 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSARCLIP: A Vision Language Foundation Model for Semantic Understanding and Target Recognition in SAR Imagery
Oct 26, 2025Synthetic Aperture Radar (SAR) has emerged as a crucial imaging modality due to its all-weather capabilities. While recent advancements in self-supervised learning and Masked Image Modeling (MIM) have paved the way for SAR foundation models, these approaches primarily focus on low-level visual features, often overlooking multimodal alignment and zero-shot target recognition within SAR imagery. To address this limitation, we construct SARCLIP-1M, a large-scale vision language dataset comprising over one million text-image pairs aggregated from existing datasets. We further introduce SARCLIP, the first vision language foundation model tailored for the SAR domain. Our SARCLIP model is trained using a contrastive vision language learning approach by domain transferring strategy, enabling it to bridge the gap between SAR imagery and textual descriptions. Extensive experiments on image-text retrieval and zero-shot classification tasks demonstrate the superior performance of SARCLIP in feature extraction and interpretation, significantly outperforming state-of-the-art foundation models and advancing the semantic understanding of SAR imagery. The code and datasets will be released soon.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
Learning from Noisy Pseudo-labels for All-Weather Land Cover Mapping
Apr 18, 2025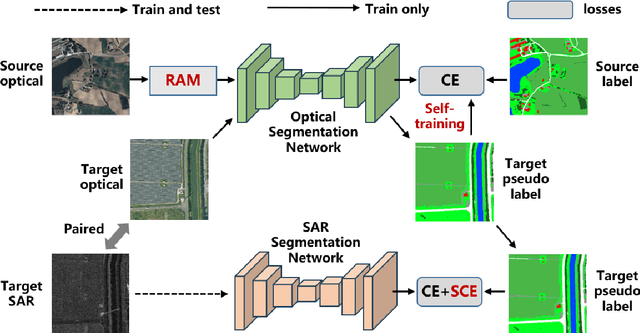
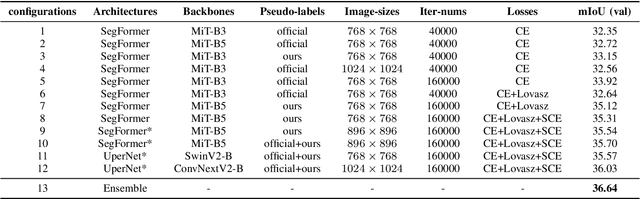
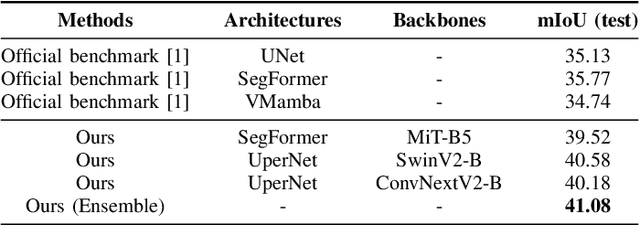
Semantic segmentation of SAR images has garnered significant attention in remote sensing due to the immunity of SAR sensors to cloudy weather and light conditions. Nevertheless, SAR imagery lacks detailed information and is plagued by significant speckle noise, rendering the annotation or segmentation of SAR images a formidable task. Recent efforts have resorted to annotating paired optical-SAR images to generate pseudo-labels through the utilization of an optical image segmentation network. However, these pseudo-labels are laden with noise, leading to suboptimal performance in SAR image segmentation. In this study, we introduce a more precise method for generating pseudo-labels by incorporating semi-supervised learning alongside a novel image resolution alignment augmentation. Furthermore, we introduce a symmetric cross-entropy loss to mitigate the impact of noisy pseudo-labels. Additionally, a bag of training and testing tricks is utilized to generate better land-cover mapping results. Our experiments on the GRSS data fusion contest indicate the effectiveness of the proposed method, which achieves first place. The code is available at https://github.com/StuLiu/DFC2025Track1.git.
Agriculture-Vision Challenge 2024 -- The Runner-Up Solution for Agricultural Pattern Recognition via Class Balancing and Model Ensemble
Jun 18, 2024



The Agriculture-Vision Challenge at CVPR 2024 aims at leveraging semantic segmentation models to produce pixel level semantic segmentation labels within regions of interest for multi-modality satellite images. It is one of the most famous and competitive challenges for global researchers to break the boundary between computer vision and agriculture sectors. However, there is a serious class imbalance problem in the agriculture-vision dataset, which hinders the semantic segmentation performance. To solve this problem, firstly, we propose a mosaic data augmentation with a rare class sampling strategy to enrich long-tail class samples. Secondly, we employ an adaptive class weight scheme to suppress the contribution of the common classes while increasing the ones of rare classes. Thirdly, we propose a probability post-process to increase the predicted value of the rare classes. Our methodology achieved a mean Intersection over Union (mIoU) score of 0.547 on the test set, securing second place in this challenge.
Hyperspectral Remote Sensing Benchmark Database for Oil Spill Detection with an Isolation Forest-Guided Unsupervised Detector
Sep 28, 2022



Oil spill detection has attracted increasing attention in recent years since marine oil spill accidents severely affect environments, natural resources, and the lives of coastal inhabitants. Hyperspectral remote sensing images provide rich spectral information which is beneficial for the monitoring of oil spills in complex ocean scenarios. However, most of the existing approaches are based on supervised and semi-supervised frameworks to detect oil spills from hyperspectral images (HSIs), which require a huge amount of effort to annotate a certain number of high-quality training sets. In this study, we make the first attempt to develop an unsupervised oil spill detection method based on isolation forest for HSIs. First, considering that the noise level varies among different bands, a noise variance estimation method is exploited to evaluate the noise level of different bands, and the bands corrupted by severe noise are removed. Second, kernel principal component analysis (KPCA) is employed to reduce the high dimensionality of the HSIs. Then, the probability of each pixel belonging to one of the classes of seawater and oil spills is estimated with the isolation forest, and a set of pseudo-labeled training samples is automatically produced using the clustering algorithm on the detected probability. Finally, an initial detection map can be obtained by performing the support vector machine (SVM) on the dimension-reduced data, and then, the initial detection result is further optimized with the extended random walker (ERW) model so as to improve the detection accuracy of oil spills. Experiments on airborne hyperspectral oil spill data (HOSD) created by ourselves demonstrate that the proposed method obtains superior detection performance with respect to other state-of-the-art detection approaches.
Fusion of Dual Spatial Information for Hyperspectral Image Classification
Oct 23, 2020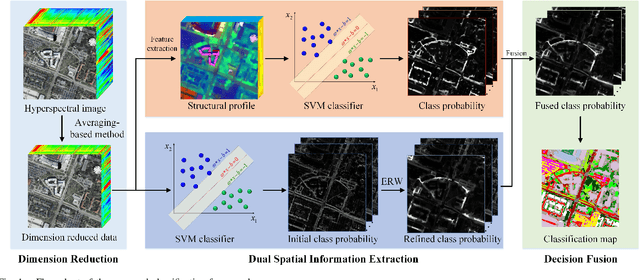
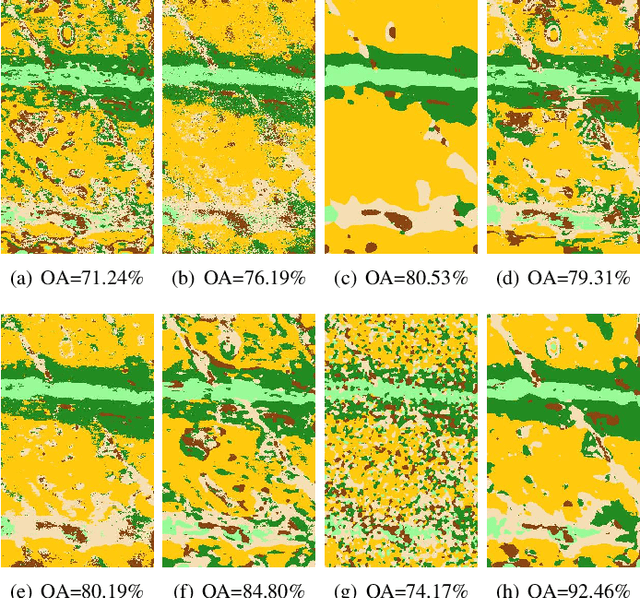

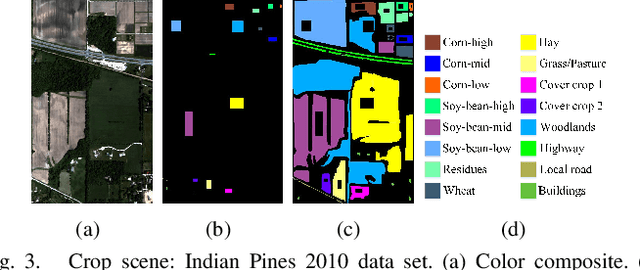
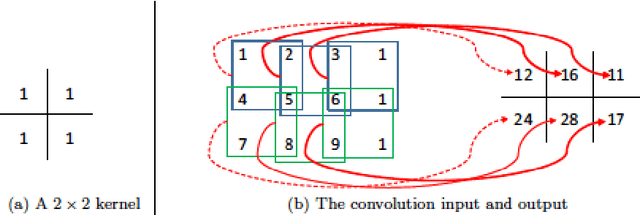
The inclusion of spatial information into spectral classifiers for fine-resolution hyperspectral imagery has led to significant improvements in terms of classification performance. The task of spectral-spatial hyperspectral image classification has remained challenging because of high intraclass spectrum variability and low interclass spectral variability. This fact has made the extraction of spatial information highly active. In this work, a novel hyperspectral image classification framework using the fusion of dual spatial information is proposed, in which the dual spatial information is built by both exploiting pre-processing feature extraction and post-processing spatial optimization. In the feature extraction stage, an adaptive texture smoothing method is proposed to construct the structural profile (SP), which makes it possible to precisely extract discriminative features from hyperspectral images. The SP extraction method is used here for the first time in the remote sensing community. Then, the extracted SP is fed into a spectral classifier. In the spatial optimization stage, a pixel-level classifier is used to obtain the class probability followed by an extended random walker-based spatial optimization technique. Finally, a decision fusion rule is utilized to fuse the class probabilities obtained by the two different stages. Experiments performed on three data sets from different scenes illustrate that the proposed method can outperform other state-of-the-art classification techniques. In addition, the proposed feature extraction method, i.e., SP, can effectively improve the discrimination between different land covers.
Comprehensive Review of Deep Reinforcement Learning Methods and Applications in Economics
Mar 21, 2020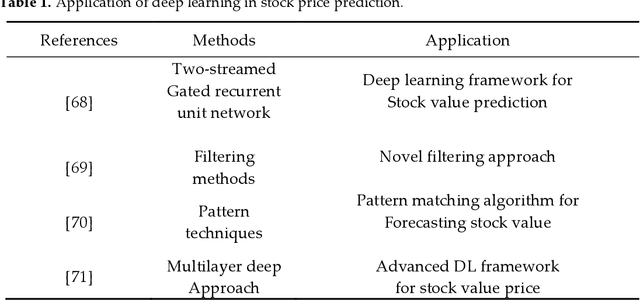

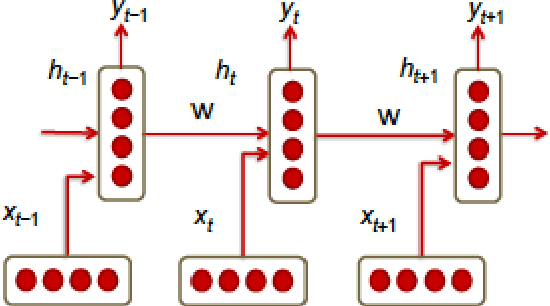
The popularity of deep reinforcement learning (DRL) methods in economics have been exponentially increased. DRL through a wide range of capabilities from reinforcement learning (RL) and deep learning (DL) for handling sophisticated dynamic business environments offers vast opportunities. DRL is characterized by scalability with the potential to be applied to high-dimensional problems in conjunction with noisy and nonlinear patterns of economic data. In this work, we first consider a brief review of DL, RL, and deep RL methods in diverse applications in economics providing an in-depth insight into the state of the art. Furthermore, the architecture of DRL applied to economic applications is investigated in order to highlight the complexity, robustness, accuracy, performance, computational tasks, risk constraints, and profitability. The survey results indicate that DRL can provide better performance and higher accuracy as compared to the traditional algorithms while facing real economic problems at the presence of risk parameters and the ever-increasing uncertainties.
Data Science in Economics
Mar 19, 2020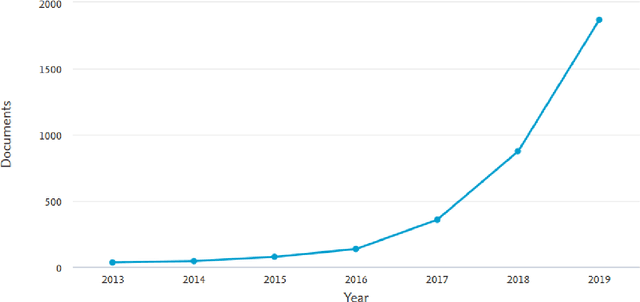

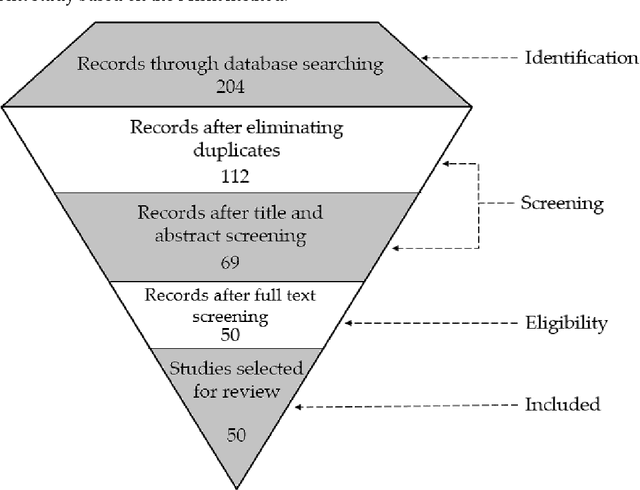

This paper provides the state of the art of data science in economics. Through a novel taxonomy of applications and methods advances in data science are investigated. The data science advances are investigated in three individual classes of deep learning models, ensemble models, and hybrid models. Application domains include stock market, marketing, E-commerce, corporate banking, and cryptocurrency. Prisma method, a systematic literature review methodology is used to ensure the quality of the survey. The findings revealed that the trends are on advancement of hybrid models as more than 51% of the reviewed articles applied hybrid model. On the other hand, it is found that based on the RMSE accuracy metric, hybrid models had higher prediction accuracy than other algorithms. While it is expected the trends go toward the advancements of deep learning models.