 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCP: Representation Consistency Pruner for Mitigating Distribution Shift in Large Vision-Language Models
Apr 04, 2026Large Vision-Language Models (LVLMs) suffer from prohibitive inference costs due to the massive number of visual tokens processed by the language decoder. Existing pruning methods often lead to significant performance degradation because the irreversible removal of visual tokens causes a distribution shift in the hidden states that deviates from the pre-trained full-token regime. To address this, we propose Representation Consistency Pruner, which we refer to as RCP, as a novel framework that integrates cumulative visual token pruning with a delayed repair mechanism. Specifically, we introduce a cross-attention pruner that leverages the intrinsic attention of the LLM as a baseline to predict cumulative masks, ensuring consistent and monotonic token reduction across layers. To compensate for the resulting information loss, we design a delayed repair adapter denoted as DRA, which caches the essence of pruned tokens and applies FiLM-based modulation specifically to the answer generation tokens. We employ a repair loss to match the first and second-order statistics of the pruned representations with a full-token teacher. RCP is highly efficient because it trains only lightweight plug-in modules while allowing for physical token discarding at inference. Extensive experiments on LVLM benchmarks demonstrate that RCP removes up to 88.9\% of visual tokens and reduces FLOPs by up to 85.7\% with only a marginal average accuracy drop, and outperforms prior methods that avoid fine-tuning the original model on several widely used benchmarks.
SARCLIP: A Vision Language Foundation Model for Semantic Understanding and Target Recognition in SAR Imagery
Oct 26, 2025Synthetic Aperture Radar (SAR) has emerged as a crucial imaging modality due to its all-weather capabilities. While recent advancements in self-supervised learning and Masked Image Modeling (MIM) have paved the way for SAR foundation models, these approaches primarily focus on low-level visual features, often overlooking multimodal alignment and zero-shot target recognition within SAR imagery. To address this limitation, we construct SARCLIP-1M, a large-scale vision language dataset comprising over one million text-image pairs aggregated from existing datasets. We further introduce SARCLIP, the first vision language foundation model tailored for the SAR domain. Our SARCLIP model is trained using a contrastive vision language learning approach by domain transferring strategy, enabling it to bridge the gap between SAR imagery and textual descriptions. Extensive experiments on image-text retrieval and zero-shot classification tasks demonstrate the superior performance of SARCLIP in feature extraction and interpretation, significantly outperforming state-of-the-art foundation models and advancing the semantic understanding of SAR imagery. The code and datasets will be released soon.
Large-Model AI for Near Field Beam Prediction: A CNN-GPT2 Framework for 6G XL-MIMO
Oct 26, 2025
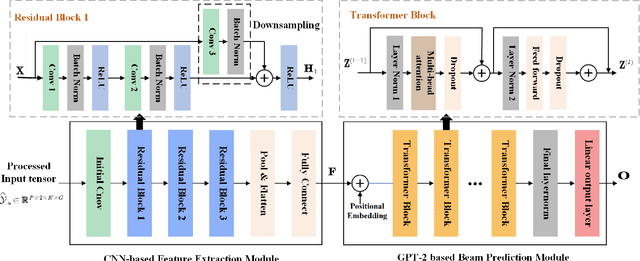
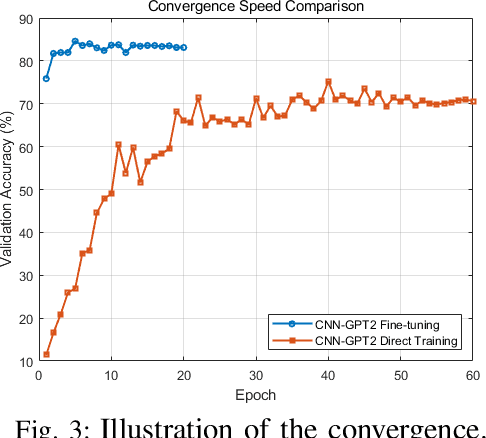
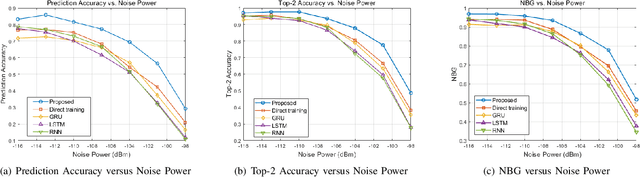
The emergence of extremely large-scale antenna arrays (ELAA) in millimeter-wave (mmWave) communications, particularly in high-mobility scenarios, highlights the importance of near-field beam prediction. Unlike the conventional far-field assumption, near-field beam prediction requires codebooks that jointly sample the angular and distance domains, which leads to a dramatic increase in pilot overhead. Moreover, unlike the far- field case where the optimal beam evolution is temporally smooth, the optimal near-field beam index exhibits abrupt and nonlinear dynamics due to its joint dependence on user angle and distance, posing significant challenges for temporal modeling. To address these challenges, we propose a novel Convolutional Neural Network-Generative Pre-trained Transformer 2 (CNN-GPT2) based near-field beam prediction framework. Specifically, an uplink pilot transmission strategy is designed to enable efficient channel probing through widebeam analog precoding and frequency-varying digital precoding. The received pilot signals are preprocessed and passed through a CNN-based feature extractor, followed by a GPT-2 model that captures temporal dependencies across multiple frames and directly predicts the near-field beam index in an end-to-end manner.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
Learning from Noisy Pseudo-labels for All-Weather Land Cover Mapping
Apr 18, 2025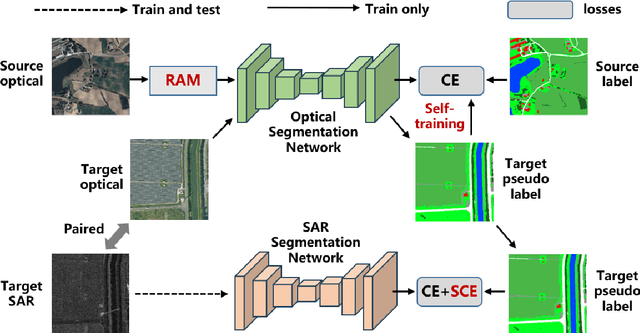
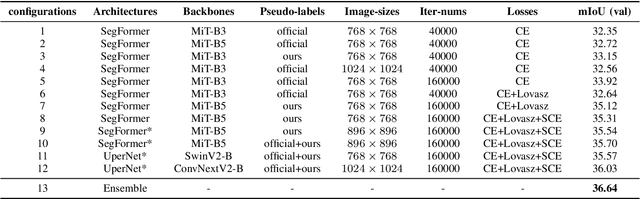
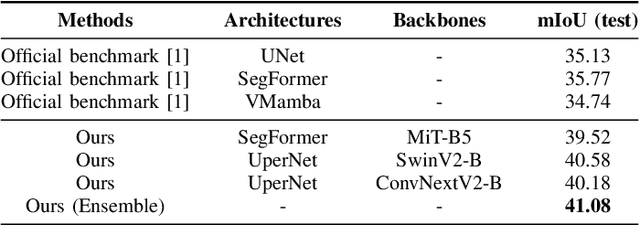
Semantic segmentation of SAR images has garnered significant attention in remote sensing due to the immunity of SAR sensors to cloudy weather and light conditions. Nevertheless, SAR imagery lacks detailed information and is plagued by significant speckle noise, rendering the annotation or segmentation of SAR images a formidable task. Recent efforts have resorted to annotating paired optical-SAR images to generate pseudo-labels through the utilization of an optical image segmentation network. However, these pseudo-labels are laden with noise, leading to suboptimal performance in SAR image segmentation. In this study, we introduce a more precise method for generating pseudo-labels by incorporating semi-supervised learning alongside a novel image resolution alignment augmentation. Furthermore, we introduce a symmetric cross-entropy loss to mitigate the impact of noisy pseudo-labels. Additionally, a bag of training and testing tricks is utilized to generate better land-cover mapping results. Our experiments on the GRSS data fusion contest indicate the effectiveness of the proposed method, which achieves first place. The code is available at https://github.com/StuLiu/DFC2025Track1.git.
Agriculture-Vision Challenge 2024 -- The Runner-Up Solution for Agricultural Pattern Recognition via Class Balancing and Model Ensemble
Jun 18, 2024



The Agriculture-Vision Challenge at CVPR 2024 aims at leveraging semantic segmentation models to produce pixel level semantic segmentation labels within regions of interest for multi-modality satellite images. It is one of the most famous and competitive challenges for global researchers to break the boundary between computer vision and agriculture sectors. However, there is a serious class imbalance problem in the agriculture-vision dataset, which hinders the semantic segmentation performance. To solve this problem, firstly, we propose a mosaic data augmentation with a rare class sampling strategy to enrich long-tail class samples. Secondly, we employ an adaptive class weight scheme to suppress the contribution of the common classes while increasing the ones of rare classes. Thirdly, we propose a probability post-process to increase the predicted value of the rare classes. Our methodology achieved a mean Intersection over Union (mIoU) score of 0.547 on the test set, securing second place in this challenge.
NMBEnet: Efficient Near-field mmWave Beam Training for Multiuser OFDM Systems Using Sub-6 GHz Pilots
Apr 23, 2024



Combining millimetre-wave (mmWave) communications with an extremely large-scale antenna array (ELAA) presents a promising avenue for meeting the spectral efficiency demands of the future sixth generation (6G) mobile communications. However, beam training for mmWave ELAA systems is challenged by excessive pilot overheads as well as insufficient accuracy, as the huge near-field codebook has to be accounted for. In this paper, inspired by the similarity between far-field sub-6 GHz channels and near-field mmWave channels, we propose to leverage sub-6 GHz uplink pilot signals to directly estimate the optimal near-field mmWave codeword, which aims to reduce pilot overhead and bypass the channel estimation. Moreover, we adopt deep learning to perform this dual mapping function, i.e., sub-6 GHz to mmWave, far-field to near-field, and a novel neural network structure called NMBEnet is designed to enhance the precision of beam training. Specifically, when considering the orthogonal frequency division multiplexing (OFDM) communication scenarios with high user density, correlations arise both between signals from different users and between signals from different subcarriers. Accordingly, the convolutional neural network (CNN) module and graph neural network (GNN) module included in the proposed NMBEnet can leverage these two correlations to further enhance the precision of beam training.
Near-Field Multiuser Beam-Training for Extremely Large-Scale MIMO Systems
Feb 21, 2024Extremely large-scale multiple-input multiple-output (XL-MIMO) systems are capable of improving spectral efficiency by employing far more antennas than conventional massive MIMO at the base station (BS). However, beam training in multiuser XL-MIMO systems is challenging. To tackle these issues, we conceive a three-phase graph neural network (GNN)-based beam training scheme for multiuser XL-MIMO systems. In the first phase, only far-field wide beams have to be tested for each user and the GNN is utilized to map the beamforming gain information of the far-field wide beams to the optimal near-field beam for each user. In addition, the proposed GNN-based scheme can exploit the position-correlation between adjacent users for further improvement of the accuracy of beam training. In the second phase, a beam allocation scheme based on the probability vectors produced at the outputs of GNNs is proposed to address the above beam-direction conflicts between users. In the third phase, the hybrid TBF is designed for further reducing the inter-user interference. Our simulation results show that the proposed scheme improves the beam training performance of the benchmarks. Moreover, the performance of the proposed beam training scheme approaches that of an exhaustive search, despite requiring only about 7% of the pilot overhead.
The FruitShell French synthesis system at the Blizzard 2023 Challenge
Sep 01, 2023


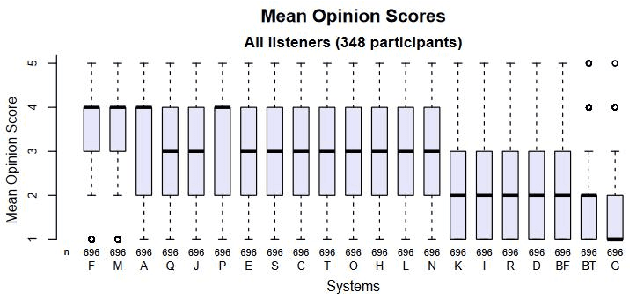
This paper presents a French text-to-speech synthesis system for the Blizzard Challenge 2023. The challenge consists of two tasks: generating high-quality speech from female speakers and generating speech that closely resembles specific individuals. Regarding the competition data, we conducted a screening process to remove missing or erroneous text data. We organized all symbols except for phonemes and eliminated symbols that had no pronunciation or zero duration. Additionally, we added word boundary and start/end symbols to the text, which we have found to improve speech quality based on our previous experience. For the Spoke task, we performed data augmentation according to the competition rules. We used an open-source G2P model to transcribe the French texts into phonemes. As the G2P model uses the International Phonetic Alphabet (IPA), we applied the same transcription process to the provided competition data for standardization. However, due to compiler limitations in recognizing special symbols from the IPA chart, we followed the rules to convert all phonemes into the phonetic scheme used in the competition data. Finally, we resampled all competition audio to a uniform sampling rate of 16 kHz. We employed a VITS-based acoustic model with the hifigan vocoder. For the Spoke task, we trained a multi-speaker model and incorporated speaker information into the duration predictor, vocoder, and flow layers of the model. The evaluation results of our system showed a quality MOS score of 3.6 for the Hub task and 3.4 for the Spoke task, placing our system at an average level among all participating teams.
MLE-based Device Activity Detection under Rician Fading for Massive Grant-free Access with Perfect and Imperfect Synchronization
Jun 11, 2023Most existing studies on massive grant-free access, proposed to support massive machine-type communications (mMTC) for the Internet of things (IoT), assume Rayleigh fading and perfect synchronization for simplicity. However, in practice, line-of-sight (LoS) components generally exist, and time and frequency synchronization are usually imperfect. This paper systematically investigates maximum likelihood estimation (MLE)-based device activity detection under Rician fading for massive grant-free access with perfect and imperfect synchronization. Specifically, we formulate device activity detection in the synchronous case and joint device activity and offset detection in three asynchronous cases (i.e., time, frequency, and time and frequency asynchronous cases) as MLE problems. In the synchronous case, we propose an iterative algorithm to obtain a stationary point of the MLE problem. In each asynchronous case, we propose two iterative algorithms with identical detection performance but different computational complexities. In particular, one is computationally efficient for small ranges of offsets, whereas the other one, relying on fast Fourier transform (FFT) and inverse FFT, is computationally efficient for large ranges of offsets. The proposed algorithms generalize the existing MLE-based methods for Rayleigh fading and perfect synchronization. Numerical results show the notable gains of the proposed algorithms over existing methods in detection accuracy and computation time.