 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoster: ClawdGo: Endogenous Security Awareness Training for Autonomous AI Agents
Apr 27, 2026Autonomous AI agents deployed on platforms such as OpenClaw face prompt injection, memory poisoning, supply-chain attacks, and social engineering, yet existing defences address only the platform perimeter, leaving the agent's own threat judgement entirely untrained. We present ClawdGo, a framework for endogenous security awareness training: we teach the agent to recognise and reason about threats from the inside, at inference time, with no model modification. Four contributions are introduced: TLDT (Three-Layer Domain Taxonomy) organises 12 trainable dimensions across Self-Defence, Owner-Protection, and Enterprise-Security layers; ASAT (Autonomous Security Awareness Training) is a self-play loop where the agent alternates attacker, defender, and evaluator roles under weakest-first curriculum scheduling; CSMA (Cross-Session Memory Accumulation) compounds skill gains via a four-layer persistent memory architecture and Axiom Crystallisation Promotion (ACP); and SACP (Security Awareness Calibration Problem) formalises the precision-recall tradeoff introduced by endogenous training. Live experiments show weakest-first ASAT raises average TLDT score from 80.9 to 96.9 over 16 sessions, outperforming uniform-random scheduling by 6.5 points and covering 11 of 12 dimensions. CSMA retains the full gain across sessions; cold-start ablation recovers only 2.4 points, leaving a 13.6-point gap. E-mode generates 32 TLDT-conformant scenarios covering all 12 dimensions. SACP is observed when a heavily trained agent classifies a legitimate capability assessment as prompt injection (30/160).
RTLSeek: Boosting the LLM-Based RTL Generation with Multi-Stage Diversity-Oriented Reinforcement Learning
Mar 29, 2026Register Transfer Level (RTL) design translates high-level specifications into hardware using HDLs such as Verilog. Although LLM-based RTL generation is promising, the scarcity of functionally verifiable high-quality data limits both accuracy and diversity. Existing post-training typically produces a single HDL implementation per specification, lacking awareness of RTL variations needed for different design goals. We propose RTLSeek, a post-training paradigm that applies rule-based Diversity-Oriented Reinforcement Learning to improve RTL correctness and diversity. Our Diversity-Centric Multi-Objective Reward Scheduling integrates expert knowledge with EDA feedback, and a three-stage framework maximizes the utility of limited data. Experiments on the RTLLM benchmark show that RTLSeek surpasses prior methods, with ablation results confirming that encouraging broader design-space exploration improves RTL quality and achieves the principle of "the more generated, the better results." Implementation framework, including the dataset, source code, and model weights, is shown at https://anonymous.4open.science/r/DAC2026ID71-ACB4/.
Uni-World VLA: Interleaved World Modeling and Planning for Autonomous Driving
Mar 28, 2026Autonomous driving requires reasoning about how the environment evolves and planning actions accordingly. Existing world-model-based approaches typically predict future scenes first and plan afterwards, resulting in open-loop imagination that may drift from the actual decision process. In this paper, we present Uni-World VLA, a unified vision-language-action (VLA) model that tightly interleaves future frame prediction and trajectory planning. Instead of generating a full world rollout before planning, our model alternates between predicting future frames and ego actions step by step, allowing planning decisions to be continuously conditioned on the imagined future observations. This interleaved generation forms a closed-loop interaction between world modeling and control, enabling more adaptive decision-making in dynamic traffic scenarios. In addition, we incorporate monocular depth information into frames to provide stronger geometric cues for world modeling, improving long-horizon scene prediction. Experiments on the NAVSIM benchmark show that our approach achieves competitive closed-loop planning performance while producing high-fidelity future frame predictions. These results demonstrate that tightly coupling world prediction and planning is a promising direction for scalable VLA driving systems.
Vec-QMDP: Vectorized POMDP Planning on CPUs for Real-Time Autonomous Driving
Feb 09, 2026Planning under uncertainty for real-world robotics tasks, such as autonomous driving, requires reasoning in enormous high-dimensional belief spaces, rendering the problem computationally intensive. While parallelization offers scalability, existing hybrid CPU-GPU solvers face critical bottlenecks due to host-device synchronization latency and branch divergence on SIMT architectures, limiting their utility for real-time planning and hindering real-robot deployment. We present Vec-QMDP, a CPU-native parallel planner that aligns POMDP search with modern CPUs' SIMD architecture, achieving $227\times$--$1073\times$ speedup over state-of-the-art serial planners. Vec-QMDP adopts a Data-Oriented Design (DOD), refactoring scattered, pointer-based data structures into contiguous, cache-efficient memory layouts. We further introduce a hierarchical parallelism scheme: distributing sub-trees across independent CPU cores and SIMD lanes, enabling fully vectorized tree expansion and collision checking. Efficiency is maximized with the help of UCB load balancing across trees and a vectorized STR-tree for coarse-level collision checking. Evaluated on large-scale autonomous driving benchmarks, Vec-QMDP achieves state-of-the-art planning performance with millisecond-level latency, establishing CPUs as a high-performance computing platform for large-scale planning under uncertainty.
SGDrive: Scene-to-Goal Hierarchical World Cognition for Autonomous Driving
Jan 12, 2026Recent end-to-end autonomous driving approaches have leveraged Vision-Language Models (VLMs) to enhance planning capabilities in complex driving scenarios. However, VLMs are inherently trained as generalist models, lacking specialized understanding of driving-specific reasoning in 3D space and time. When applied to autonomous driving, these models struggle to establish structured spatial-temporal representations that capture geometric relationships, scene context, and motion patterns critical for safe trajectory planning. To address these limitations, we propose SGDrive, a novel framework that explicitly structures the VLM's representation learning around driving-specific knowledge hierarchies. Built upon a pre-trained VLM backbone, SGDrive decomposes driving understanding into a scene-agent-goal hierarchy that mirrors human driving cognition: drivers first perceive the overall environment (scene context), then attend to safety-critical agents and their behaviors, and finally formulate short-term goals before executing actions. This hierarchical decomposition provides the structured spatial-temporal representation that generalist VLMs lack, integrating multi-level information into a compact yet comprehensive format for trajectory planning. Extensive experiments on the NAVSIM benchmark demonstrate that SGDrive achieves state-of-the-art performance among camera-only methods on both PDMS and EPDMS, validating the effectiveness of hierarchical knowledge structuring for adapting generalist VLMs to autonomous driving.
LatentVLA: Efficient Vision-Language Models for Autonomous Driving via Latent Action Prediction
Jan 09, 2026End-to-end autonomous driving models trained on largescale datasets perform well in common scenarios but struggle with rare, long-tail situations due to limited scenario diversity. Recent Vision-Language-Action (VLA) models leverage broad knowledge from pre-trained visionlanguage models to address this limitation, yet face critical challenges: (1) numerical imprecision in trajectory prediction due to discrete tokenization, (2) heavy reliance on language annotations that introduce linguistic bias and annotation burden, and (3) computational inefficiency from multi-step chain-of-thought reasoning hinders real-time deployment. We propose LatentVLA, a novel framework that employs self-supervised latent action prediction to train VLA models without language annotations, eliminating linguistic bias while learning rich driving representations from unlabeled trajectory data. Through knowledge distillation, LatentVLA transfers the generalization capabilities of VLA models to efficient vision-based networks, achieving both robust performance and real-time efficiency. LatentVLA establishes a new state-of-the-art on the NAVSIM benchmark with a PDMS score of 92.4 and demonstrates strong zeroshot generalization on the nuScenes benchmark.
Multimodal Prompt Alignment for Facial Expression Recognition
Jun 26, 2025Prompt learning has been widely adopted to efficiently adapt vision-language models (VLMs) like CLIP for various downstream tasks. Despite their success, current VLM-based facial expression recognition (FER) methods struggle to capture fine-grained textual-visual relationships, which are essential for distinguishing subtle differences between facial expressions. To address this challenge, we propose a multimodal prompt alignment framework for FER, called MPA-FER, that provides fine-grained semantic guidance to the learning process of prompted visual features, resulting in more precise and interpretable representations. Specifically, we introduce a multi-granularity hard prompt generation strategy that utilizes a large language model (LLM) like ChatGPT to generate detailed descriptions for each facial expression. The LLM-based external knowledge is injected into the soft prompts by minimizing the feature discrepancy between the soft prompts and the hard prompts. To preserve the generalization abilities of the pretrained CLIP model, our approach incorporates prototype-guided visual feature alignment, ensuring that the prompted visual features from the frozen image encoder align closely with class-specific prototypes. Additionally, we propose a cross-modal global-local alignment module that focuses on expression-relevant facial features, further improving the alignment between textual and visual features. Extensive experiments demonstrate our framework outperforms state-of-the-art methods on three FER benchmark datasets, while retaining the benefits of the pretrained model and minimizing computational costs.
FocalAD: Local Motion Planning for End-to-End Autonomous Driving
Jun 13, 2025In end-to-end autonomous driving,the motion prediction plays a pivotal role in ego-vehicle planning. However, existing methods often rely on globally aggregated motion features, ignoring the fact that planning decisions are primarily influenced by a small number of locally interacting agents. Failing to attend to these critical local interactions can obscure potential risks and undermine planning reliability. In this work, we propose FocalAD, a novel end-to-end autonomous driving framework that focuses on critical local neighbors and refines planning by enhancing local motion representations. Specifically, FocalAD comprises two core modules: the Ego-Local-Agents Interactor (ELAI) and the Focal-Local-Agents Loss (FLA Loss). ELAI conducts a graph-based ego-centric interaction representation that captures motion dynamics with local neighbors to enhance both ego planning and agent motion queries. FLA Loss increases the weights of decision-critical neighboring agents, guiding the model to prioritize those more relevant to planning. Extensive experiments show that FocalAD outperforms existing state-of-the-art methods on the open-loop nuScenes datasets and closed-loop Bench2Drive benchmark. Notably, on the robustness-focused Adv-nuScenes dataset, FocalAD achieves even greater improvements, reducing the average colilision rate by 41.9% compared to DiffusionDrive and by 15.6% compared to SparseDrive.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
Enhancing User-Oriented Proactivity in Open-Domain Dialogues with Critic Guidance
May 18, 2025
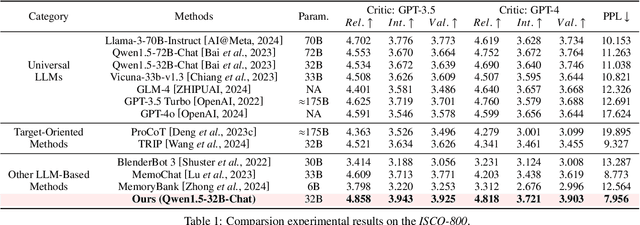
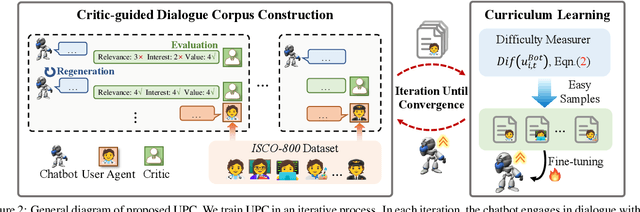

Open-domain dialogue systems aim to generate natural and engaging conversations, providing significant practical value in real applications such as social robotics and personal assistants. The advent of large language models (LLMs) has greatly advanced this field by improving context understanding and conversational fluency. However, existing LLM-based dialogue systems often fall short in proactively understanding the user's chatting preferences and guiding conversations toward user-centered topics. This lack of user-oriented proactivity can lead users to feel unappreciated, reducing their satisfaction and willingness to continue the conversation in human-computer interactions. To address this issue, we propose a User-oriented Proactive Chatbot (UPC) to enhance the user-oriented proactivity. Specifically, we first construct a critic to evaluate this proactivity inspired by the LLM-as-a-judge strategy. Given the scarcity of high-quality training data, we then employ the critic to guide dialogues between the chatbot and user agents, generating a corpus with enhanced user-oriented proactivity. To ensure the diversity of the user backgrounds, we introduce the ISCO-800, a diverse user background dataset for constructing user agents. Moreover, considering the communication difficulty varies among users, we propose an iterative curriculum learning method that trains the chatbot from easy-to-communicate users to more challenging ones, thereby gradually enhancing its performance. Experiments demonstrate that our proposed training method is applicable to different LLMs, improving user-oriented proactivity and attractiveness in open-domain dialogues.