 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Student Knowledge Modeling for Future Learning Resource Prediction
May 20, 2025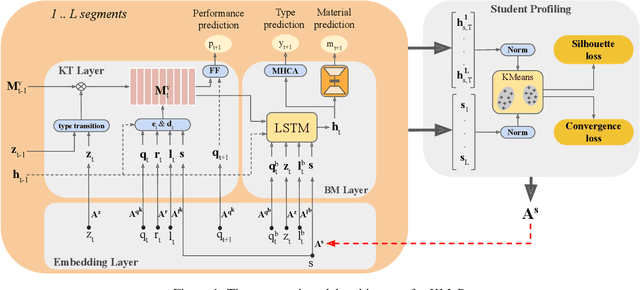

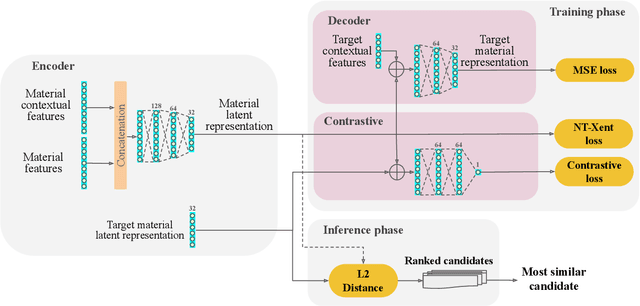
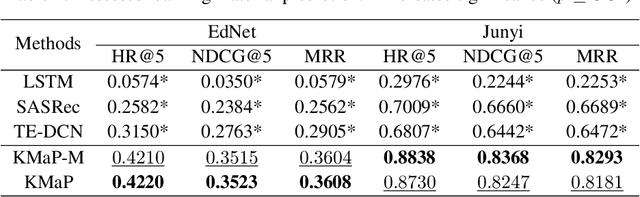
Despite advances in deep learning for education, student knowledge tracing and behavior modeling face persistent challenges: limited personalization, inadequate modeling of diverse learning activities (especially non-assessed materials), and overlooking the interplay between knowledge acquisition and behavioral patterns. Practical limitations, such as fixed-size sequence segmentation, frequently lead to the loss of contextual information vital for personalized learning. Moreover, reliance on student performance on assessed materials limits the modeling scope, excluding non-assessed interactions like lectures. To overcome these shortcomings, we propose Knowledge Modeling and Material Prediction (KMaP), a stateful multi-task approach designed for personalized and simultaneous modeling of student knowledge and behavior. KMaP employs clustering-based student profiling to create personalized student representations, improving predictions of future learning resource preferences. Extensive experiments on two real-world datasets confirm significant behavioral differences across student clusters and validate the efficacy of the KMaP model.
Mitigating Backdoors within Deep Neural Networks in Data-limited Configuration
Nov 13, 2023


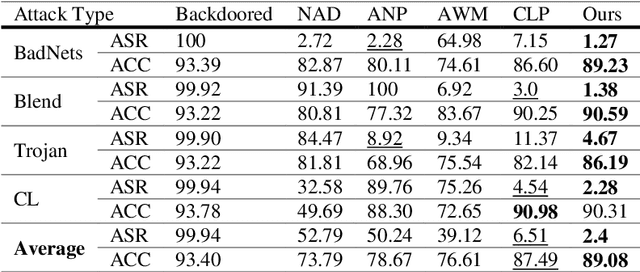
As the capacity of deep neural networks (DNNs) increases, their need for huge amounts of data significantly grows. A common practice is to outsource the training process or collect more data over the Internet, which introduces the risks of a backdoored DNN. A backdoored DNN shows normal behavior on clean data while behaving maliciously once a trigger is injected into a sample at the test time. In such cases, the defender faces multiple difficulties. First, the available clean dataset may not be sufficient for fine-tuning and recovering the backdoored DNN. Second, it is impossible to recover the trigger in many real-world applications without information about it. In this paper, we formulate some characteristics of poisoned neurons. This backdoor suspiciousness score can rank network neurons according to their activation values, weights, and their relationship with other neurons in the same layer. Our experiments indicate the proposed method decreases the chance of attacks being successful by more than 50% with a tiny clean dataset, i.e., ten clean samples for the CIFAR-10 dataset, without significantly deteriorating the model's performance. Moreover, the proposed method runs three times as fast as baselines.
Path Analysis for Effective Fault Localization in Deep Neural Networks
Nov 06, 2023



Deep learning has revolutionized various real-world applications, but the quality of Deep Neural Networks (DNNs) remains a concern. DNNs are complex and have millions of parameters, making it difficult to determine their contributions to fulfilling a task. Moreover, the behavior of a DNN is highly influenced by the data used during training, making it challenging to collect enough data to exercise all potential DNN behavior under all possible scenarios. This paper proposes NP SBFL method to locate faulty neural pathways (NP) using spectrum-based fault localization (SBFL). Our method identifies critical neurons using the layer-wise relevance propagation (LRP) technique and determines which critical neurons are faulty. Moreover, we propose a multi-stage gradient ascent (MGA), an extension of gradient ascent (GA), to effectively activate a sequence of neurons one at a time while maintaining the activation of previous neurons, so we are able to test the reported faulty pathways. We evaluated the effectiveness of our method, i.e. NP-SBFL-MGA, on two commonly used datasets, MNIST and CIFAR-10, two baselines DeepFault and NP-SBFL-GA, and three suspicious neuron measures, Tarantula, Ochiai, and Barinel. The empirical results showed that NP-SBFL-MGA is statistically more effective than the baselines at identifying suspicious paths and synthesizing adversarial inputs. Particularly, Tarantula on NP-SBFL-MGA had the highest fault detection rate at 96.75%, surpassing DeepFault on Ochiai (89.90%) and NP-SBFL-GA on Ochiai (60.61%). Our approach also yielded comparable results to the baselines in synthesizing naturalness inputs, and we found a positive correlation between the coverage of critical paths and the number of failed tests in DNN fault localization.
FRA: A novel Face Representation Augmentation algorithm for face recognition
Jan 27, 2023



A low amount of training data for many state-of-the-art deep learning-based Face Recognition (FR) systems causes a marked deterioration in their performance. Although a considerable amount of research has addressed this issue by inventing new data augmentation techniques, using either input space transformations or Generative Adversarial Networks (GAN) for feature space augmentations, these techniques have yet to satisfy expectations. In this paper, we propose a novel method, named the Face Representation Augmentation (FRA) algorithm, for augmenting face datasets. To the best of our knowledge, FRA is the first method that shifts its focus towards manipulating the face embeddings generated by any face representation learning algorithm in order to generate new embeddings representing the same identity and facial emotion but with an altered posture. Extensive experiments conducted in this study convince the efficacy of our methodology and its power to provide noiseless, completely new facial representations to improve the training procedure of any FR algorithm. Therefore, FRA is able to help the recent state-of-the-art FR methods by providing more data for training FR systems. The proposed method, using experiments conducted on the Karolinska Directed Emotional Faces (KDEF) dataset, improves the identity classification accuracies by 9.52 %, 10.04 %, and 16.60 %, in comparison with the base models of MagFace, ArcFace, and CosFace, respectively.