 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Questions to Insights: Exploring XAI Challenges Reported on Stack Overflow Questions
Apr 03, 2025

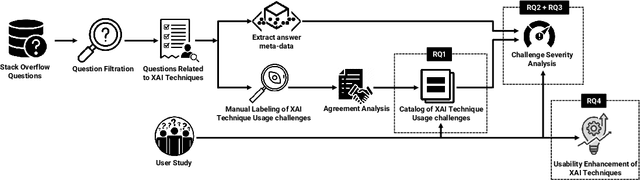

The lack of interpretability is a major barrier that limits the practical usage of AI models. Several eXplainable AI (XAI) techniques (e.g., SHAP, LIME) have been employed to interpret these models' performance. However, users often face challenges when leveraging these techniques in real-world scenarios and thus submit questions in technical Q&A forums like Stack Overflow (SO) to resolve these challenges. We conducted an exploratory study to expose these challenges, their severity, and features that can make XAI techniques more accessible and easier to use. Our contributions to this study are fourfold. First, we manually analyzed 663 SO questions that discussed challenges related to XAI techniques. Our careful investigation produced a catalog of seven challenges (e.g., disagreement issues). We then analyzed their prevalence and found that model integration and disagreement issues emerged as the most prevalent challenges. Second, we attempt to estimate the severity of each XAI challenge by determining the correlation between challenge types and answer metadata (e.g., the presence of accepted answers). Our analysis suggests that model integration issues is the most severe challenge. Third, we attempt to perceive the severity of these challenges based on practitioners' ability to use XAI techniques effectively in their work. Practitioners' responses suggest that disagreement issues most severely affect the use of XAI techniques. Fourth, we seek agreement from practitioners on improvements or features that could make XAI techniques more accessible and user-friendly. The majority of them suggest consistency in explanations and simplified integration. Our study findings might (a) help to enhance the accessibility and usability of XAI and (b) act as the initial benchmark that can inspire future research.
A systematic literature review on source code similarity measurement and clone detection: techniques, applications, and challenges
Jun 28, 2023Measuring and evaluating source code similarity is a fundamental software engineering activity that embraces a broad range of applications, including but not limited to code recommendation, duplicate code, plagiarism, malware, and smell detection. This paper proposes a systematic literature review and meta-analysis on code similarity measurement and evaluation techniques to shed light on the existing approaches and their characteristics in different applications. We initially found over 10000 articles by querying four digital libraries and ended up with 136 primary studies in the field. The studies were classified according to their methodology, programming languages, datasets, tools, and applications. A deep investigation reveals 80 software tools, working with eight different techniques on five application domains. Nearly 49% of the tools work on Java programs and 37% support C and C++, while there is no support for many programming languages. A noteworthy point was the existence of 12 datasets related to source code similarity measurement and duplicate codes, of which only eight datasets were publicly accessible. The lack of reliable datasets, empirical evaluations, hybrid methods, and focuses on multi-paradigm languages are the main challenges in the field. Emerging applications of code similarity measurement concentrate on the development phase in addition to the maintenance.