 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Quantum and Classical Support Vector Classifiers for Software Bug Prediction: An Exploratory Study
Jan 08, 2025Purpose: Quantum computing promises to transform problem-solving across various domains with rapid and practical solutions. Within Software Evolution and Maintenance, Quantum Machine Learning (QML) remains mostly an underexplored domain, particularly in addressing challenges such as detecting buggy software commits from code repositories. Methods: In this study, we investigate the practical application of Quantum Support Vector Classifiers (QSVC) for detecting buggy software commits across 14 open-source software projects with diverse dataset sizes encompassing 30,924 data instances. We compare the QML algorithm PQSVC (Pegasos QSVC) and QSVC against the classical Support Vector Classifier (SVC). Our technique addresses large datasets in QSVC algorithms by dividing them into smaller subsets. We propose and evaluate an aggregation method to combine predictions from these models to detect the entire test dataset. We also introduce an incremental testing methodology to overcome the difficulties of quantum feature mapping during the testing approach. Results: The study shows the effectiveness of QSVC and PQSVC in detecting buggy software commits. The aggregation technique successfully combines predictions from smaller data subsets, enhancing the overall detection accuracy for the entire test dataset. The incremental testing methodology effectively manages the challenges associated with quantum feature mapping during the testing process. Conclusion: We contribute to the advancement of QML algorithms in defect prediction, unveiling the potential for further research in this domain. The specific scenario of the Short-Term Activity Frame (STAF) highlights the early detection of buggy software commits during the initial developmental phases of software systems, particularly when dataset sizes remain insufficient to train machine learning models.
Quantum vs. Classical Machine Learning Algorithms for Software Defect Prediction: Challenges and Opportunities
Dec 10, 2024Software defect prediction is a critical aspect of software quality assurance, as it enables early identification and mitigation of defects, thereby reducing the cost and impact of software failures. Over the past few years, quantum computing has risen as an exciting technology capable of transforming multiple domains; Quantum Machine Learning (QML) is one of them. QML algorithms harness the power of quantum computing to solve complex problems with better efficiency and effectiveness than their classical counterparts. However, research into its application in software engineering to predict software defects still needs to be explored. In this study, we worked to fill the research gap by comparing the performance of three QML and five classical machine learning (CML) algorithms on the 20 software defect datasets. Our investigation reports the comparative scenarios of QML vs. CML algorithms and identifies the better-performing and consistent algorithms to predict software defects. We also highlight the challenges and future directions of employing QML algorithms in real software defect datasets based on the experience we faced while performing this investigation. The findings of this study can help practitioners and researchers further progress in this research domain by making software systems reliable and bug-free.
Evaluating the Performance of a D-Wave Quantum Annealing System for Feature Subset Selection in Software Defect Prediction
Oct 21, 2024



Predicting software defects early in the development process not only enhances the quality and reliability of the software but also decreases the cost of development. A wide range of machine learning techniques can be employed to create software defect prediction models, but the effectiveness and accuracy of these models are often influenced by the choice of appropriate feature subset. Since finding the optimal feature subset is computationally intensive, heuristic and metaheuristic approaches are commonly employed to identify near-optimal solutions within a reasonable time frame. Recently, the quantum computing paradigm quantum annealing (QA) has been deployed to find solutions to complex optimization problems. This opens up the possibility of addressing the feature subset selection problem with a QA machine. Although several strategies have been proposed for feature subset selection using a QA machine, little exploration has been done regarding the viability of a QA machine for feature subset selection in software defect prediction. This study investigates the potential of D-Wave QA system for this task, where we formulate a mutual information (MI)-based filter approach as an optimization problem and utilize a D-Wave Quantum Processing Unit (QPU) solver as a QA solver for feature subset selection. We evaluate the performance of this approach using multiple software defect datasets from the AEEM, JIRA, and NASA projects. We also utilize a D-Wave classical solver for comparative analysis. Our experimental results demonstrate that QA-based feature subset selection can enhance software defect prediction. Although the D-Wave QPU solver exhibits competitive prediction performance with the classical solver in software defect prediction, it significantly reduces the time required to identify the best feature subset compared to its classical counterpart.
Leveraging Structural Properties of Source Code Graphs for Just-In-Time Bug Prediction
Jan 25, 2022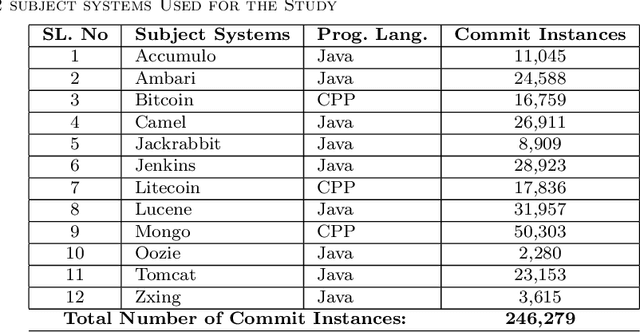
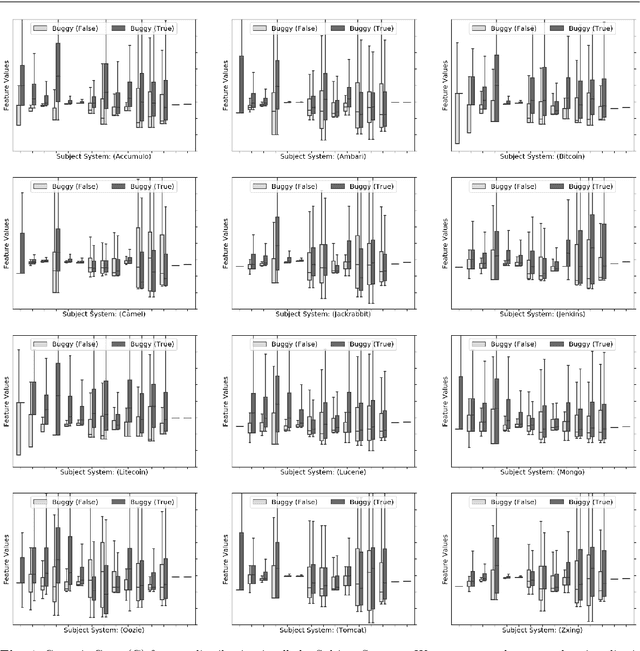
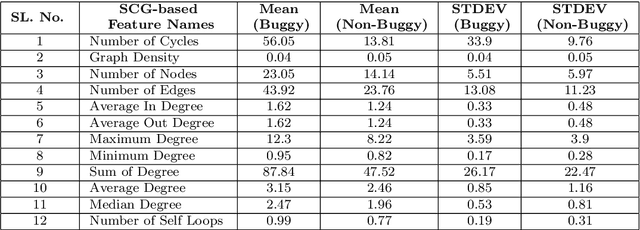
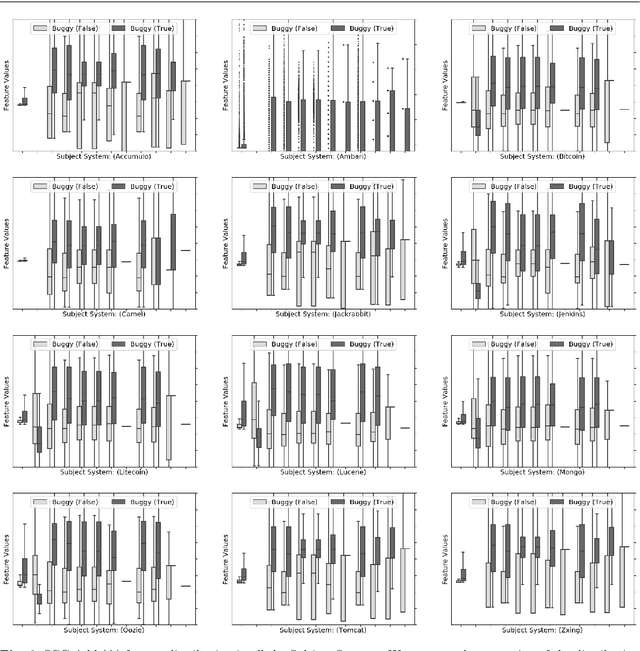
The most common use of data visualization is to minimize the complexity for proper understanding. A graph is one of the most commonly used representations for understanding relational data. It produces a simplified representation of data that is challenging to comprehend if kept in a textual format. In this study, we propose a methodology to utilize the relational properties of source code in the form of a graph to identify Just-in-Time (JIT) bug prediction in software systems during different revisions of software evolution and maintenance. We presented a method to convert the source codes of commit patches to equivalent graph representations and named it Source Code Graph (SCG). To understand and compare multiple source code graphs, we extracted several structural properties of these graphs, such as the density, number of cycles, nodes, edges, etc. We then utilized the attribute values of those SCGs to visualize and detect buggy software commits. We process more than 246K software commits from 12 subject systems in this investigation. Our investigation on these 12 open-source software projects written in C++ and Java programming languages shows that if we combine the features from SCG with conventional features used in similar studies, we will get the increased performance of Machine Learning (ML) based buggy commit detection models. We also find the increase of F1~Scores in predicting buggy and non-buggy commits statistically significant using the Wilcoxon Signed Rank Test. Since SCG-based feature values represent the style or structural properties of source code updates or changes in the software system, it suggests the importance of careful maintenance of source code style or structure for keeping a software system bug-free.