 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Requirements Testability Measurement Based on Requirement Smells
Mar 26, 2024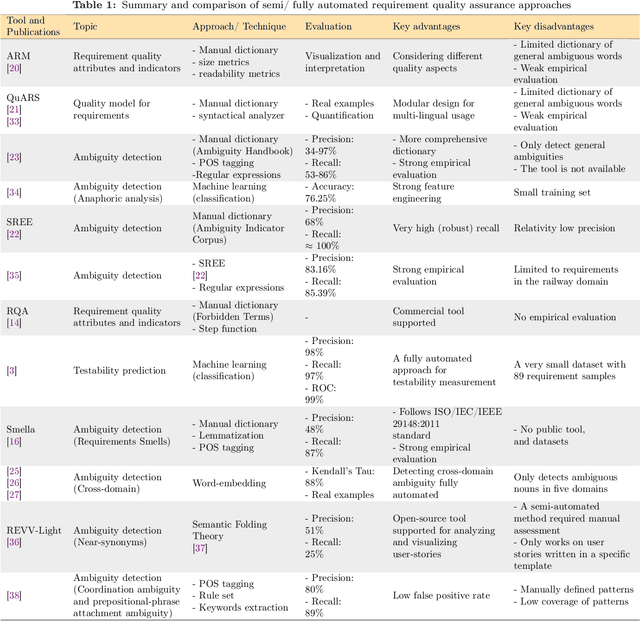



Requirements form the basis for defining software systems' obligations and tasks. Testable requirements help prevent failures, reduce maintenance costs, and make it easier to perform acceptance tests. However, despite the importance of measuring and quantifying requirements testability, no automatic approach for measuring requirements testability has been proposed based on the requirements smells, which are at odds with the requirements testability. This paper presents a mathematical model to evaluate and rank the natural language requirements testability based on an extensive set of nine requirements smells, detected automatically, and acceptance test efforts determined by requirement length and its application domain. Most of the smells stem from uncountable adjectives, context-sensitive, and ambiguous words. A comprehensive dictionary is required to detect such words. We offer a neural word-embedding technique to generate such a dictionary automatically. Using the dictionary, we could automatically detect Polysemy smell (domain-specific ambiguity) for the first time in 10 application domains. Our empirical study on nearly 1000 software requirements from six well-known industrial and academic projects demonstrates that the proposed smell detection approach outperforms Smella, a state-of-the-art tool, in detecting requirements smells. The precision and recall of smell detection are improved with an average of 0.03 and 0.33, respectively, compared to the state-of-the-art. The proposed requirement testability model measures the testability of 985 requirements with a mean absolute error of 0.12 and a mean squared error of 0.03, demonstrating the model's potential for practical use.
Mitigating Backdoors within Deep Neural Networks in Data-limited Configuration
Nov 13, 2023


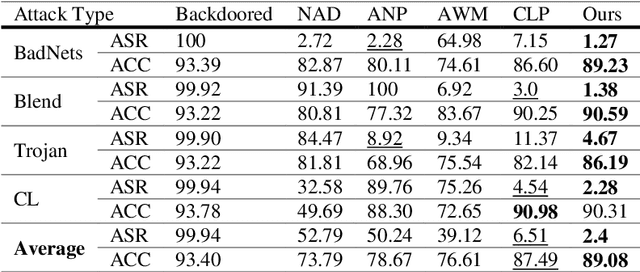
As the capacity of deep neural networks (DNNs) increases, their need for huge amounts of data significantly grows. A common practice is to outsource the training process or collect more data over the Internet, which introduces the risks of a backdoored DNN. A backdoored DNN shows normal behavior on clean data while behaving maliciously once a trigger is injected into a sample at the test time. In such cases, the defender faces multiple difficulties. First, the available clean dataset may not be sufficient for fine-tuning and recovering the backdoored DNN. Second, it is impossible to recover the trigger in many real-world applications without information about it. In this paper, we formulate some characteristics of poisoned neurons. This backdoor suspiciousness score can rank network neurons according to their activation values, weights, and their relationship with other neurons in the same layer. Our experiments indicate the proposed method decreases the chance of attacks being successful by more than 50% with a tiny clean dataset, i.e., ten clean samples for the CIFAR-10 dataset, without significantly deteriorating the model's performance. Moreover, the proposed method runs three times as fast as baselines.
Path Analysis for Effective Fault Localization in Deep Neural Networks
Nov 06, 2023



Deep learning has revolutionized various real-world applications, but the quality of Deep Neural Networks (DNNs) remains a concern. DNNs are complex and have millions of parameters, making it difficult to determine their contributions to fulfilling a task. Moreover, the behavior of a DNN is highly influenced by the data used during training, making it challenging to collect enough data to exercise all potential DNN behavior under all possible scenarios. This paper proposes NP SBFL method to locate faulty neural pathways (NP) using spectrum-based fault localization (SBFL). Our method identifies critical neurons using the layer-wise relevance propagation (LRP) technique and determines which critical neurons are faulty. Moreover, we propose a multi-stage gradient ascent (MGA), an extension of gradient ascent (GA), to effectively activate a sequence of neurons one at a time while maintaining the activation of previous neurons, so we are able to test the reported faulty pathways. We evaluated the effectiveness of our method, i.e. NP-SBFL-MGA, on two commonly used datasets, MNIST and CIFAR-10, two baselines DeepFault and NP-SBFL-GA, and three suspicious neuron measures, Tarantula, Ochiai, and Barinel. The empirical results showed that NP-SBFL-MGA is statistically more effective than the baselines at identifying suspicious paths and synthesizing adversarial inputs. Particularly, Tarantula on NP-SBFL-MGA had the highest fault detection rate at 96.75%, surpassing DeepFault on Ochiai (89.90%) and NP-SBFL-GA on Ochiai (60.61%). Our approach also yielded comparable results to the baselines in synthesizing naturalness inputs, and we found a positive correlation between the coverage of critical paths and the number of failed tests in DNN fault localization.
A systematic literature review on source code similarity measurement and clone detection: techniques, applications, and challenges
Jun 28, 2023Measuring and evaluating source code similarity is a fundamental software engineering activity that embraces a broad range of applications, including but not limited to code recommendation, duplicate code, plagiarism, malware, and smell detection. This paper proposes a systematic literature review and meta-analysis on code similarity measurement and evaluation techniques to shed light on the existing approaches and their characteristics in different applications. We initially found over 10000 articles by querying four digital libraries and ended up with 136 primary studies in the field. The studies were classified according to their methodology, programming languages, datasets, tools, and applications. A deep investigation reveals 80 software tools, working with eight different techniques on five application domains. Nearly 49% of the tools work on Java programs and 37% support C and C++, while there is no support for many programming languages. A noteworthy point was the existence of 12 datasets related to source code similarity measurement and duplicate codes, of which only eight datasets were publicly accessible. The lack of reliable datasets, empirical evaluations, hybrid methods, and focuses on multi-paradigm languages are the main challenges in the field. Emerging applications of code similarity measurement concentrate on the development phase in addition to the maintenance.
A systematic literature review on the code smells datasets and validation mechanisms
Jun 02, 2023



The accuracy reported for code smell-detecting tools varies depending on the dataset used to evaluate the tools. Our survey of 45 existing datasets reveals that the adequacy of a dataset for detecting smells highly depends on relevant properties such as the size, severity level, project types, number of each type of smell, number of smells, and the ratio of smelly to non-smelly samples in the dataset. Most existing datasets support God Class, Long Method, and Feature Envy while six smells in Fowler and Beck's catalog are not supported by any datasets. We conclude that existing datasets suffer from imbalanced samples, lack of supporting severity level, and restriction to Java language.
* 34 pages, 10 figures, 12 tables, Accepted
An ensemble meta-estimator to predict source code testability
Aug 24, 2022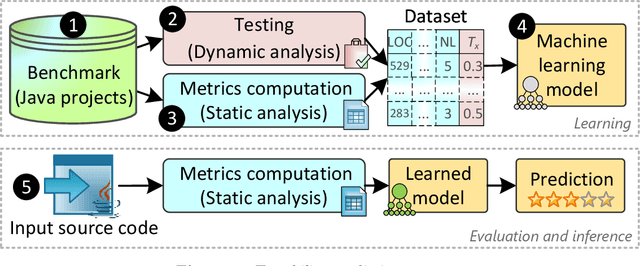
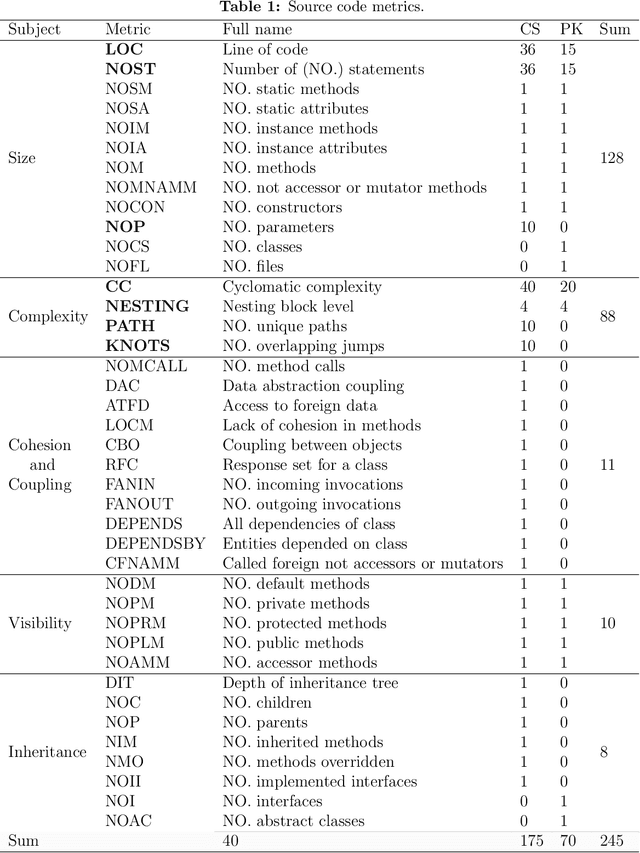


Unlike most other software quality attributes, testability cannot be evaluated solely based on the characteristics of the source code. The effectiveness of the test suite and the budget assigned to the test highly impact the testability of the code under test. The size of a test suite determines the test effort and cost, while the coverage measure indicates the test effectiveness. Therefore, testability can be measured based on the coverage and number of test cases provided by a test suite, considering the test budget. This paper offers a new equation to estimate testability regarding the size and coverage of a given test suite. The equation has been used to label 23,000 classes belonging to 110 Java projects with their testability measure. The labeled classes were vectorized using 262 metrics. The labeled vectors were fed into a family of supervised machine learning algorithms, regression, to predict testability in terms of the source code metrics. Regression models predicted testability with an R2 of 0.68 and a mean squared error of 0.03, suitable in practice. Fifteen software metrics highly affecting testability prediction were identified using a feature importance analysis technique on the learned model. The proposed models have improved mean absolute error by 38% due to utilizing new criteria, metrics, and data compared with the relevant study on predicting branch coverage as a test criterion. As an application of testability prediction, it is demonstrated that automated refactoring of 42 smelly Java classes targeted at improving the 15 influential software metrics could elevate their testability by an average of 86.87%.
* 52 pages, 11 figures, 11 tables
Learning to predict test effectiveness
Aug 20, 2022The high cost of the test can be dramatically reduced, provided that the coverability as an inherent feature of the code under test is predictable. This article offers a machine learning model to predict the extent to which the test could cover a class in terms of a new metric called Coverageability. The prediction model consists of an ensemble of four regression models. The learning samples consist of feature vectors, where features are source code metrics computed for a class. The samples are labeled by the Coverageability values computed for their corresponding classes. We offer a mathematical model to evaluate test effectiveness in terms of size and coverage of the test suite generated automatically for each class. We extend the size of the feature space by introducing a new approach to defining sub-metrics in terms of existing source code metrics. Using feature importance analysis on the learned prediction models, we sort source code metrics in the order of their impact on the test effectiveness. As a result of which, we found the class strict cyclomatic complexity as the most influential source code metric. Our experiments with the prediction models on a large corpus of Java projects containing about 23,000 classes demonstrate the Mean Absolute Error (MAE) of 0.032, Mean Squared Error (MSE) of 0.004, and an R2-score of 0.855. Compared with the state-of-the-art coverage prediction models, our models improve MAE, MSE, and an R2-score by 5.78%, 2.84%, and 20.71%, respectively.
* 19 pages, 11 figures