 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian Framework on Asymmetric Mixture of Factor Analyser
Nov 04, 2022Mixture of factor analyzer (MFA) model is an efficient model for the analysis of high dimensional data through which the factor-analyzer technique based on the covariance matrices reducing the number of free parameters. The model also provides an important methodology to determine latent groups in data. There are several pieces of research to extend the model based on the asymmetrical and/or with outlier datasets with some known computational limitations that have been examined in frequentist cases. In this paper, an MFA model with a rich and flexible class of skew normal (unrestricted) generalized hyperbolic (called SUNGH) distributions along with a Bayesian structure with several computational benefits have been introduced. The SUNGH family provides considerable flexibility to model skewness in different directions as well as allowing for heavy tailed data. There are several desirable properties in the structure of the SUNGH family, including, an analytically flexible density which leads to easing up the computation applied for the estimation of parameters. Considering factor analysis models, the SUNGH family also allows for skewness and heavy tails for both the error component and factor scores. In the present study, the advantages of using this family of distributions have been discussed and the suitable efficiency of the introduced MFA model using real data examples and simulation has been demonstrated.
A Secure Healthcare 5.0 System Based on Blockchain Technology Entangled with Federated Learning Technique
Sep 16, 2022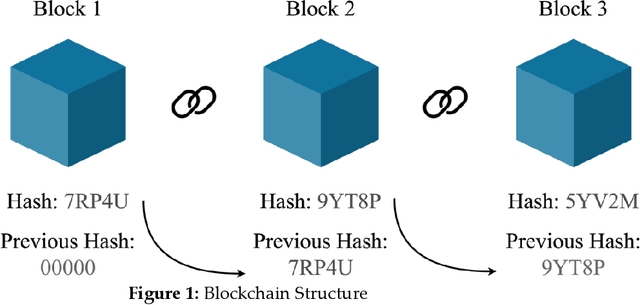
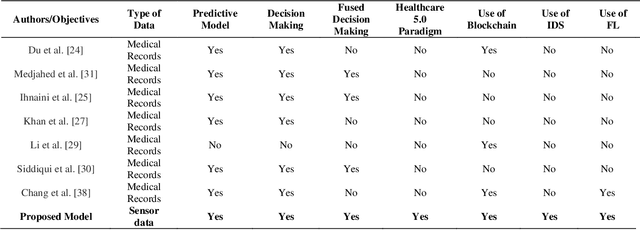
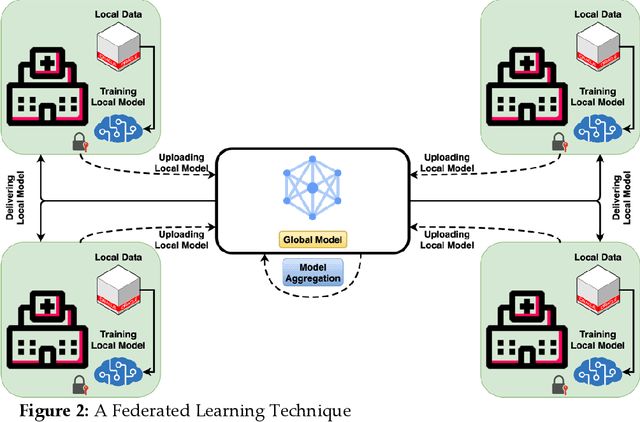

In recent years, the global Internet of Medical Things (IoMT) industry has evolved at a tremendous speed. Security and privacy are key concerns on the IoMT, owing to the huge scale and deployment of IoMT networks. Machine learning (ML) and blockchain (BC) technologies have significantly enhanced the capabilities and facilities of healthcare 5.0, spawning a new area known as "Smart Healthcare." By identifying concerns early, a smart healthcare system can help avoid long-term damage. This will enhance the quality of life for patients while reducing their stress and healthcare costs. The IoMT enables a range of functionalities in the field of information technology, one of which is smart and interactive health care. However, combining medical data into a single storage location to train a powerful machine learning model raises concerns about privacy, ownership, and compliance with greater concentration. Federated learning (FL) overcomes the preceding difficulties by utilizing a centralized aggregate server to disseminate a global learning model. Simultaneously, the local participant keeps control of patient information, assuring data confidentiality and security. This article conducts a comprehensive analysis of the findings on blockchain technology entangled with federated learning in healthcare. 5.0. The purpose of this study is to construct a secure health monitoring system in healthcare 5.0 by utilizing a blockchain technology and Intrusion Detection System (IDS) to detect any malicious activity in a healthcare network and enables physicians to monitor patients through medical sensors and take necessary measures periodically by predicting diseases.
Application of Group Method of Data Handling and New Optimization Algorithms for Predicting Sediment Transport Rate under Vegetation Cover
Sep 16, 2022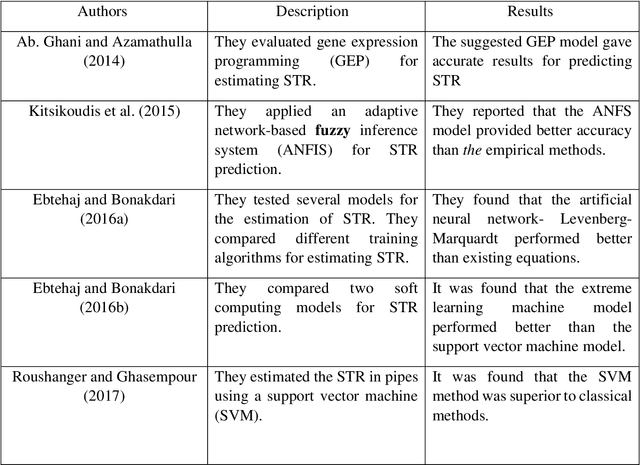
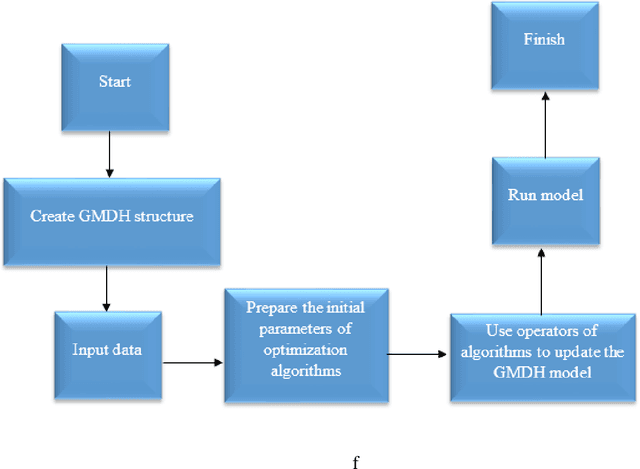
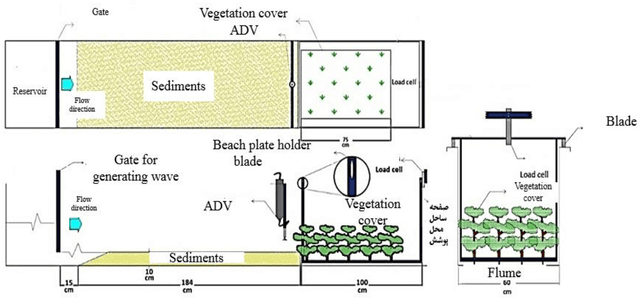
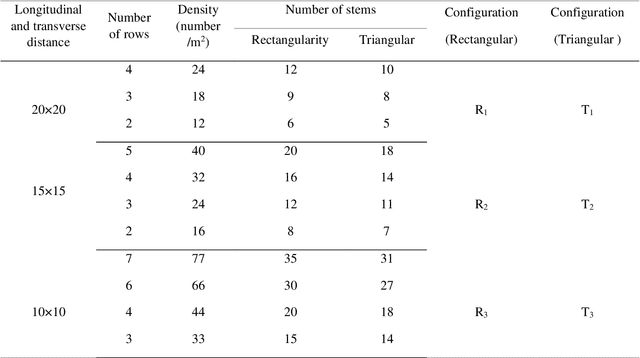
Planting vegetation is one of the practical solutions for reducing sediment transfer rates. Increasing vegetation cover decreases environmental pollution and sediment transport rate (STR). Since sediments and vegetation interact complexly, predicting sediment transport rates is challenging. This study aims to predict sediment transport rate under vegetation cover using new and optimized versions of the group method of data handling (GMDH). Additionally, this study introduces a new ensemble model for predicting sediment transport rates. Model inputs include wave height, wave velocity, density cover, wave force, D50, the height of vegetation cover, and cover stem diameter. A standalone GMDH model and optimized GMDH models, including GMDH honey badger algorithm (HBA) GMDH rat swarm algorithm (RSOA)vGMDH sine cosine algorithm (SCA), and GMDH particle swarm optimization (GMDH-PSO), were used to predict sediment transport rates. As the next step, the outputs of standalone and optimized GMDH were used to construct an ensemble model. The MAE of the ensemble model was 0.145 m3/s, while the MAEs of GMDH-HBA, GMDH-RSOA, GMDH-SCA, GMDH-PSOA, and GMDH in the testing level were 0.176 m3/s, 0.312 m3/s, 0.367 m3/s, 0.498 m3/s, and 0.612 m3/s, respectively. The Nash Sutcliffe coefficient (NSE) of ensemble model, GMDH-HBA, GMDH-RSOA, GMDH-SCA, GMDH-PSOA, and GHMDH were 0.95 0.93, 0.89, 0.86, 0.82, and 0.76, respectively. Additionally, this study demonstrated that vegetation cover decreased sediment transport rate by 90 percent. The results indicated that the ensemble and GMDH-HBA models could accurately predict sediment transport rates. Based on the results of this study, sediment transport rate can be monitored using the IMM and GMDH-HBA. These results are useful for managing and planning water resources in large basins.
Prediction of the energy and exergy performance of F135 PW100 turbofan engine via deep learning
Aug 24, 2022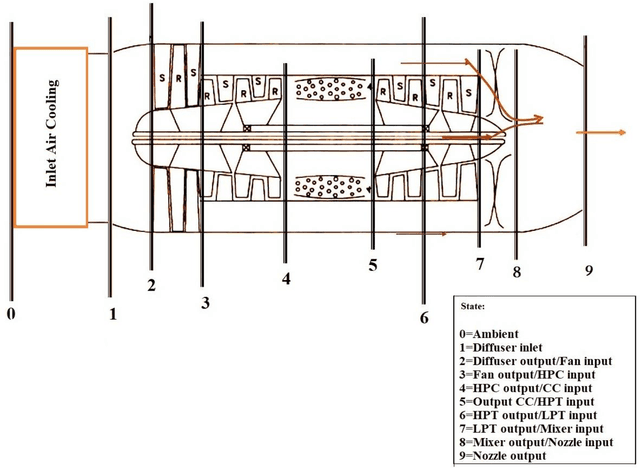
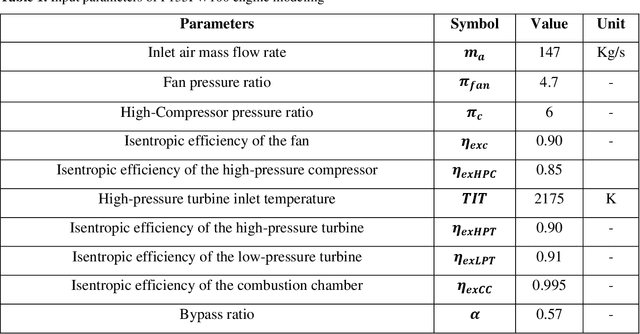
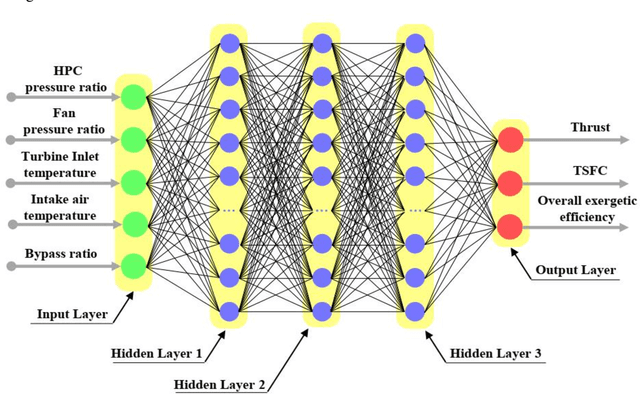
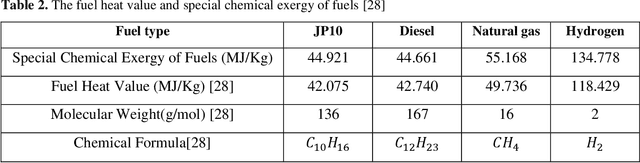
In the present study, the effects of flight-Mach number, flight altitude, fuel types, and intake air temperature on thrust specific fuel consumption, thrust, intake air mass flow rate, thermal and propulsive efficiecies, as well as the exergetic efficiency and the exergy destruction rate in F135 PW100 engine are investigated. Based on the results obtained in the first phase, to model the thermodynamic performance of the aforementioned engine cycle, Flight-Mach number and flight altitude are considered to be 2.5 and 30,000 m, respectively; due to the operational advantage of supersonic flying at high altitude flight conditions, and the higher thrust of hydrogen fuel. Accordingly, in the second phase, taking into account the mentioned flight conditions, an intelligent model has been obtained to predict output parameters (i.e., thrust, thrust specific fuel consumption, and overall exergetic efficiency) using the deep learning method. In the attained deep neural model, the pressure ratio of the high-pressure turbine, fan pressure ratio, turbine inlet temperature, intake air temperature, and bypass ratio are considered input parameters. The provided datasets are randomly divided into two sets: the first one contains 6079 samples for model training and the second set contains 1520 samples for testing. In particular, the Adam optimization algorithm, the cost function of the mean square error, and the active function of rectified linear unit are used to train the network. The results show that the error percentage of the deep neural model is equal to 5.02%, 1.43%, and 2.92% to predict thrust, thrust specific fuel consumption, and overall exergetic efficiency, respectively, which indicates the success of the attained model in estimating the output parameters of the present problem.
* 41 pages, 13 figures, 4 tables
Energy-Exergy Analysis and Optimal Design of a Hydrogen Turbofan Engine
Aug 14, 2022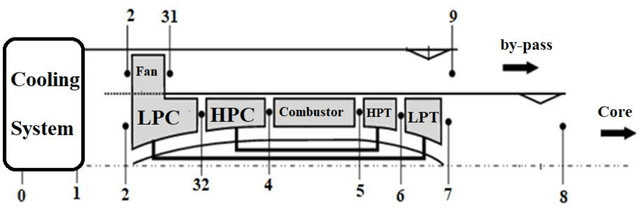
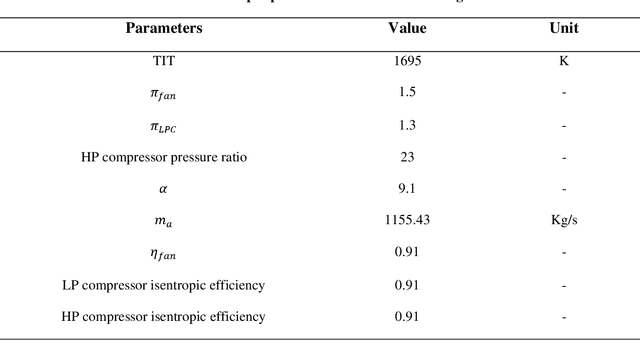
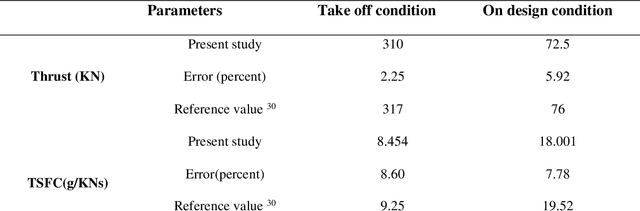
In this study, the effect of inlet air cooling and fuel type on the performance parameters of thrust-specific fuel consumption (TSFC), thermal and exergetic efficiencies, entropy generation rate, and Nitrogen oxide emission intensity index (SNOx) of the GENX 1B70 engine is analyzed in two states of take-off and on design. The results show that with a 20-degree delicious reduction in inlet air temperature on design conditions and JP10 fuel usage, the thermal efficiency and entropy generation rate, thrust and fuel mass flow rate, and TSFC of the engine increase by 1.85 percent, 16.51 percent, 11.76 percent, 10.53 percent, and 2.15 percent and SNOx and exergetic efficiency decrease by 2.11 percent and 26.60 percent, respectively. Also, optimization of the GENX 1B70 engine cycle as hydrogen fuel usage with three separate objective functions: thrust maximization, thermal efficiency maximization, and propulsive efficiency maximization on design point condition was performed based on the Genetic algorithm. Based on the economic approach and exero-environmental, the best cycles from the optimal states were selected using the TOPSIS algorithm. In on design conditions, entropy generation rate, nitrogen oxide production rate, and TSFC for the chosen cycle based on the economic approach +18.89 percent, +10.01 percent, and -0.21percent, respectively, and based on the exero-environmental approach -54.03percent, -42.02percent, and +21.44percent change compared to the base engine, respectively.
Cyclocopula Technique to Study the Relationship Between Two Cyclostationary Time Series with Fractional Brownian Motion Errors
Jun 16, 2022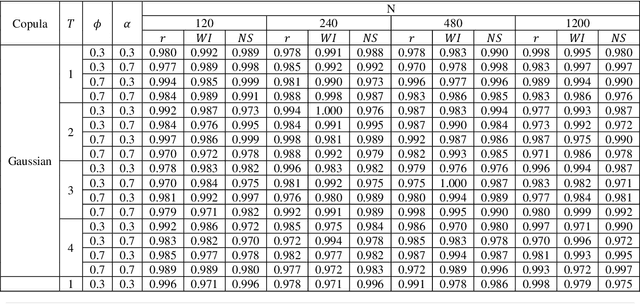
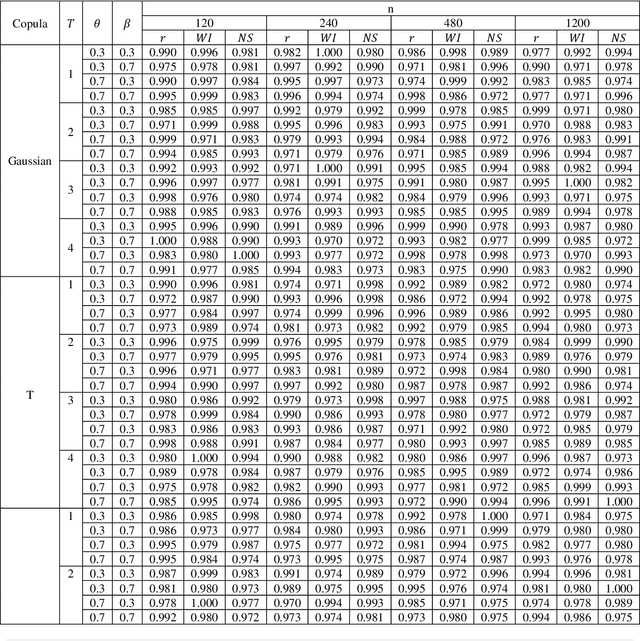
Detection of the relationship between two time series is so important in environmental and hydrological studies. Several parametric and non-parametric approaches can be applied to detect relationships. These techniques are usually sensitive to stationarity assumptions. In this research, a new copula-based method is introduced to detect the relationship between two cylostationary time series with fractional Brownian motion (fBm) errors. The numerical studies verify the performance of the introduced approach.
* 16 pages, t tables
Comparative analysis of machine learning and numerical modeling for combined heat transfer in Polymethylmethacrylate
Apr 12, 2022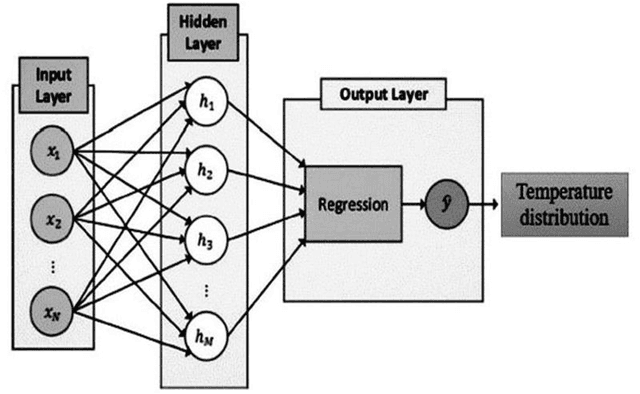
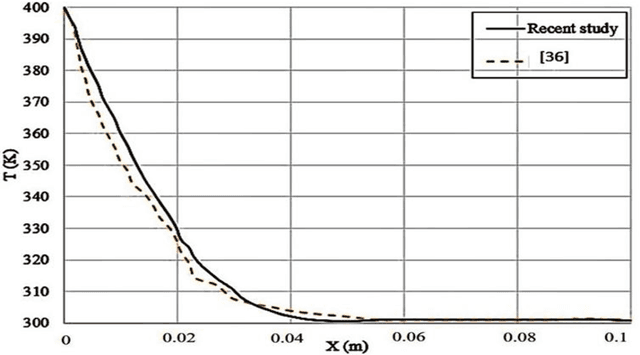
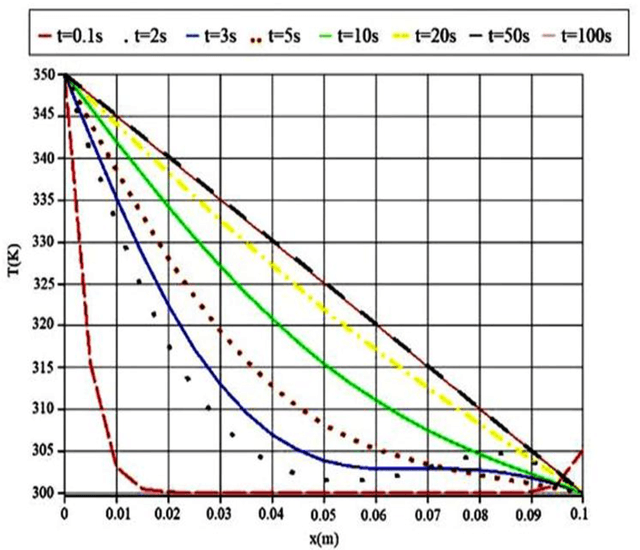
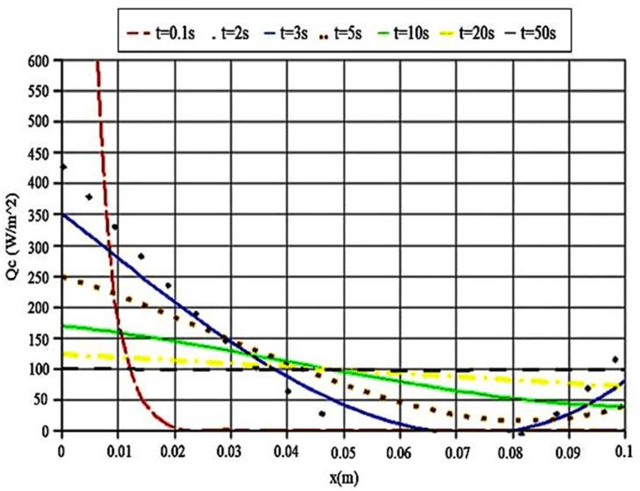
This study compares different methods to predict the simultaneous effects of conductive and radiative heat transfer in a Polymethylmethacrylate (PMMA) sample. PMMA is a kind of polymer utilized in various sensors and actuator devices. One-dimensional combined heat transfer is considered in numerical analysis. Computer implementation was obtained for the numerical solution of governing equation with the implicit finite difference method in the case of discretization. Kirchhoff transformation was used to get data from a non-linear equation of conductive heat transfer by considering monochromatic radiation intensity and temperature conditions applied to the PMMA sample boundaries. For Deep Neural Network (DNN) method, the novel Long Short Term Memory (LSTM) method was introduced to find accurate results in the least processing time than the numerical method. A recent study derived the combined heat transfers and their temperature profiles for the PMMA sample. Furthermore, the transient temperature profile is validated by another study. A comparison proves a perfect agreement. It shows the temperature gradient in the primary positions that makes a spectral amount of conductive heat transfer from a PMMA sample. It is more straightforward when they are compared with the novel DNN method. Results demonstrate that this artificial intelligence method is accurate and fast in predicting problems. By analyzing the results from the numerical solution it can be understood that the conductive and radiative heat flux is similar in the case of gradient behavior, but it is also twice in its amount approximately. Hence, total heat flux has a constant value in an approximated steady state condition. In addition to analyzing their composition, ROC curve and confusion matrix were implemented to evaluate the algorithm performance.
Accurate Discharge Coefficient Prediction of Streamlined Weirs by Coupling Linear Regression and Deep Convolutional Gated Recurrent Unit
Apr 12, 2022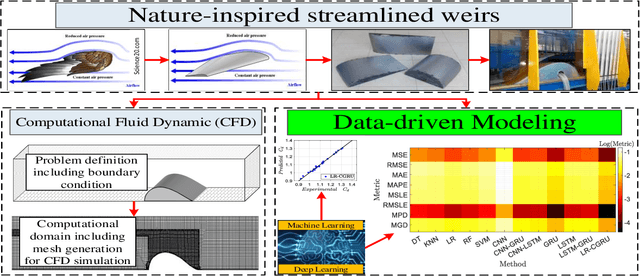
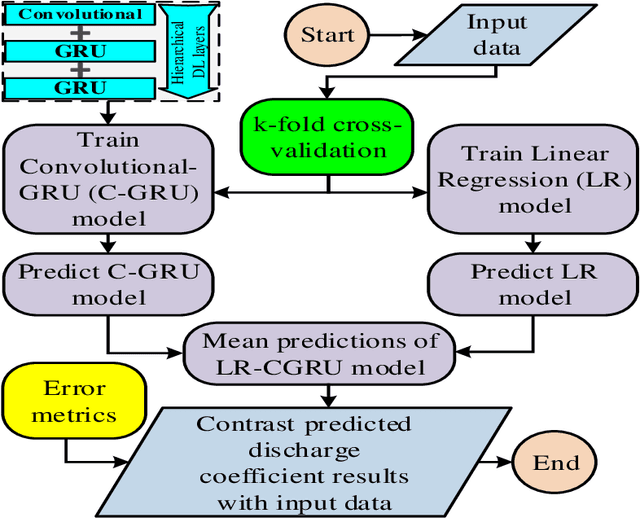
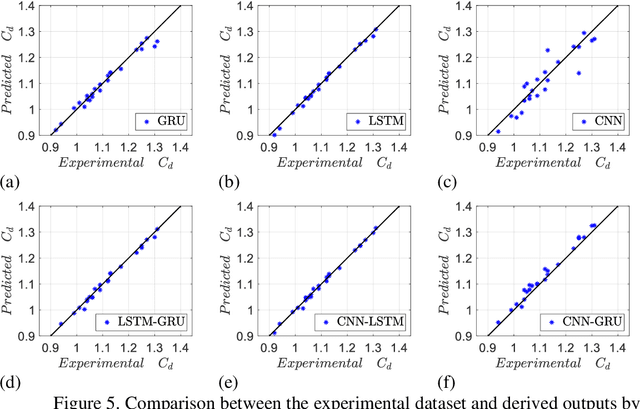
Streamlined weirs which are a nature-inspired type of weir have gained tremendous attention among hydraulic engineers, mainly owing to their established performance with high discharge coefficients. Computational fluid dynamics (CFD) is considered as a robust tool to predict the discharge coefficient. To bypass the computational cost of CFD-based assessment, the present study proposes data-driven modeling techniques, as an alternative to CFD simulation, to predict the discharge coefficient based on an experimental dataset. To this end, after splitting the dataset using a k fold cross validation technique, the performance assessment of classical and hybrid machine learning deep learning (ML DL) algorithms is undertaken. Among ML techniques linear regression (LR) random forest (RF) support vector machine (SVM) k-nearest neighbor (KNN) and decision tree (DT) algorithms are studied. In the context of DL, long short-term memory (LSTM) convolutional neural network (CNN) and gated recurrent unit (GRU) and their hybrid forms such as LSTM GRU, CNN LSTM and CNN GRU techniques, are compared using different error metrics. It is found that the proposed three layer hierarchical DL algorithm consisting of a convolutional layer coupled with two subsequent GRU levels, which is also hybridized with the LR method, leads to lower error metrics. This paper paves the way for data-driven modeling of streamlined weirs.
* 28 pages, 7 figures
Integration of neural network and fuzzy logic decision making compared with bilayered neural network in the simulation of daily dew point temperature
Feb 23, 2022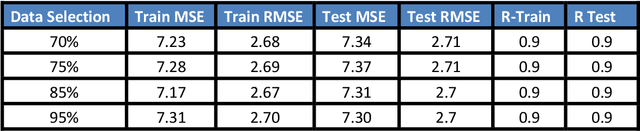
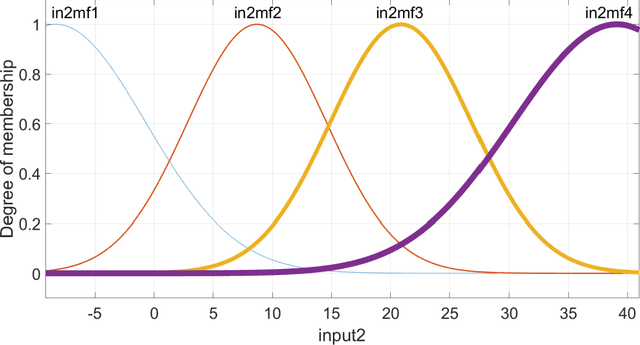
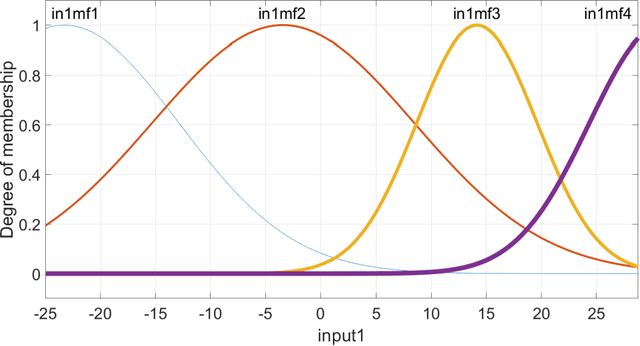
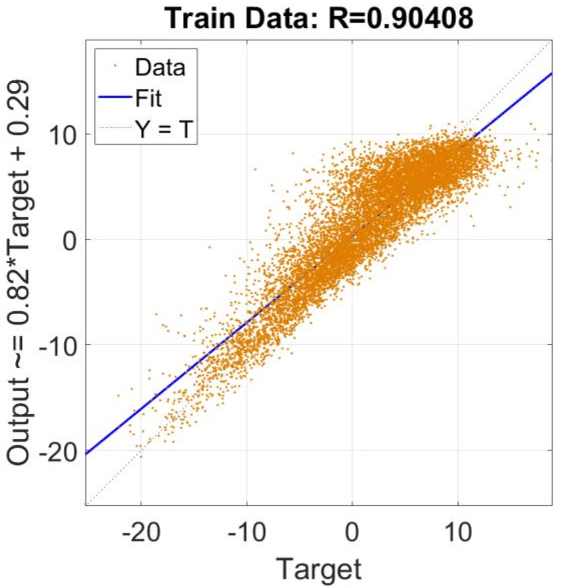
In this research, dew point temperature (DPT) is simulated using the data-driven approach. Adaptive Neuro-Fuzzy Inference System (ANFIS) is utilized as a data-driven technique to forecast this parameter at Tabriz in East Azerbaijan. Various input patterns, namely T min, T max, and T mean, are utilized for training the architecture whilst DPT is the model's output. The findings indicate that, in general, ANFIS method is capable of identifying data patterns with a high degree of accuracy. However, the approach demonstrates that processing time and computer resources may substantially increase by adding additional functions. Based on the results, the number of iterations and computing resources might change dramatically if new functionalities are included. As a result, tuning parameters have to be optimized inside the method framework. The findings demonstrate a high agreement between results by the data-driven technique (machine learning method) and the observed data. Using this prediction toolkit, DPT can be adequately forecasted solely based on the temperature distribution of Tabriz. This kind of modeling is extremely promising for predicting DPT at various sites. Besides, this study thoroughly compares the Bilayered Neural Network (BNN) and ANFIS models on various scales. Whilst the ANFIS model is extremely stable for almost all numbers of membership functions, the BNN model is highly sensitive to this scale factor to predict DPT.
GSVMA: A Genetic-Support Vector Machine-Anova method for CAD diagnosis based on Z-Alizadeh Sani dataset
Jul 23, 2021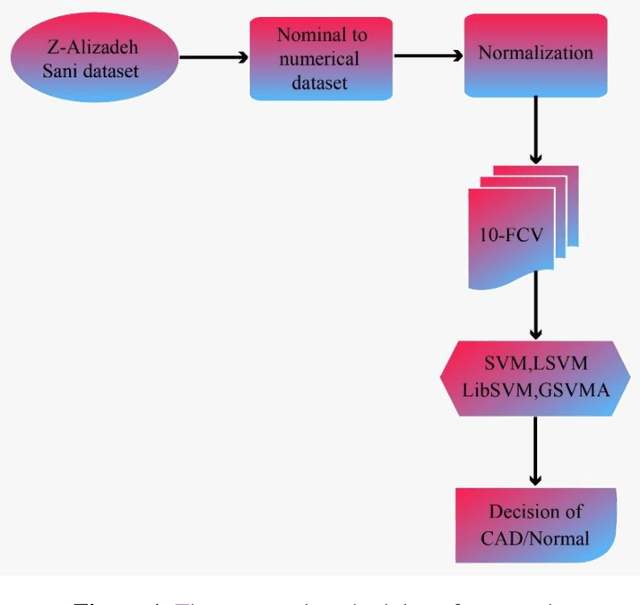
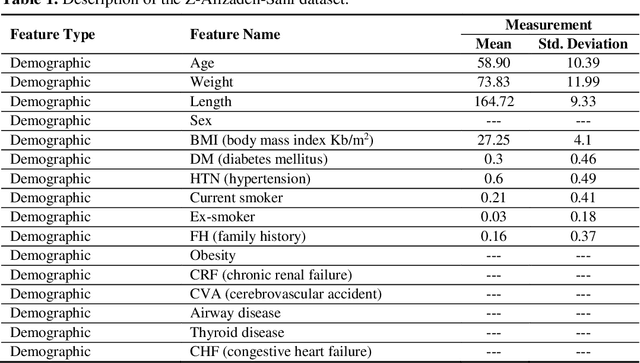
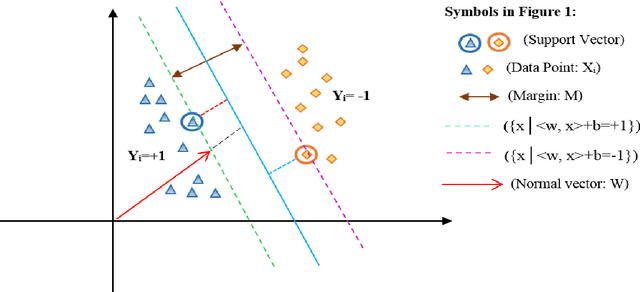

Coronary heart disease (CAD) is one of the crucial reasons for cardiovascular mortality in middle-aged people worldwide. The most typical tool is angiography for diagnosing CAD. The challenges of CAD diagnosis using angiography are costly and have side effects. One of the alternative solutions is the use of machine learning-based patterns for CAD diagnosis. Hence, this paper provides a new hybrid machine learning model called Genetic Support Vector Machine and Analysis of Variance (GSVMA). The ANOVA is known as the kernel function for SVM. The proposed model is performed based on the Z-Alizadeh Sani dataset. A genetic optimization algorithm is used to select crucial features. In addition, SVM with Anova, Linear SVM, and LibSVM with radial basis function methods were applied to classify the dataset. As a result, the GSVMA hybrid method performs better than other methods. This proposed method has the highest accuracy of 89.45% through a 10-fold cross-validation technique with 35 selected features on the Z-Alizadeh Sani dataset. Therefore, the genetic optimization algorithm is very effective for improving accuracy. The computer-aided GSVMA method can be helped clinicians with CAD diagnosis.