 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Requirements Testability Measurement Based on Requirement Smells
Paper and Code
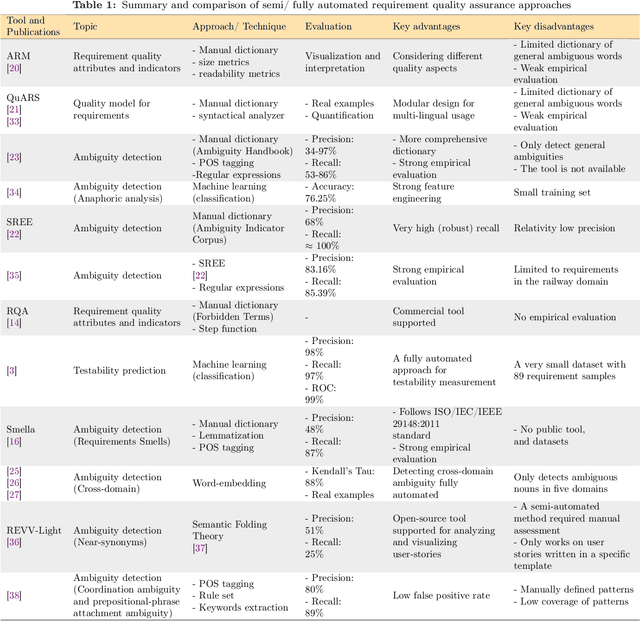



Requirements form the basis for defining software systems' obligations and tasks. Testable requirements help prevent failures, reduce maintenance costs, and make it easier to perform acceptance tests. However, despite the importance of measuring and quantifying requirements testability, no automatic approach for measuring requirements testability has been proposed based on the requirements smells, which are at odds with the requirements testability. This paper presents a mathematical model to evaluate and rank the natural language requirements testability based on an extensive set of nine requirements smells, detected automatically, and acceptance test efforts determined by requirement length and its application domain. Most of the smells stem from uncountable adjectives, context-sensitive, and ambiguous words. A comprehensive dictionary is required to detect such words. We offer a neural word-embedding technique to generate such a dictionary automatically. Using the dictionary, we could automatically detect Polysemy smell (domain-specific ambiguity) for the first time in 10 application domains. Our empirical study on nearly 1000 software requirements from six well-known industrial and academic projects demonstrates that the proposed smell detection approach outperforms Smella, a state-of-the-art tool, in detecting requirements smells. The precision and recall of smell detection are improved with an average of 0.03 and 0.33, respectively, compared to the state-of-the-art. The proposed requirement testability model measures the testability of 985 requirements with a mean absolute error of 0.12 and a mean squared error of 0.03, demonstrating the model's potential for practical use.