 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo-Reference Image Contrast Assessment with Customized EfficientNet-B0
Sep 26, 2025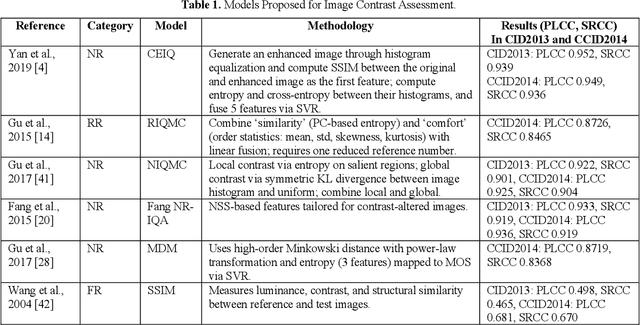
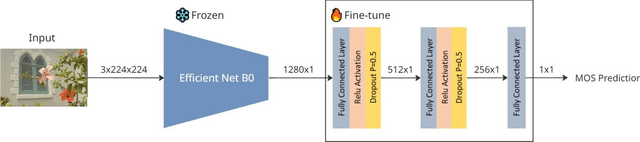
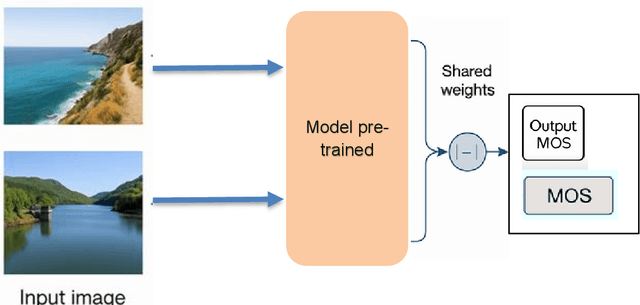

Image contrast was a fundamental factor in visual perception and played a vital role in overall image quality. However, most no reference image quality assessment NR IQA models struggled to accurately evaluate contrast distortions under diverse real world conditions. In this study, we proposed a deep learning based framework for blind contrast quality assessment by customizing and fine-tuning three pre trained architectures, EfficientNet B0, ResNet18, and MobileNetV2, for perceptual Mean Opinion Score, along with an additional model built on a Siamese network, which indicated a limited ability to capture perceptual contrast distortions. Each model is modified with a contrast-aware regression head and trained end to end using targeted data augmentations on two benchmark datasets, CID2013 and CCID2014, containing synthetic and authentic contrast distortions. Performance is evaluated using Pearson Linear Correlation Coefficient and Spearman Rank Order Correlation Coefficient, which assess the alignment between predicted and human rated scores. Among these three models, our customized EfficientNet B0 model achieved state-of-the-art performance with PLCC = 0.9286 and SRCC = 0.9178 on CCID2014 and PLCC = 0.9581 and SRCC = 0.9369 on CID2013, surpassing traditional methods and outperforming other deep baselines. These results highlighted the models robustness and effectiveness in capturing perceptual contrast distortion. Overall, the proposed method demonstrated that contrast aware adaptation of lightweight pre trained networks can yield a high performing, scalable solution for no reference contrast quality assessment suitable for real time and resource constrained applications.
Functional Classification of Spiking Signal Data Using Artificial Intelligence Techniques: A Review
Sep 26, 2024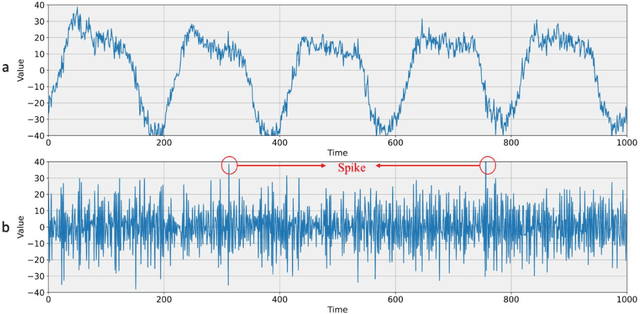
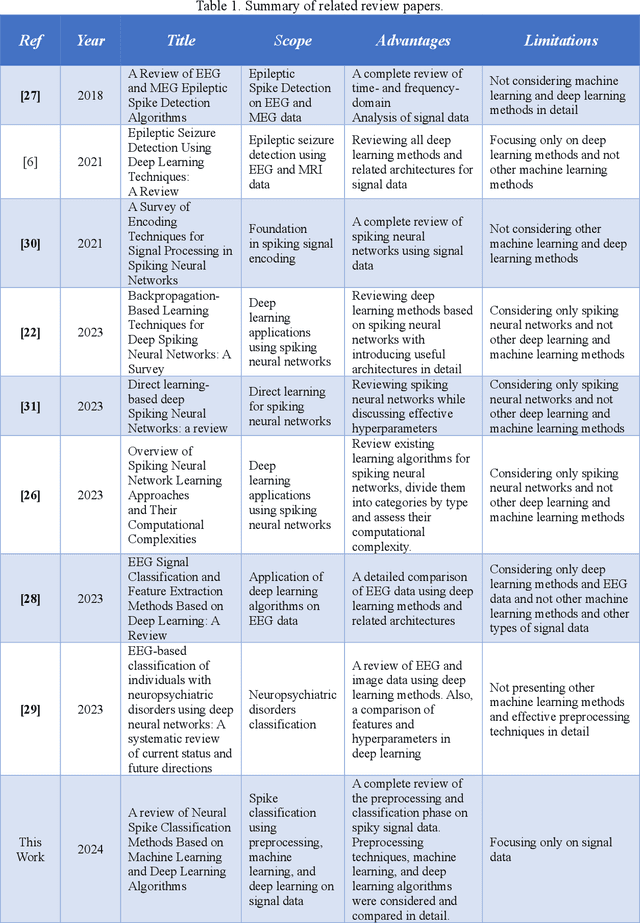
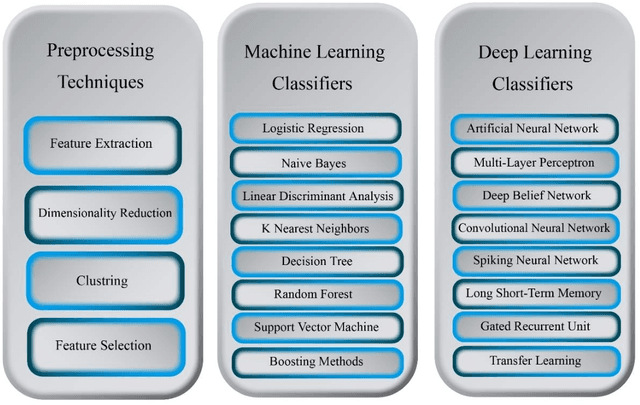
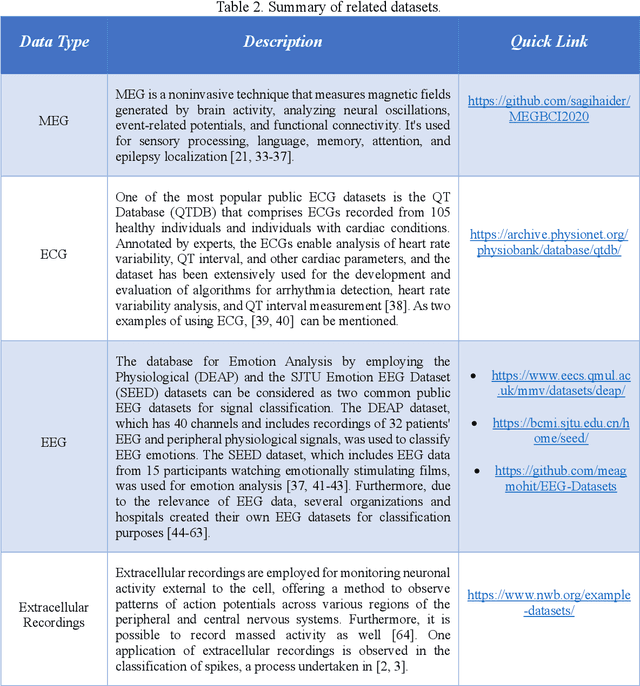
Human brain neuron activities are incredibly significant nowadays. Neuronal behavior is assessed by analyzing signal data such as electroencephalography (EEG), which can offer scientists valuable information about diseases and human-computer interaction. One of the difficulties researchers confront while evaluating these signals is the existence of large volumes of spike data. Spikes are some considerable parts of signal data that can happen as a consequence of vital biomarkers or physical issues such as electrode movements. Hence, distinguishing types of spikes is important. From this spot, the spike classification concept commences. Previously, researchers classified spikes manually. The manual classification was not precise enough as it involves extensive analysis. Consequently, Artificial Intelligence (AI) was introduced into neuroscience to assist clinicians in classifying spikes correctly. This review discusses the importance and use of AI in spike classification, focusing on the recognition of neural activity noises. The task is divided into three main components: preprocessing, classification, and evaluation. Existing methods are introduced and their importance is determined. The review also highlights the need for more efficient algorithms. The primary goal is to provide a perspective on spike classification for future research and provide a comprehensive understanding of the methodologies and issues involved. The review organizes materials in the spike classification field for future studies. In this work, numerous studies were extracted from different databases. The PRISMA-related research guidelines were then used to choose papers. Then, research studies based on spike classification using machine learning and deep learning approaches with effective preprocessing were selected.
Complex Emotion Recognition System using basic emotions via Facial Expression, EEG, and ECG Signals: a review
Sep 09, 2024
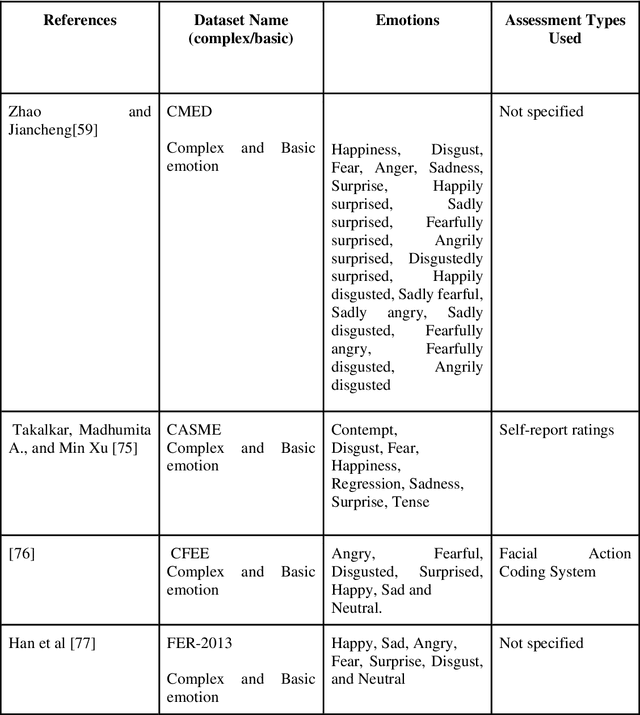

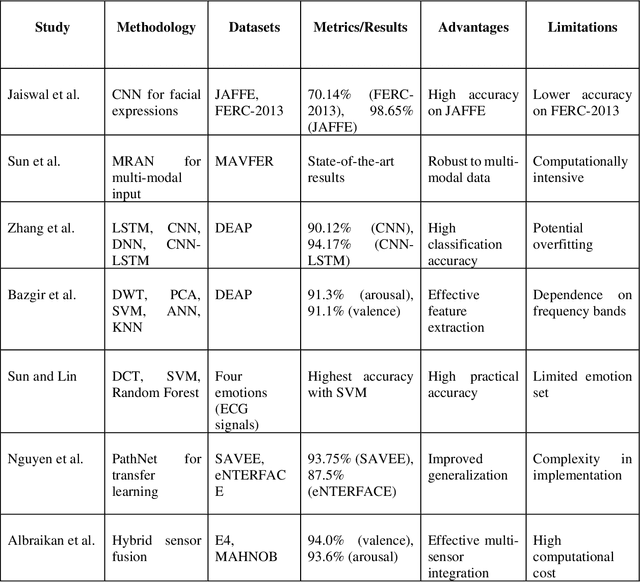
The Complex Emotion Recognition System (CERS) deciphers complex emotional states by examining combinations of basic emotions expressed, their interconnections, and the dynamic variations. Through the utilization of advanced algorithms, CERS provides profound insights into emotional dynamics, facilitating a nuanced understanding and customized responses. The attainment of such a level of emotional recognition in machines necessitates the knowledge distillation and the comprehension of novel concepts akin to human cognition. The development of AI systems for discerning complex emotions poses a substantial challenge with significant implications for affective computing. Furthermore, obtaining a sizable dataset for CERS proves to be a daunting task due to the intricacies involved in capturing subtle emotions, necessitating specialized methods for data collection and processing. Incorporating physiological signals such as Electrocardiogram (ECG) and Electroencephalogram (EEG) can notably enhance CERS by furnishing valuable insights into the user's emotional state, enhancing the quality of datasets, and fortifying system dependability. A comprehensive literature review was conducted in this study to assess the efficacy of machine learning, deep learning, and meta-learning approaches in both basic and complex emotion recognition utilizing EEG, ECG signals, and facial expression datasets. The chosen research papers offer perspectives on potential applications, clinical implications, and results of CERSs, with the objective of promoting their acceptance and integration into clinical decision-making processes. This study highlights research gaps and challenges in understanding CERSs, encouraging further investigation by relevant studies and organizations. Lastly, the significance of meta-learning approaches in improving CERS performance and guiding future research endeavors is underscored.
Malicious URL Detection using optimized Hist Gradient Boosting Classifier based on grid search method
Jun 12, 2024



Trusting the accuracy of data inputted on online platforms can be difficult due to the possibility of malicious websites gathering information for unlawful reasons. Analyzing each website individually becomes challenging with the presence of such malicious sites, making it hard to efficiently list all Uniform Resource Locators (URLs) on a blacklist. This ongoing challenge emphasizes the crucial need for strong security measures to safeguard against potential threats and unauthorized data collection. To detect the risk posed by malicious websites, it is proposed to utilize Machine Learning (ML)-based techniques. To this, we used several ML techniques such as Hist Gradient Boosting Classifier (HGBC), K-Nearest Neighbor (KNN), Logistic Regression (LR), Decision Tree (DT), Random Forest (RF), Multi-Layer Perceptron (MLP), Light Gradient Boosting Machine (LGBM), and Support Vector Machine (SVM) for detection of the benign and malicious website dataset. The dataset used contains 1781 records of malicious and benign website data with 13 features. First, we investigated missing value imputation on the dataset. Then, we normalized this data by scaling to a range of zero and one. Next, we utilized the Synthetic Minority Oversampling Technique (SMOTE) to balance the training data since the data set was unbalanced. After that, we applied ML algorithms to the balanced training set. Meanwhile, all algorithms were optimized based on grid search. Finally, the models were evaluated based on accuracy, precision, recall, F1 score, and the Area Under the Curve (AUC) metrics. The results demonstrated that the HGBC classifier has the best performance in terms of the mentioned metrics compared to the other classifiers.
FRA: A novel Face Representation Augmentation algorithm for face recognition
Jan 27, 2023



A low amount of training data for many state-of-the-art deep learning-based Face Recognition (FR) systems causes a marked deterioration in their performance. Although a considerable amount of research has addressed this issue by inventing new data augmentation techniques, using either input space transformations or Generative Adversarial Networks (GAN) for feature space augmentations, these techniques have yet to satisfy expectations. In this paper, we propose a novel method, named the Face Representation Augmentation (FRA) algorithm, for augmenting face datasets. To the best of our knowledge, FRA is the first method that shifts its focus towards manipulating the face embeddings generated by any face representation learning algorithm in order to generate new embeddings representing the same identity and facial emotion but with an altered posture. Extensive experiments conducted in this study convince the efficacy of our methodology and its power to provide noiseless, completely new facial representations to improve the training procedure of any FR algorithm. Therefore, FRA is able to help the recent state-of-the-art FR methods by providing more data for training FR systems. The proposed method, using experiments conducted on the Karolinska Directed Emotional Faces (KDEF) dataset, improves the identity classification accuracies by 9.52 %, 10.04 %, and 16.60 %, in comparison with the base models of MagFace, ArcFace, and CosFace, respectively.
BERT-Deep CNN: State-of-the-Art for Sentiment Analysis of COVID-19 Tweets
Nov 04, 2022The free flow of information has been accelerated by the rapid development of social media technology. There has been a significant social and psychological impact on the population due to the outbreak of Coronavirus disease (COVID-19). The COVID-19 pandemic is one of the current events being discussed on social media platforms. In order to safeguard societies from this pandemic, studying people's emotions on social media is crucial. As a result of their particular characteristics, sentiment analysis of texts like tweets remains challenging. Sentiment analysis is a powerful text analysis tool. It automatically detects and analyzes opinions and emotions from unstructured data. Texts from a wide range of sources are examined by a sentiment analysis tool, which extracts meaning from them, including emails, surveys, reviews, social media posts, and web articles. To evaluate sentiments, natural language processing (NLP) and machine learning techniques are used, which assign weights to entities, topics, themes, and categories in sentences or phrases. Machine learning tools learn how to detect sentiment without human intervention by examining examples of emotions in text. In a pandemic situation, analyzing social media texts to uncover sentimental trends can be very helpful in gaining a better understanding of society's needs and predicting future trends. We intend to study society's perception of the COVID-19 pandemic through social media using state-of-the-art BERT and Deep CNN models. The superiority of BERT models over other deep models in sentiment analysis is evident and can be concluded from the comparison of the various research studies mentioned in this article.
Resource allocation optimization using artificial intelligence methods in various computing paradigms: A Review
Mar 23, 2022
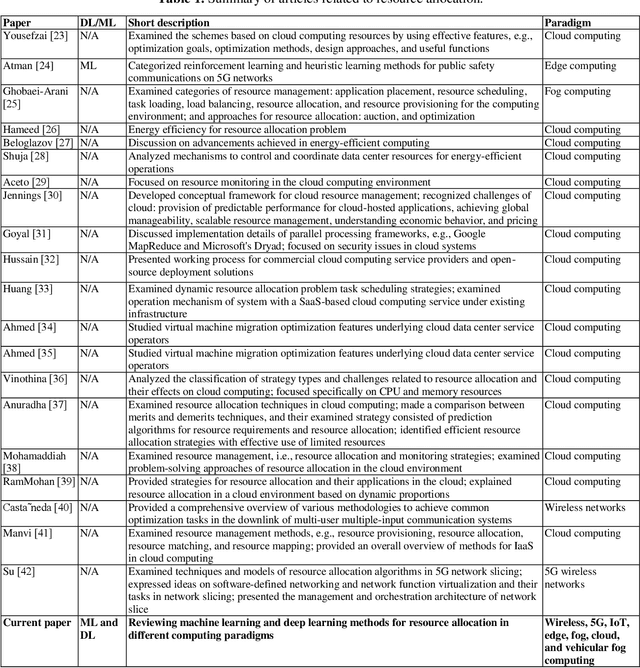
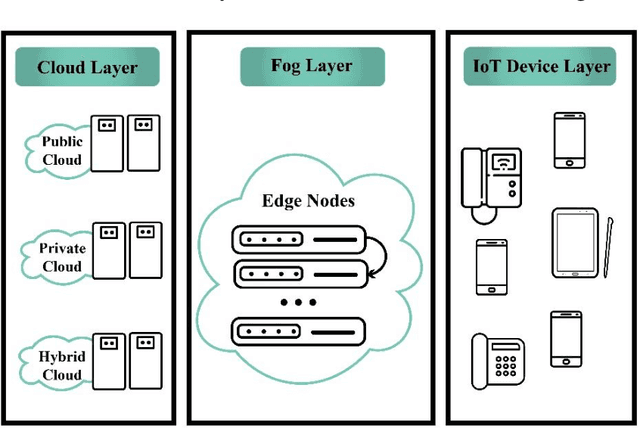
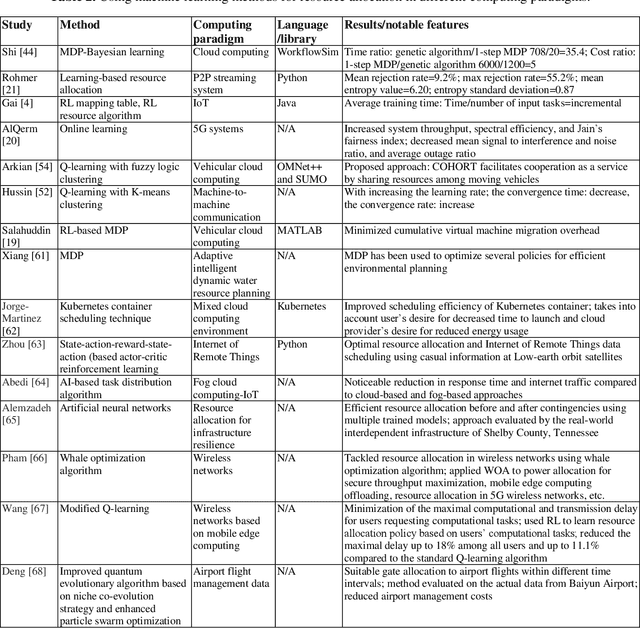
With the advent of smart devices, the demand for various computational paradigms such as the Internet of Things, fog, and cloud computing has increased. However, effective resource allocation remains challenging in these paradigms. This paper presents a comprehensive literature review on the application of artificial intelligence (AI) methods such as deep learning (DL) and machine learning (ML) for resource allocation optimization in computational paradigms. To the best of our knowledge, there are no existing reviews on AI-based resource allocation approaches in different computational paradigms. The reviewed ML-based approaches are categorized as supervised and reinforcement learning (RL). Moreover, DL-based approaches and their combination with RL are surveyed. The review ends with a discussion on open research directions and a conclusion.
FCM-DNN: diagnosing coronary artery disease by deep accuracy Fuzzy C-Means clustering model
Feb 28, 2022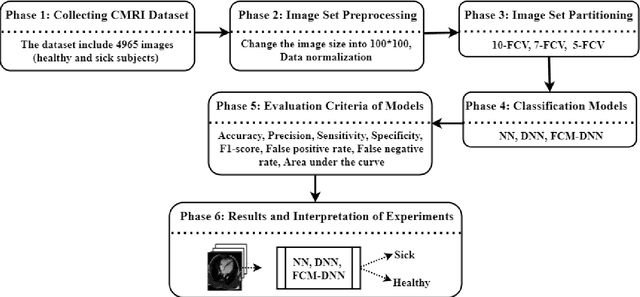

Cardiovascular disease is one of the most challenging diseases in middle-aged and older people, which causes high mortality. Coronary artery disease (CAD) is known as a common cardiovascular disease. A standard clinical tool for diagnosing CAD is angiography. The main challenges are dangerous side effects and high angiography costs. Today, the development of artificial intelligence-based methods is a valuable achievement for diagnosing disease. Hence, in this paper, artificial intelligence methods such as neural network (NN), deep neural network (DNN), and Fuzzy C-Means clustering combined with deep neural network (FCM-DNN) are developed for diagnosing CAD on a cardiac magnetic resonance imaging (CMRI) dataset. The original dataset is used in two different approaches. First, the labeled dataset is applied to the NN and DNN to create the NN and DNN models. Second, the labels are removed, and the unlabeled dataset is clustered via the FCM method, and then, the clustered dataset is fed to the DNN to create the FCM-DNN model. By utilizing the second clustering and modeling, the training process is improved, and consequently, the accuracy is increased. As a result, the proposed FCM-DNN model achieves the best performance with a 99.91% accuracy specifying 10 clusters, i.e., 5 clusters for healthy subjects and 5 clusters for sick subjects, through the 10-fold cross-validation technique compared to the NN and DNN models reaching the accuracies of 92.18% and 99.63%, respectively. To the best of our knowledge, no study has been conducted for CAD diagnosis on the CMRI dataset using artificial intelligence methods. The results confirm that the proposed FCM-DNN model can be helpful for scientific and research centers.
GSVMA: A Genetic-Support Vector Machine-Anova method for CAD diagnosis based on Z-Alizadeh Sani dataset
Jul 23, 2021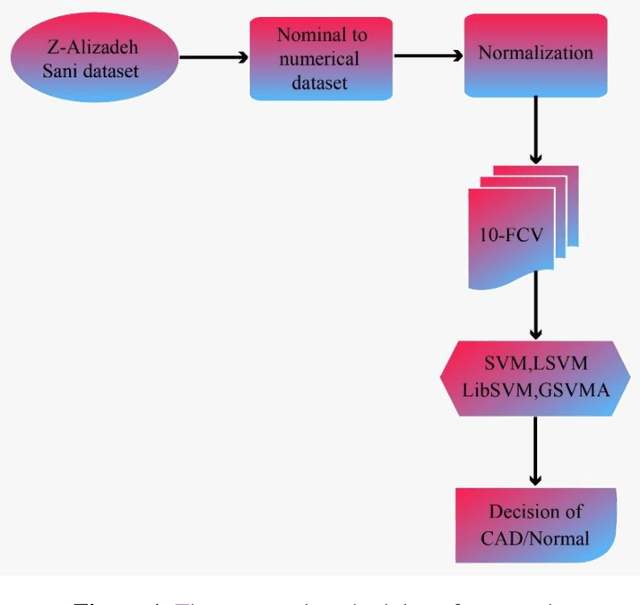
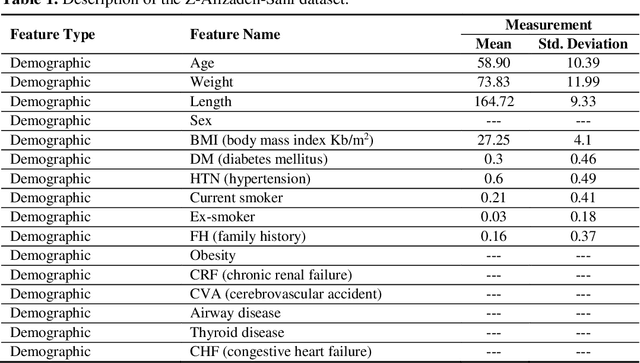
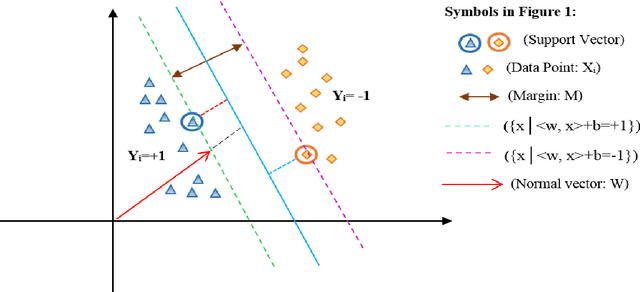

Coronary heart disease (CAD) is one of the crucial reasons for cardiovascular mortality in middle-aged people worldwide. The most typical tool is angiography for diagnosing CAD. The challenges of CAD diagnosis using angiography are costly and have side effects. One of the alternative solutions is the use of machine learning-based patterns for CAD diagnosis. Hence, this paper provides a new hybrid machine learning model called Genetic Support Vector Machine and Analysis of Variance (GSVMA). The ANOVA is known as the kernel function for SVM. The proposed model is performed based on the Z-Alizadeh Sani dataset. A genetic optimization algorithm is used to select crucial features. In addition, SVM with Anova, Linear SVM, and LibSVM with radial basis function methods were applied to classify the dataset. As a result, the GSVMA hybrid method performs better than other methods. This proposed method has the highest accuracy of 89.45% through a 10-fold cross-validation technique with 35 selected features on the Z-Alizadeh Sani dataset. Therefore, the genetic optimization algorithm is very effective for improving accuracy. The computer-aided GSVMA method can be helped clinicians with CAD diagnosis.
A Survey of Applications of Artificial Intelligence for Myocardial Infarction Disease Diagnosis
Jul 05, 2021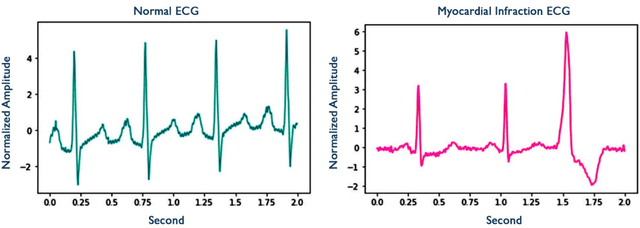


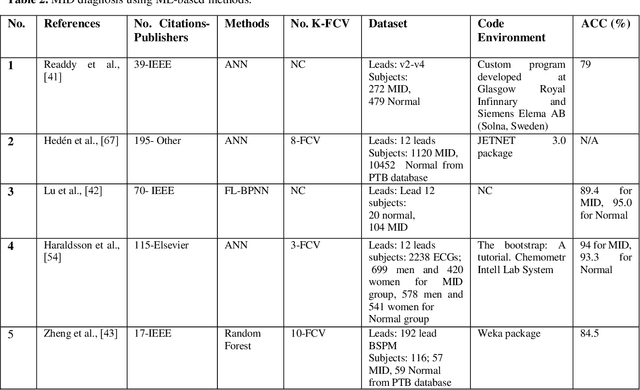
Myocardial infarction disease (MID) is caused to the rapid progress of undiagnosed coronary artery disease (CAD) that indicates the injury of a heart cell by decreasing the blood flow to the cardiac muscles. MID is the leading cause of death in middle-aged and elderly subjects all over the world. In general, raw Electrocardiogram (ECG) signals are tested for MID identification by clinicians that is exhausting, time-consuming, and expensive. Artificial intelligence-based methods are proposed to handle the problems to diagnose MID on the ECG signals automatically. Hence, in this survey paper, artificial intelligence-based methods, including machine learning and deep learning, are review for MID diagnosis on the ECG signals. Using the methods demonstrate that the feature extraction and selection of ECG signals required to be handcrafted in the ML methods. In contrast, these tasks are explored automatically in the DL methods. Based on our best knowledge, Deep Convolutional Neural Network (DCNN) methods are highly required methods developed for the early diagnosis of MID on the ECG signals. Most researchers have tended to use DCNN methods, and no studies have surveyed using artificial intelligence methods for MID diagnosis on the ECG signals.