 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hierarchically Feature Reconstructed Autoencoder for Unsupervised Anomaly Detection
May 15, 2024Anomaly detection and localization without any manual annotations and prior knowledge is a challenging task under the setting of unsupervised learning. The existing works achieve excellent performance in the anomaly detection, but with complex networks or cumbersome pipelines. To address this issue, this paper explores a simple but effective architecture in the anomaly detection. It consists of a well pre-trained encoder to extract hierarchical feature representations and a decoder to reconstruct these intermediate features from the encoder. In particular, it does not require any data augmentations and anomalous images for training. The anomalies can be detected when the decoder fails to reconstruct features well, and then errors of hierarchical feature reconstruction are aggregated into an anomaly map to achieve anomaly localization. The difference comparison between those features of encoder and decode lead to more accurate and robust localization results than the comparison in single feature or pixel-by-pixel comparison in the conventional works. Experiment results show that the proposed method outperforms the state-of-the-art methods on MNIST, Fashion-MNIST, CIFAR-10, and MVTec Anomaly Detection datasets on both anomaly detection and localization.
DC-GNet: Deep Mesh Relation Capturing Graph Convolution Network for 3D Human Shape Reconstruction
Aug 27, 2021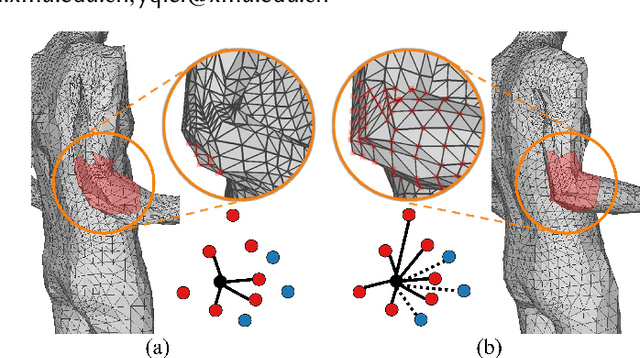
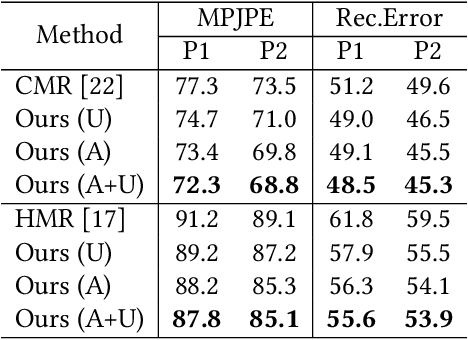
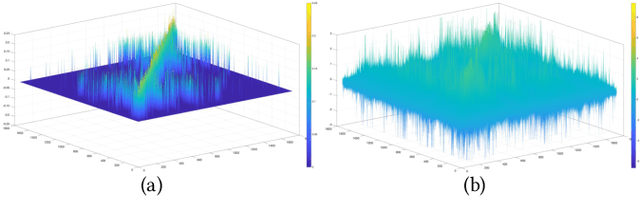
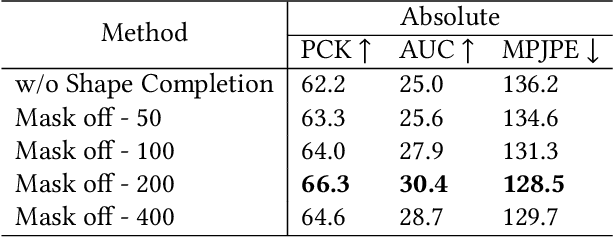
In this paper, we aim to reconstruct a full 3D human shape from a single image. Previous vertex-level and parameter regression approaches reconstruct 3D human shape based on a pre-defined adjacency matrix to encode positive relations between nodes. The deep topological relations for the surface of the 3D human body are not carefully exploited. Moreover, the performance of most existing approaches often suffer from domain gap when handling more occlusion cases in real-world scenes. In this work, we propose a Deep Mesh Relation Capturing Graph Convolution Network, DC-GNet, with a shape completion task for 3D human shape reconstruction. Firstly, we propose to capture deep relations within mesh vertices, where an adaptive matrix encoding both positive and negative relations is introduced. Secondly, we propose a shape completion task to learn prior about various kinds of occlusion cases. Our approach encodes mesh structure from more subtle relations between nodes in a more distant region. Furthermore, our shape completion module alleviates the performance degradation issue in the outdoor scene. Extensive experiments on several benchmarks show that our approach outperforms the previous 3D human pose and shape estimation approaches.
Joint Representation of Multiple Geometric Priors via a Shape Decomposition Model for Single Monocular 3D Pose Estimation
May 31, 2019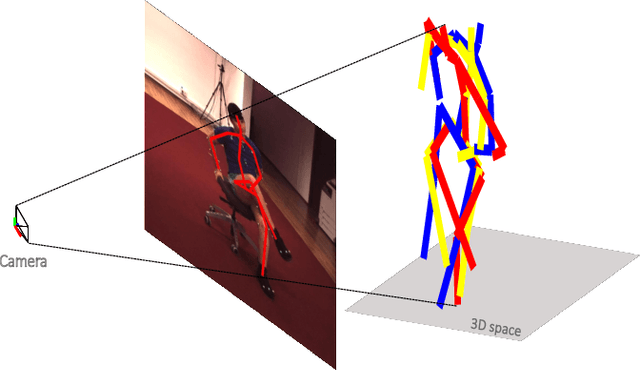
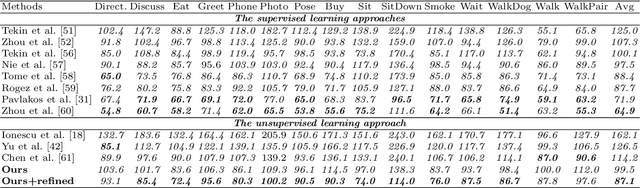
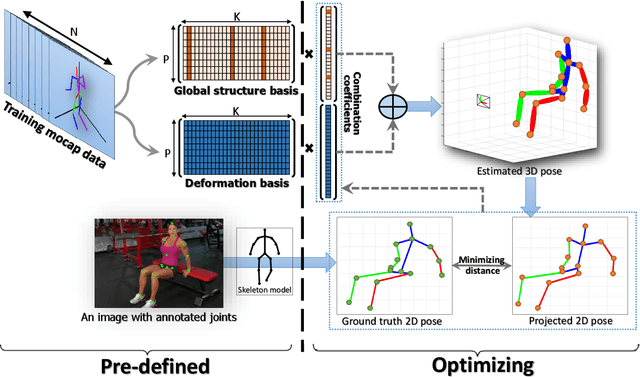
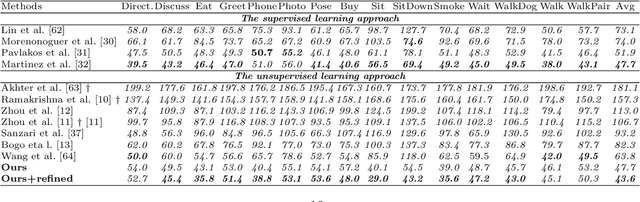
In this paper, we aim to recover the 3D human pose from 2D body joints of a single image. The major challenge in this task is the depth ambiguity since different 3D poses may produce similar 2D poses. Although many recent advances in this problem are found in both unsupervised and supervised learning approaches, the performances of most of these approaches are greatly affected by insufficient diversities and richness of training data. To alleviate this issue, we propose an unsupervised learning approach, which is capable of estimating various complex poses well under limited available training data. Specifically, we propose a Shape Decomposition Model (SDM) in which a 3D pose is considered as the superposition of two parts which are global structure together with some deformations. Based on SDM, we estimate these two parts explicitly by solving two sets of different distributed combination coefficients of geometric priors. In addition, to obtain geometric priors, a joint dictionary learning algorithm is proposed to extract both coarse and fine pose clues simultaneously from limited training data. Quantitative evaluations on several widely used datasets demonstrate that our approach yields better performances over other competitive approaches. Especially, on some categories with more complex deformations, significant improvements are achieved by our approach. Furthermore, qualitative experiments conducted on in-the-wild images also show the effectiveness of the proposed approach.