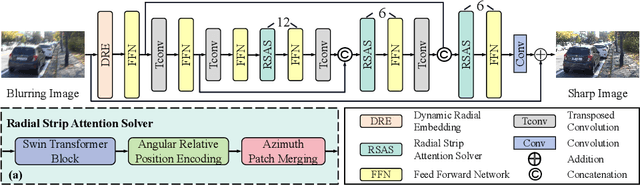
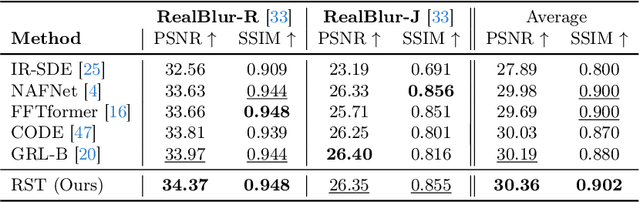
Exploring motion information is important for the motion deblurring task. Recent the window-based transformer approaches have achieved decent performance in image deblurring. Note that the motion causing blurry results is usually composed of translation and rotation movements and the window-shift operation in the Cartesian coordinate system by the window-based transformer approaches only directly explores translation motion in orthogonal directions. Thus, these methods have the limitation of modeling the rotation part. To alleviate this problem, we introduce the polar coordinate-based transformer, which has the angles and distance to explore rotation motion and translation information together. In this paper, we propose a Radial Strip Transformer (RST), which is a transformer-based architecture that restores the blur images in a polar coordinate system instead of a Cartesian one. RST contains a dynamic radial embedding module (DRE) to extract the shallow feature by a radial deformable convolution. We design a polar mask layer to generate the offsets for the deformable convolution, which can reshape the convolution kernel along the radius to better capture the rotation motion information. Furthermore, we proposed a radial strip attention solver (RSAS) as deep feature extraction, where the relationship of windows is organized by azimuth and radius. This attention module contains radial strip windows to reweight image features in the polar coordinate, which preserves more useful information in rotation and translation motion together for better recovering the sharp images. Experimental results on six synthesis and real-world datasets prove that our method performs favorably against other SOTA methods for the image deblurring task.
Seeing the Unseen: A Frequency Prompt Guided Transformer for Image Restoration
Mar 30, 2024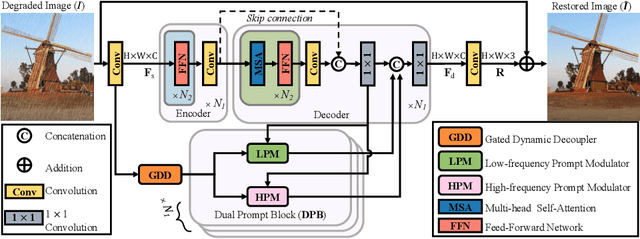
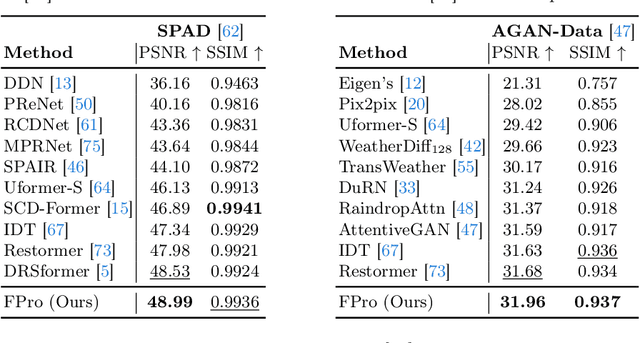
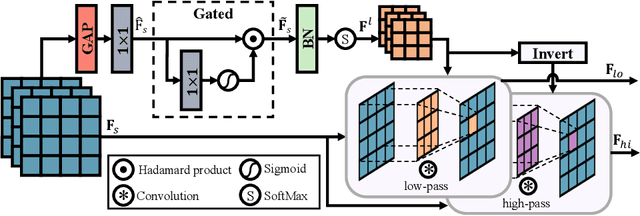
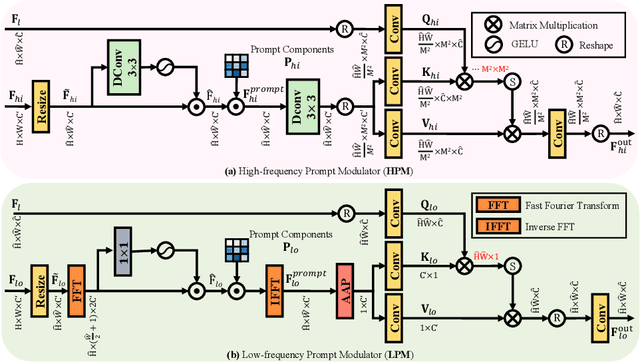
How to explore useful features from images as prompts to guide the deep image restoration models is an effective way to solve image restoration. In contrast to mining spatial relations within images as prompt, which leads to characteristics of different frequencies being neglected and further remaining subtle or undetectable artifacts in the restored image, we develop a Frequency Prompting image restoration method, dubbed FPro, which can effectively provide prompt components from a frequency perspective to guild the restoration model address these differences. Specifically, we first decompose input features into separate frequency parts via dynamically learned filters, where we introduce a gating mechanism for suppressing the less informative elements within the kernels. To propagate useful frequency information as prompt, we then propose a dual prompt block, consisting of a low-frequency prompt modulator (LPM) and a high-frequency prompt modulator (HPM), to handle signals from different bands respectively. Each modulator contains a generation process to incorporate prompting components into the extracted frequency maps, and a modulation part that modifies the prompt feature with the guidance of the decoder features. Experimental results on commonly used benchmarks have demonstrated the favorable performance of our pipeline against SOTA methods on 5 image restoration tasks, including deraining, deraindrop, demoir\'eing, deblurring, and dehazing. The source code and pre-trained models will be available at https://github.com/joshyZhou/FPro.
Look-Around Before You Leap: High-Frequency Injected Transformer for Image Restoration
Mar 30, 2024
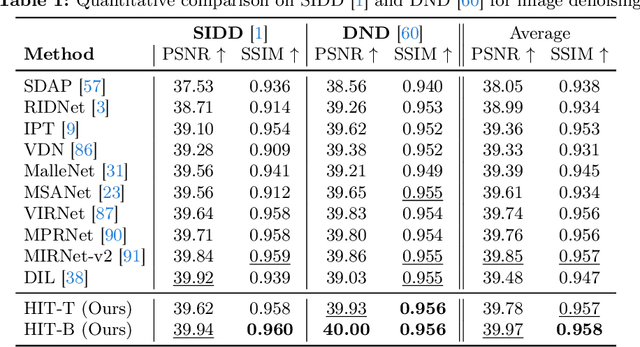
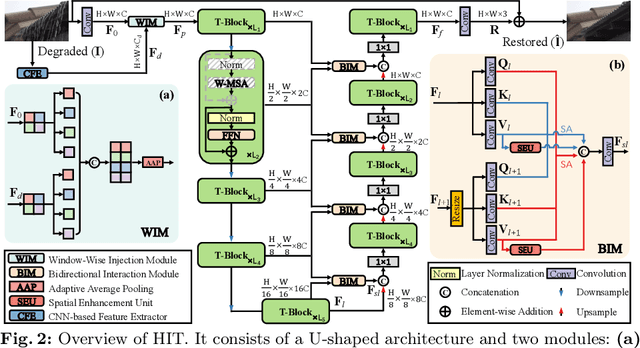
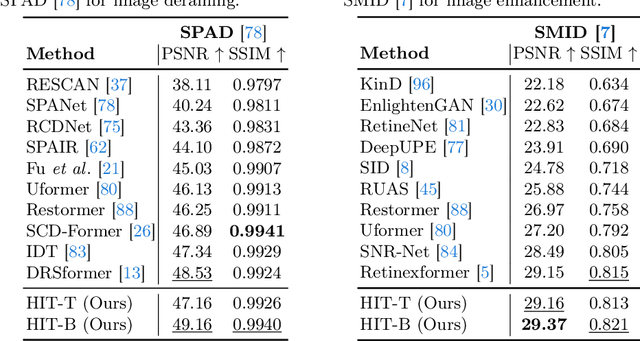
Transformer-based approaches have achieved superior performance in image restoration, since they can model long-term dependencies well. However, the limitation in capturing local information restricts their capacity to remove degradations. While existing approaches attempt to mitigate this issue by incorporating convolutional operations, the core component in Transformer, i.e., self-attention, which serves as a low-pass filter, could unintentionally dilute or even eliminate the acquired local patterns. In this paper, we propose HIT, a simple yet effective High-frequency Injected Transformer for image restoration. Specifically, we design a window-wise injection module (WIM), which incorporates abundant high-frequency details into the feature map, to provide reliable references for restoring high-quality images. We also develop a bidirectional interaction module (BIM) to aggregate features at different scales using a mutually reinforced paradigm, resulting in spatially and contextually improved representations. In addition, we introduce a spatial enhancement unit (SEU) to preserve essential spatial relationships that may be lost due to the computations carried out across channel dimensions in the BIM. Extensive experiments on 9 tasks (real noise, real rain streak, raindrop, motion blur, moir\'e, shadow, snow, haze, and low-light condition) demonstrate that HIT with linear computational complexity performs favorably against the state-of-the-art methods. The source code and pre-trained models will be available at https://github.com/joshyZhou/HIT.
Harmonizing Light and Darkness: A Symphony of Prior-guided Data Synthesis and Adaptive Focus for Nighttime Flare Removal
Mar 30, 2024
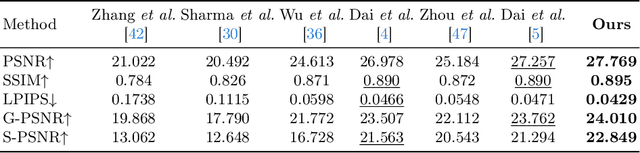


Intense light sources often produce flares in captured images at night, which deteriorates the visual quality and negatively affects downstream applications. In order to train an effective flare removal network, a reliable dataset is essential. The mainstream flare removal datasets are semi-synthetic to reduce human labour, but these datasets do not cover typical scenarios involving multiple scattering flares. To tackle this issue, we synthesize a prior-guided dataset named Flare7K*, which contains multi-flare images where the brightness of flares adheres to the laws of illumination. Besides, flares tend to occupy localized regions of the image but existing networks perform flare removal on the entire image and sometimes modify clean areas incorrectly. Therefore, we propose a plug-and-play Adaptive Focus Module (AFM) that can adaptively mask the clean background areas and assist models in focusing on the regions severely affected by flares. Extensive experiments demonstrate that our data synthesis method can better simulate real-world scenes and several models equipped with AFM achieve state-of-the-art performance on the real-world test dataset.
Benchmarks and Challenges in Pose Estimation for Egocentric Hand Interactions with Objects
Mar 25, 2024
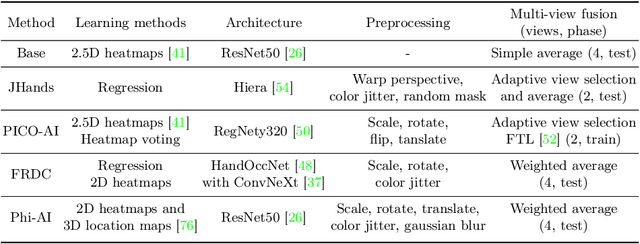
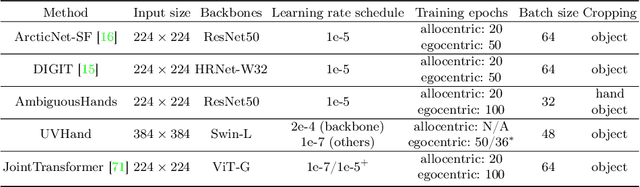
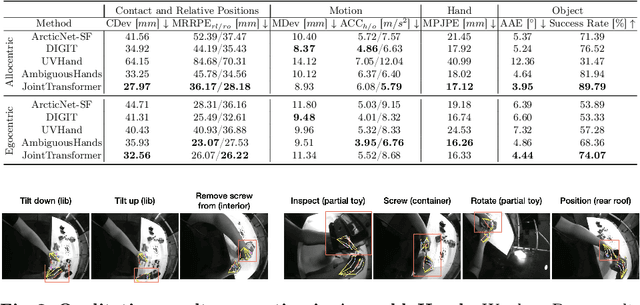
We interact with the world with our hands and see it through our own (egocentric) perspective. A holistic 3D understanding of such interactions from egocentric views is important for tasks in robotics, AR/VR, action recognition and motion generation. Accurately reconstructing such interactions in 3D is challenging due to heavy occlusion, viewpoint bias, camera distortion, and motion blur from the head movement. To this end, we designed the HANDS23 challenge based on the AssemblyHands and ARCTIC datasets with carefully designed training and testing splits. Based on the results of the top submitted methods and more recent baselines on the leaderboards, we perform a thorough analysis on 3D hand(-object) reconstruction tasks. Our analysis demonstrates the effectiveness of addressing distortion specific to egocentric cameras, adopting high-capacity transformers to learn complex hand-object interactions, and fusing predictions from different views. Our study further reveals challenging scenarios intractable with state-of-the-art methods, such as fast hand motion, object reconstruction from narrow egocentric views, and close contact between two hands and objects. Our efforts will enrich the community's knowledge foundation and facilitate future hand studies on egocentric hand-object interactions.
1st Place Solution of Egocentric 3D Hand Pose Estimation Challenge 2023 Technical Report:A Concise Pipeline for Egocentric Hand Pose Reconstruction
Oct 10, 2023

This report introduce our work on Egocentric 3D Hand Pose Estimation workshop. Using AssemblyHands, this challenge focuses on egocentric 3D hand pose estimation from a single-view image. In the competition, we adopt ViT based backbones and a simple regressor for 3D keypoints prediction, which provides strong model baselines. We noticed that Hand-objects occlusions and self-occlusions lead to performance degradation, thus proposed a non-model method to merge multi-view results in the post-process stage. Moreover, We utilized test time augmentation and model ensemble to make further improvement. We also found that public dataset and rational preprocess are beneficial. Our method achieved 12.21mm MPJPE on test dataset, achieve the first place in Egocentric 3D Hand Pose Estimation challenge.
Dynamic MLP for Fine-Grained Image Classification by Leveraging Geographical and Temporal Information
Mar 07, 2022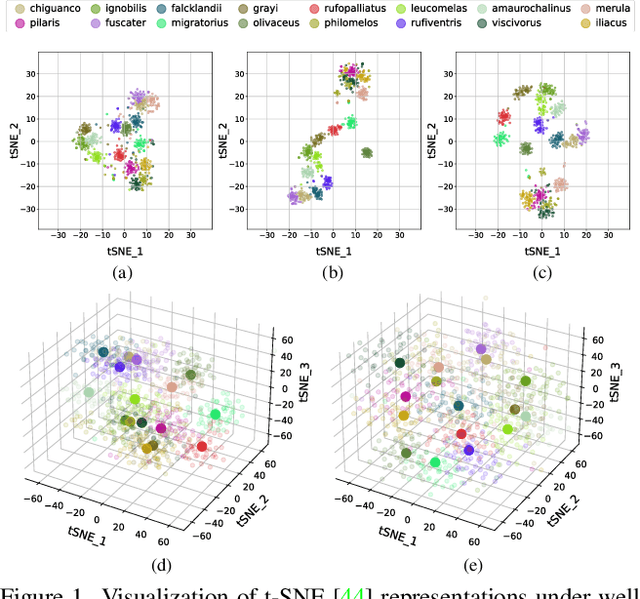
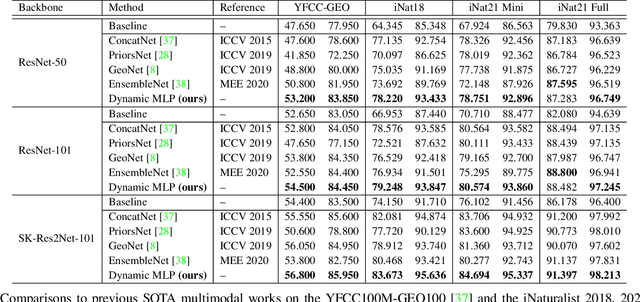
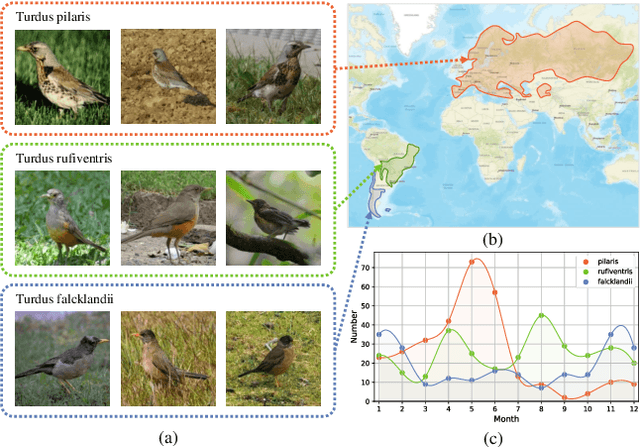
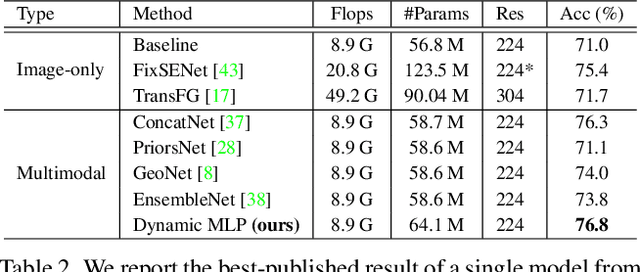
Fine-grained image classification is a challenging computer vision task where various species share similar visual appearances, resulting in misclassification if merely based on visual clues. Therefore, it is helpful to leverage additional information, e.g., the locations and dates for data shooting, which can be easily accessible but rarely exploited. In this paper, we first demonstrate that existing multimodal methods fuse multiple features only on a single dimension, which essentially has insufficient help in feature discrimination. To fully explore the potential of multimodal information, we propose a dynamic MLP on top of the image representation, which interacts with multimodal features at a higher and broader dimension. The dynamic MLP is an efficient structure parameterized by the learned embeddings of variable locations and dates. It can be regarded as an adaptive nonlinear projection for generating more discriminative image representations in visual tasks. To our best knowledge, it is the first attempt to explore the idea of dynamic networks to exploit multimodal information in fine-grained image classification tasks. Extensive experiments demonstrate the effectiveness of our method. The t-SNE algorithm visually indicates that our technique improves the recognizability of image representations that are visually similar but with different categories. Furthermore, among published works across multiple fine-grained datasets, dynamic MLP consistently achieves SOTA results https://paperswithcode.com/dataset/inaturalist and takes third place in the iNaturalist challenge at FGVC8 https://www.kaggle.com/c/inaturalist-2021/leaderboard. Code is available at https://github.com/ylingfeng/DynamicMLP.git