 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing User-Oriented Proactivity in Open-Domain Dialogues with Critic Guidance
May 18, 2025
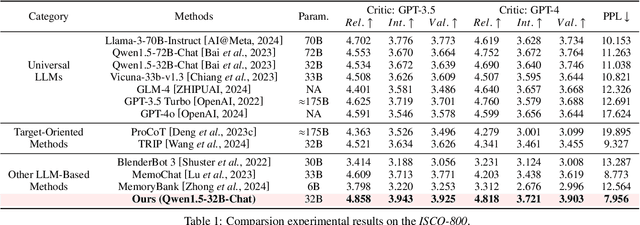
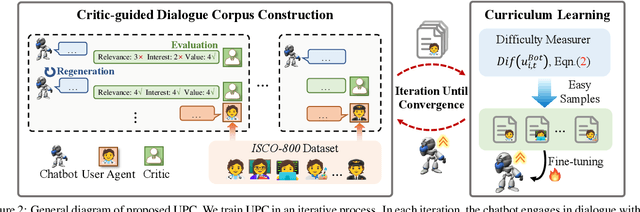

Open-domain dialogue systems aim to generate natural and engaging conversations, providing significant practical value in real applications such as social robotics and personal assistants. The advent of large language models (LLMs) has greatly advanced this field by improving context understanding and conversational fluency. However, existing LLM-based dialogue systems often fall short in proactively understanding the user's chatting preferences and guiding conversations toward user-centered topics. This lack of user-oriented proactivity can lead users to feel unappreciated, reducing their satisfaction and willingness to continue the conversation in human-computer interactions. To address this issue, we propose a User-oriented Proactive Chatbot (UPC) to enhance the user-oriented proactivity. Specifically, we first construct a critic to evaluate this proactivity inspired by the LLM-as-a-judge strategy. Given the scarcity of high-quality training data, we then employ the critic to guide dialogues between the chatbot and user agents, generating a corpus with enhanced user-oriented proactivity. To ensure the diversity of the user backgrounds, we introduce the ISCO-800, a diverse user background dataset for constructing user agents. Moreover, considering the communication difficulty varies among users, we propose an iterative curriculum learning method that trains the chatbot from easy-to-communicate users to more challenging ones, thereby gradually enhancing its performance. Experiments demonstrate that our proposed training method is applicable to different LLMs, improving user-oriented proactivity and attractiveness in open-domain dialogues.
Integrating Biological and Machine Intelligence: Attention Mechanisms in Brain-Computer Interfaces
Feb 26, 2025With the rapid advancement of deep learning, attention mechanisms have become indispensable in electroencephalography (EEG) signal analysis, significantly enhancing Brain-Computer Interface (BCI) applications. This paper presents a comprehensive review of traditional and Transformer-based attention mechanisms, their embedding strategies, and their applications in EEG-based BCI, with a particular emphasis on multimodal data fusion. By capturing EEG variations across time, frequency, and spatial channels, attention mechanisms improve feature extraction, representation learning, and model robustness. These methods can be broadly categorized into traditional attention mechanisms, which typically integrate with convolutional and recurrent networks, and Transformer-based multi-head self-attention, which excels in capturing long-range dependencies. Beyond single-modality analysis, attention mechanisms also enhance multimodal EEG applications, facilitating effective fusion between EEG and other physiological or sensory data. Finally, we discuss existing challenges and emerging trends in attention-based EEG modeling, highlighting future directions for advancing BCI technology. This review aims to provide valuable insights for researchers seeking to leverage attention mechanisms for improved EEG interpretation and application.
A Cross-Scene Benchmark for Open-World Drone Active Tracking
Dec 01, 2024Drone Visual Active Tracking aims to autonomously follow a target object by controlling the motion system based on visual observations, providing a more practical solution for effective tracking in dynamic environments. However, accurate Drone Visual Active Tracking using reinforcement learning remains challenging due to the absence of a unified benchmark, the complexity of open-world environments with frequent interference, and the diverse motion behavior of dynamic targets. To address these issues, we propose a unified cross-scene cross-domain benchmark for open-world drone active tracking called DAT. The DAT benchmark provides 24 visually complex environments to assess the algorithms' cross-scene and cross-domain generalization abilities, and high-fidelity modeling of realistic robot dynamics. Additionally, we propose a reinforcement learning-based drone tracking method called R-VAT, which aims to improve the performance of drone tracking targets in complex scenarios. Specifically, inspired by curriculum learning, we introduce a Curriculum-Based Training strategy that progressively enhances the agent tracking performance in vast environments with complex interference. We design a goal-centered reward function to provide precise feedback to the drone agent, preventing targets farther from the center of view from receiving higher rewards than closer ones. This allows the drone to adapt to the diverse motion behavior of open-world targets. Experiments demonstrate that the R-VAT has about 400% improvement over the SOTA method in terms of the cumulative reward metric.
MDDD: Manifold-based Domain Adaptation with Dynamic Distribution for Non-Deep Transfer Learning in Cross-subject and Cross-session EEG-based Emotion Recognition
Apr 24, 2024Emotion decoding using Electroencephalography (EEG)-based affective brain-computer interfaces represents a significant area within the field of affective computing. In the present study, we propose a novel non-deep transfer learning method, termed as Manifold-based Domain adaptation with Dynamic Distribution (MDDD). The proposed MDDD includes four main modules: manifold feature transformation, dynamic distribution alignment, classifier learning, and ensemble learning. The data undergoes a transformation onto an optimal Grassmann manifold space, enabling dynamic alignment of the source and target domains. This process prioritizes both marginal and conditional distributions according to their significance, ensuring enhanced adaptation efficiency across various types of data. In the classifier learning, the principle of structural risk minimization is integrated to develop robust classification models. This is complemented by dynamic distribution alignment, which refines the classifier iteratively. Additionally, the ensemble learning module aggregates the classifiers obtained at different stages of the optimization process, which leverages the diversity of the classifiers to enhance the overall prediction accuracy. The experimental results indicate that MDDD outperforms traditional non-deep learning methods, achieving an average improvement of 3.54%, and is comparable to deep learning methods. This suggests that MDDD could be a promising method for enhancing the utility and applicability of aBCIs in real-world scenarios.
Disentangling Writer and Character Styles for Handwriting Generation
Mar 31, 2023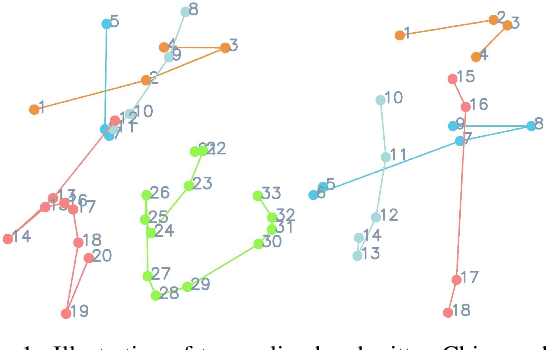



Training machines to synthesize diverse handwritings is an intriguing task. Recently, RNN-based methods have been proposed to generate stylized online Chinese characters. However, these methods mainly focus on capturing a person's overall writing style, neglecting subtle style inconsistencies between characters written by the same person. For example, while a person's handwriting typically exhibits general uniformity (e.g., glyph slant and aspect ratios), there are still small style variations in finer details (e.g., stroke length and curvature) of characters. In light of this, we propose to disentangle the style representations at both writer and character levels from individual handwritings to synthesize realistic stylized online handwritten characters. Specifically, we present the style-disentangled Transformer (SDT), which employs two complementary contrastive objectives to extract the style commonalities of reference samples and capture the detailed style patterns of each sample, respectively. Extensive experiments on various language scripts demonstrate the effectiveness of SDT. Notably, our empirical findings reveal that the two learned style representations provide information at different frequency magnitudes, underscoring the importance of separate style extraction. Our source code is public at: https://github.com/dailenson/SDT.
Cross-Correlation Based Discriminant Criterion for Channel Selection in Motor Imagery BCI Systems
Jan 08, 2021Many electroencephalogram (EEG)-based brain-computer interface (BCI) systems use a large amount of channels for higher performance, which is time-consuming to set up and inconvenient for practical applications. Finding an optimal subset of channels without compromising the performance is a necessary and challenging task. In this article, we proposed a cross-correlation based discriminant criterion (XCDC) which assesses the importance of a channel for discriminating the mental states of different motor imagery (MI) tasks. The performance of XCDC is evaluated on two motor imagery EEG datasets. In both datasets, XCDC significantly reduces the amount of channels without compromising classification accuracy compared to the all-channel setups. Under the same constraint of accuracy, the proposed method requires fewer channels than existing channel selection methods based on Pearson's correlation coefficient and common spatial pattern. Visualization of XCDC shows consistent results with neurophysiological principles.
Joint Representation of Multiple Geometric Priors via a Shape Decomposition Model for Single Monocular 3D Pose Estimation
May 31, 2019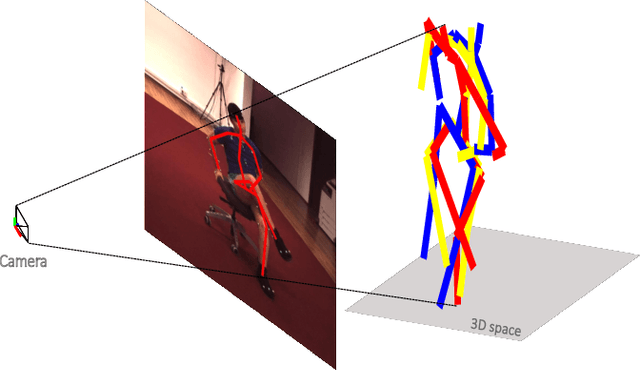
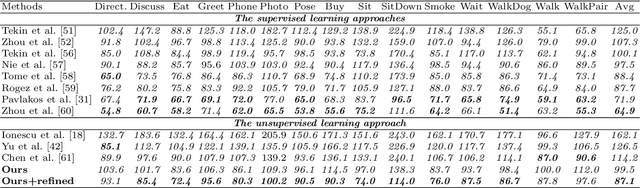
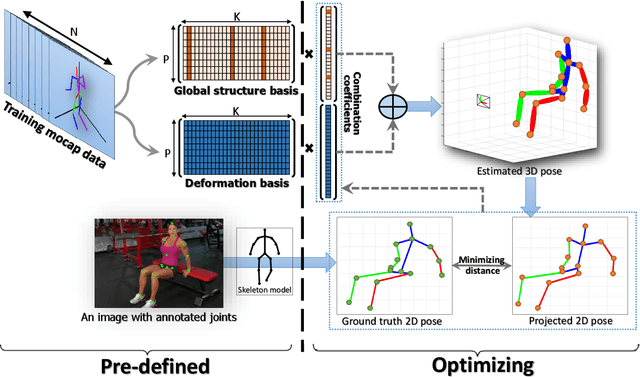
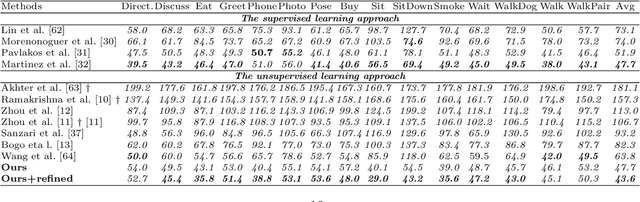
In this paper, we aim to recover the 3D human pose from 2D body joints of a single image. The major challenge in this task is the depth ambiguity since different 3D poses may produce similar 2D poses. Although many recent advances in this problem are found in both unsupervised and supervised learning approaches, the performances of most of these approaches are greatly affected by insufficient diversities and richness of training data. To alleviate this issue, we propose an unsupervised learning approach, which is capable of estimating various complex poses well under limited available training data. Specifically, we propose a Shape Decomposition Model (SDM) in which a 3D pose is considered as the superposition of two parts which are global structure together with some deformations. Based on SDM, we estimate these two parts explicitly by solving two sets of different distributed combination coefficients of geometric priors. In addition, to obtain geometric priors, a joint dictionary learning algorithm is proposed to extract both coarse and fine pose clues simultaneously from limited training data. Quantitative evaluations on several widely used datasets demonstrate that our approach yields better performances over other competitive approaches. Especially, on some categories with more complex deformations, significant improvements are achieved by our approach. Furthermore, qualitative experiments conducted on in-the-wild images also show the effectiveness of the proposed approach.
You Only Look & Listen Once: Towards Fast and Accurate Visual Grounding
Mar 17, 2019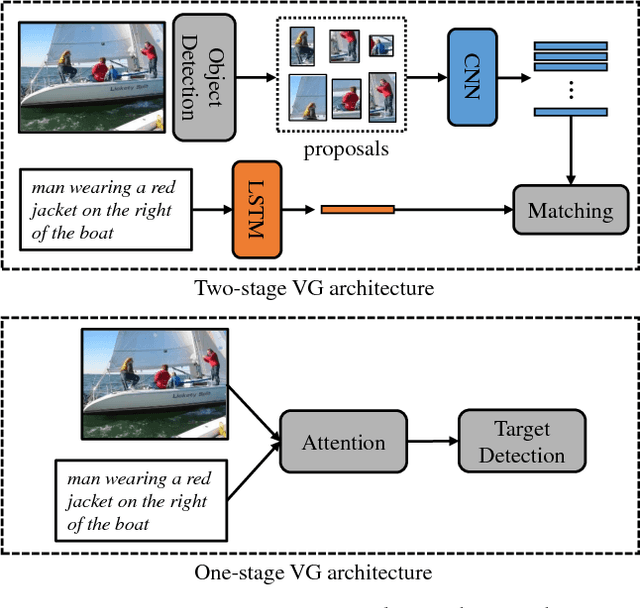
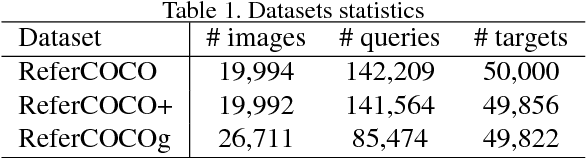
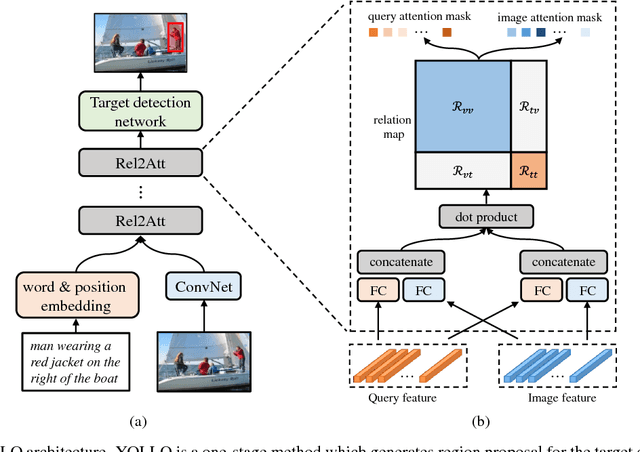
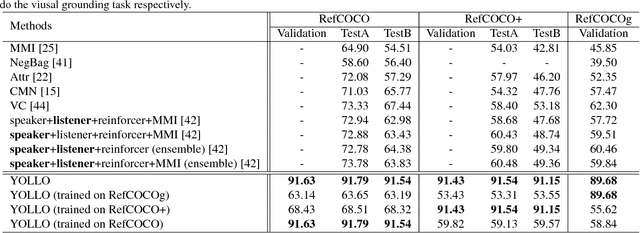
Visual Grounding (VG) aims to locate the most relevant region in an image, based on a flexible natural language query but not a pre-defined label, thus it can be a more useful technique than object detection in practice. Most state-of-the-art methods in VG operate in a two-stage manner, wherein the first stage an object detector is adopted to generate a set of object proposals from the input image and the second stage is simply formulated as a cross-modal matching problem that finds the best match between the language query and all region proposals. This is rather inefficient because there might be hundreds of proposals produced in the first stage that need to be compared in the second stage, not to mention this strategy performs inaccurately. In this paper, we propose an simple, intuitive and much more elegant one-stage detection based method that joints the region proposal and matching stage as a single detection network. The detection is conditioned on the input query with a stack of novel Relation-to-Attention modules that transform the image-to-query relationship to an relation map, which is used to predict the bounding box directly without proposing large numbers of useless region proposals. During the inference, our approach is about 20x ~ 30x faster than previous methods and, remarkably, it achieves 18% ~ 41% absolute performance improvement on top of the state-of-the-art results on several benchmark datasets. We release our code and all the pre-trained models at https://github.com/openblack/rvg.