 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2nd of the 5th PVUW MeViS-Audio Track: ASR-SaSaSa2VA
Apr 27, 2026Audio-based video object segmentation aims to locate and segment objects in videos conditioned on audio cues, requiring precise understanding of both appearance and motion. Recent audio-driven video segmentation methods extend MLLMs by fusing audio and visual features for end-to-end localization. Despite their promise, these approaches are computationally intensive, struggle with aligning temporal audio cues to dynamic video content, and depend on large paired audio-video datasets. To address these challenges, we present ASR-SaSaSa2VA, a resource-efficient framework for audio-guided video segmentation. The key idea is to convert audio inputs into textual motion descriptions via automatic speech recognition (ASR) models and then leverage pre-trained text-based referring video segmentation models (e.g., SaSaSa2VA) for pixel-level predictions. To further enhance robustness, we incorporate a no-target expression detection module, implemented by a fine-tuned audio-based MLLM, which filters out audio clips that do not refer to any target object. This design allows the system to exploit strong pre-trained models while effectively handling ambiguous or irrelevant audio inputs. Our approach achieves a final score of 80.7 in the 5th PVUW Challenge (MeViS-v2-Audio track), earning the second-place ranking.
ASSR-Net: Anisotropic Structure-Aware and Spectrally Recalibrated Network for Hyperspectral Image Fusion
Apr 07, 2026Hyperspectral image fusion aims to reconstruct high-spatial-resolution hyperspectral images (HR-HSI) by integrating complementary information from multi-source inputs. Despite recent progress, existing methods still face two critical challenges: (1) inadequate reconstruction of anisotropic spatial structures, resulting in blurred details and compromised spatial quality; and (2) spectral distortion during fusion, which hinders fine-grained spectral representation. To address these issues, we propose \textbf{ASSR-Net}: an Anisotropic Structure-Aware and Spectrally Recalibrated Network for Hyperspectral Image Fusion. ASSR-Net adopts a two-stage fusion strategy comprising anisotropic structure-aware spatial enhancement (ASSE) and hierarchical prior-guided spectral calibration (HPSC). In the first stage, a directional perception fusion module adaptively captures structural features along multiple orientations, effectively reconstructing anisotropic spatial patterns. In the second stage, a spectral recalibration module leverages the original low-resolution HSI as a spectral prior to explicitly correct spectral deviations in the fused results, thereby enhancing spectral fidelity. Extensive experiments on various benchmark datasets demonstrate that ASSR-Net consistently outperforms state-of-the-art methods, achieving superior spatial detail preservation and spectral consistency.
SARCLIP: A Vision Language Foundation Model for Semantic Understanding and Target Recognition in SAR Imagery
Oct 26, 2025Synthetic Aperture Radar (SAR) has emerged as a crucial imaging modality due to its all-weather capabilities. While recent advancements in self-supervised learning and Masked Image Modeling (MIM) have paved the way for SAR foundation models, these approaches primarily focus on low-level visual features, often overlooking multimodal alignment and zero-shot target recognition within SAR imagery. To address this limitation, we construct SARCLIP-1M, a large-scale vision language dataset comprising over one million text-image pairs aggregated from existing datasets. We further introduce SARCLIP, the first vision language foundation model tailored for the SAR domain. Our SARCLIP model is trained using a contrastive vision language learning approach by domain transferring strategy, enabling it to bridge the gap between SAR imagery and textual descriptions. Extensive experiments on image-text retrieval and zero-shot classification tasks demonstrate the superior performance of SARCLIP in feature extraction and interpretation, significantly outperforming state-of-the-art foundation models and advancing the semantic understanding of SAR imagery. The code and datasets will be released soon.
Physics-Driven Spatiotemporal Modeling for AI-Generated Video Detection
Oct 09, 2025



AI-generated videos have achieved near-perfect visual realism (e.g., Sora), urgently necessitating reliable detection mechanisms. However, detecting such videos faces significant challenges in modeling high-dimensional spatiotemporal dynamics and identifying subtle anomalies that violate physical laws. In this paper, we propose a physics-driven AI-generated video detection paradigm based on probability flow conservation principles. Specifically, we propose a statistic called Normalized Spatiotemporal Gradient (NSG), which quantifies the ratio of spatial probability gradients to temporal density changes, explicitly capturing deviations from natural video dynamics. Leveraging pre-trained diffusion models, we develop an NSG estimator through spatial gradients approximation and motion-aware temporal modeling without complex motion decomposition while preserving physical constraints. Building on this, we propose an NSG-based video detection method (NSG-VD) that computes the Maximum Mean Discrepancy (MMD) between NSG features of the test and real videos as a detection metric. Last, we derive an upper bound of NSG feature distances between real and generated videos, proving that generated videos exhibit amplified discrepancies due to distributional shifts. Extensive experiments confirm that NSG-VD outperforms state-of-the-art baselines by 16.00% in Recall and 10.75% in F1-Score, validating the superior performance of NSG-VD. The source code is available at https://github.com/ZSHsh98/NSG-VD.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
Multimodal Prompt Alignment for Facial Expression Recognition
Jun 26, 2025Prompt learning has been widely adopted to efficiently adapt vision-language models (VLMs) like CLIP for various downstream tasks. Despite their success, current VLM-based facial expression recognition (FER) methods struggle to capture fine-grained textual-visual relationships, which are essential for distinguishing subtle differences between facial expressions. To address this challenge, we propose a multimodal prompt alignment framework for FER, called MPA-FER, that provides fine-grained semantic guidance to the learning process of prompted visual features, resulting in more precise and interpretable representations. Specifically, we introduce a multi-granularity hard prompt generation strategy that utilizes a large language model (LLM) like ChatGPT to generate detailed descriptions for each facial expression. The LLM-based external knowledge is injected into the soft prompts by minimizing the feature discrepancy between the soft prompts and the hard prompts. To preserve the generalization abilities of the pretrained CLIP model, our approach incorporates prototype-guided visual feature alignment, ensuring that the prompted visual features from the frozen image encoder align closely with class-specific prototypes. Additionally, we propose a cross-modal global-local alignment module that focuses on expression-relevant facial features, further improving the alignment between textual and visual features. Extensive experiments demonstrate our framework outperforms state-of-the-art methods on three FER benchmark datasets, while retaining the benefits of the pretrained model and minimizing computational costs.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
Panoramic Out-of-Distribution Segmentation
May 06, 2025Panoramic imaging enables capturing 360{\deg} images with an ultra-wide Field-of-View (FoV) for dense omnidirectional perception. However, current panoramic semantic segmentation methods fail to identify outliers, and pinhole Out-of-distribution Segmentation (OoS) models perform unsatisfactorily in the panoramic domain due to background clutter and pixel distortions. To address these issues, we introduce a new task, Panoramic Out-of-distribution Segmentation (PanOoS), achieving OoS for panoramas. Furthermore, we propose the first solution, POS, which adapts to the characteristics of panoramic images through text-guided prompt distribution learning. Specifically, POS integrates a disentanglement strategy designed to materialize the cross-domain generalization capability of CLIP. The proposed Prompt-based Restoration Attention (PRA) optimizes semantic decoding by prompt guidance and self-adaptive correction, while Bilevel Prompt Distribution Learning (BPDL) refines the manifold of per-pixel mask embeddings via semantic prototype supervision. Besides, to compensate for the scarcity of PanOoS datasets, we establish two benchmarks: DenseOoS, which features diverse outliers in complex environments, and QuadOoS, captured by a quadruped robot with a panoramic annular lens system. Extensive experiments demonstrate superior performance of POS, with AuPRC improving by 34.25% and FPR95 decreasing by 21.42% on DenseOoS, outperforming state-of-the-art pinhole-OoS methods. Moreover, POS achieves leading closed-set segmentation capabilities. Code and datasets will be available at https://github.com/MengfeiD/PanOoS.
Learning from Noisy Pseudo-labels for All-Weather Land Cover Mapping
Apr 18, 2025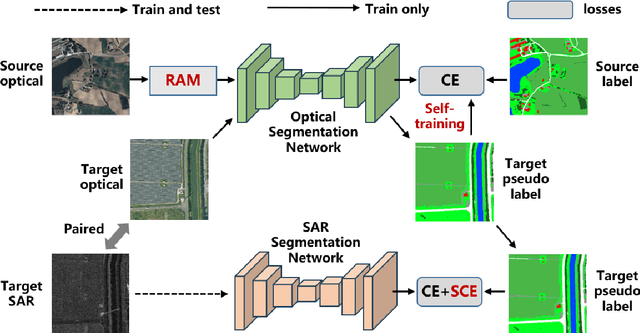
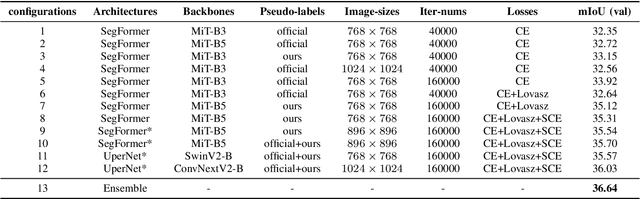
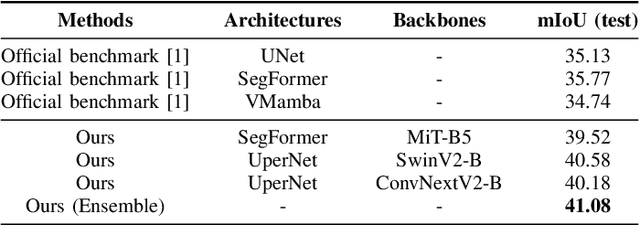
Semantic segmentation of SAR images has garnered significant attention in remote sensing due to the immunity of SAR sensors to cloudy weather and light conditions. Nevertheless, SAR imagery lacks detailed information and is plagued by significant speckle noise, rendering the annotation or segmentation of SAR images a formidable task. Recent efforts have resorted to annotating paired optical-SAR images to generate pseudo-labels through the utilization of an optical image segmentation network. However, these pseudo-labels are laden with noise, leading to suboptimal performance in SAR image segmentation. In this study, we introduce a more precise method for generating pseudo-labels by incorporating semi-supervised learning alongside a novel image resolution alignment augmentation. Furthermore, we introduce a symmetric cross-entropy loss to mitigate the impact of noisy pseudo-labels. Additionally, a bag of training and testing tricks is utilized to generate better land-cover mapping results. Our experiments on the GRSS data fusion contest indicate the effectiveness of the proposed method, which achieves first place. The code is available at https://github.com/StuLiu/DFC2025Track1.git.
DREB-Net: Dual-stream Restoration Embedding Blur-feature Fusion Network for High-mobility UAV Object Detection
Oct 23, 2024



Object detection algorithms are pivotal components of unmanned aerial vehicle (UAV) imaging systems, extensively employed in complex fields. However, images captured by high-mobility UAVs often suffer from motion blur cases, which significantly impedes the performance of advanced object detection algorithms. To address these challenges, we propose an innovative object detection algorithm specifically designed for blurry images, named DREB-Net (Dual-stream Restoration Embedding Blur-feature Fusion Network). First, DREB-Net addresses the particularities of blurry image object detection problem by incorporating a Blurry image Restoration Auxiliary Branch (BRAB) during the training phase. Second, it fuses the extracted shallow features via Multi-level Attention-Guided Feature Fusion (MAGFF) module, to extract richer features. Here, the MAGFF module comprises local attention modules and global attention modules, which assign different weights to the branches. Then, during the inference phase, the deep feature extraction of the BRAB can be removed to reduce computational complexity and improve detection speed. In loss function, a combined loss of MSE and SSIM is added to the BRAB to restore blurry images. Finally, DREB-Net introduces Fast Fourier Transform in the early stages of feature extraction, via a Learnable Frequency domain Amplitude Modulation Module (LFAMM), to adjust feature amplitude and enhance feature processing capability. Experimental results indicate that DREB-Net can still effectively perform object detection tasks under motion blur in captured images, showcasing excellent performance and broad application prospects. Our source code will be available at https://github.com/EEIC-Lab/DREB-Net.git.