 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarbon-Taxed Transformers: A Green Compression Pipeline for Overgrown Language Models
Apr 28, 2026The accelerating adoption of Large Language Models (LLMs) in software engineering (SE) has brought with it a silent crisis: unsustainable computational cost. While these models demonstrate remarkable capabilities in different SE tasks, they are unmanageably large, slow to deploy, memory-intensive, and carbon-heavy. This reality threatens not only the scalability and accessibility of AI-powered SE, but also its long-term environmental sustainability. The research challenge is clear: we must go beyond accuracy and address efficiency and environmental cost as first-class design constraints. To meet this challenge, we introduce Carbon-Taxed Transformers (CTT), a systematic multi-architectural compression principled pipeline ordering inspired by economic carbon taxation principles. Drawing from the economic concept of carbon pricing, CTT operationalizes a computational carbon tax that penalizes architectural inefficiencies and rewards deployment-ready compression. We evaluate CTT across three core SE tasks: code clone detection, code summarization, and code generation, with models spanning encoder-only, encoder-decoder, and decoder-only architecture. Our results show that CTT delivers on inference: (1) up to 49x memory reduction, (2) time reduction up to 8-10x for clone detection, up to 3x for summarization, and 4-7x for generation, (3) up to 81% reduction in CO2 emissions and (4) CTT retains around 98% accuracy on clone detection, around 89% on summarization, and up to 91% (textual metrics) and 68% (pass@1) for generation. Two ablation studies show that pipeline ordering and individual component contributions are both essential, providing empirical justification for CTT's design and effectiveness. This work establishes a viable path toward responsible AI in SE through aggressive yet performance-preserving compression.
Why Are AI Agent Involved Pull Requests (Fix-Related) Remain Unmerged? An Empirical Study
Jan 29, 2026Autonomous coding agents (e.g., OpenAI Codex, Devin, GitHub Copilot) are increasingly used to generate fix-related pull requests (PRs) in real world software repositories. However, their practical effectiveness depends on whether these contributions are accepted and merged by project maintainers. In this paper, we present an empirical study of AI agent involved fix related PRs, examining both their integration outcomes, latency, and the factors that hinder successful merging. We first analyze 8,106 fix related PRs authored by five widely used AI coding agents from the AIDEV POP dataset to quantify the proportions of PRs that are merged, closed without merging, or remain open. We then conduct a manual qualitative analysis of a statistically significant sample of 326 closed but unmerged PRs, spending approximately 100 person hours to construct a structured catalog of 12 failure reasons. Our results indicate that test case failures and prior resolution of the same issues by other PRs are the most common causes of non integration, whereas build or deployment failures are comparatively rare. Overall, our findings expose key limitations of current AI coding agents in real world settings and highlight directions for their further improvement and for more effective human AI collaboration in software maintenance.
From Questions to Insights: Exploring XAI Challenges Reported on Stack Overflow Questions
Apr 03, 2025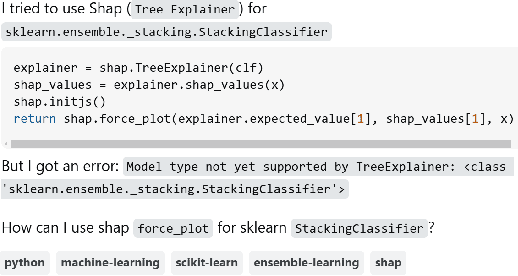

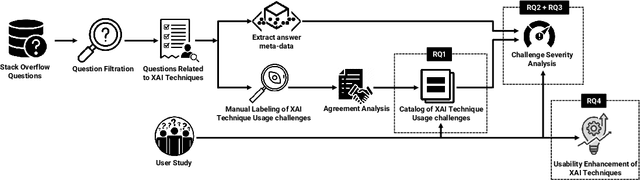

The lack of interpretability is a major barrier that limits the practical usage of AI models. Several eXplainable AI (XAI) techniques (e.g., SHAP, LIME) have been employed to interpret these models' performance. However, users often face challenges when leveraging these techniques in real-world scenarios and thus submit questions in technical Q&A forums like Stack Overflow (SO) to resolve these challenges. We conducted an exploratory study to expose these challenges, their severity, and features that can make XAI techniques more accessible and easier to use. Our contributions to this study are fourfold. First, we manually analyzed 663 SO questions that discussed challenges related to XAI techniques. Our careful investigation produced a catalog of seven challenges (e.g., disagreement issues). We then analyzed their prevalence and found that model integration and disagreement issues emerged as the most prevalent challenges. Second, we attempt to estimate the severity of each XAI challenge by determining the correlation between challenge types and answer metadata (e.g., the presence of accepted answers). Our analysis suggests that model integration issues is the most severe challenge. Third, we attempt to perceive the severity of these challenges based on practitioners' ability to use XAI techniques effectively in their work. Practitioners' responses suggest that disagreement issues most severely affect the use of XAI techniques. Fourth, we seek agreement from practitioners on improvements or features that could make XAI techniques more accessible and user-friendly. The majority of them suggest consistency in explanations and simplified integration. Our study findings might (a) help to enhance the accessibility and usability of XAI and (b) act as the initial benchmark that can inspire future research.
Comparative Analysis of Quantum and Classical Support Vector Classifiers for Software Bug Prediction: An Exploratory Study
Jan 08, 2025Purpose: Quantum computing promises to transform problem-solving across various domains with rapid and practical solutions. Within Software Evolution and Maintenance, Quantum Machine Learning (QML) remains mostly an underexplored domain, particularly in addressing challenges such as detecting buggy software commits from code repositories. Methods: In this study, we investigate the practical application of Quantum Support Vector Classifiers (QSVC) for detecting buggy software commits across 14 open-source software projects with diverse dataset sizes encompassing 30,924 data instances. We compare the QML algorithm PQSVC (Pegasos QSVC) and QSVC against the classical Support Vector Classifier (SVC). Our technique addresses large datasets in QSVC algorithms by dividing them into smaller subsets. We propose and evaluate an aggregation method to combine predictions from these models to detect the entire test dataset. We also introduce an incremental testing methodology to overcome the difficulties of quantum feature mapping during the testing approach. Results: The study shows the effectiveness of QSVC and PQSVC in detecting buggy software commits. The aggregation technique successfully combines predictions from smaller data subsets, enhancing the overall detection accuracy for the entire test dataset. The incremental testing methodology effectively manages the challenges associated with quantum feature mapping during the testing process. Conclusion: We contribute to the advancement of QML algorithms in defect prediction, unveiling the potential for further research in this domain. The specific scenario of the Short-Term Activity Frame (STAF) highlights the early detection of buggy software commits during the initial developmental phases of software systems, particularly when dataset sizes remain insufficient to train machine learning models.
Evaluating the Performance of a D-Wave Quantum Annealing System for Feature Subset Selection in Software Defect Prediction
Oct 21, 2024



Predicting software defects early in the development process not only enhances the quality and reliability of the software but also decreases the cost of development. A wide range of machine learning techniques can be employed to create software defect prediction models, but the effectiveness and accuracy of these models are often influenced by the choice of appropriate feature subset. Since finding the optimal feature subset is computationally intensive, heuristic and metaheuristic approaches are commonly employed to identify near-optimal solutions within a reasonable time frame. Recently, the quantum computing paradigm quantum annealing (QA) has been deployed to find solutions to complex optimization problems. This opens up the possibility of addressing the feature subset selection problem with a QA machine. Although several strategies have been proposed for feature subset selection using a QA machine, little exploration has been done regarding the viability of a QA machine for feature subset selection in software defect prediction. This study investigates the potential of D-Wave QA system for this task, where we formulate a mutual information (MI)-based filter approach as an optimization problem and utilize a D-Wave Quantum Processing Unit (QPU) solver as a QA solver for feature subset selection. We evaluate the performance of this approach using multiple software defect datasets from the AEEM, JIRA, and NASA projects. We also utilize a D-Wave classical solver for comparative analysis. Our experimental results demonstrate that QA-based feature subset selection can enhance software defect prediction. Although the D-Wave QPU solver exhibits competitive prediction performance with the classical solver in software defect prediction, it significantly reduces the time required to identify the best feature subset compared to its classical counterpart.
Unveiling the potential of large language models in generating semantic and cross-language clones
Sep 12, 2023


Semantic and Cross-language code clone generation may be useful for code reuse, code comprehension, refactoring and benchmarking. OpenAI's GPT model has potential in such clone generation as GPT is used for text generation. When developers copy/paste codes from Stack Overflow (SO) or within a system, there might be inconsistent changes leading to unexpected behaviours. Similarly, if someone possesses a code snippet in a particular programming language but seeks equivalent functionality in a different language, a semantic cross-language code clone generation approach could provide valuable assistance. In this study, using SemanticCloneBench as a vehicle, we evaluated how well the GPT-3 model could help generate semantic and cross-language clone variants for a given fragment.We have comprised a diverse set of code fragments and assessed GPT-3s performance in generating code variants.Through extensive experimentation and analysis, where 9 judges spent 158 hours to validate, we investigate the model's ability to produce accurate and semantically correct variants. Our findings shed light on GPT-3's strengths in code generation, offering insights into the potential applications and challenges of using advanced language models in software development. Our quantitative analysis yields compelling results. In the realm of semantic clones, GPT-3 attains an impressive accuracy of 62.14% and 0.55 BLEU score, achieved through few-shot prompt engineering. Furthermore, the model shines in transcending linguistic confines, boasting an exceptional 91.25% accuracy in generating cross-language clones