 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Emotion Recognition System using basic emotions via Facial Expression, EEG, and ECG Signals: a review
Sep 09, 2024
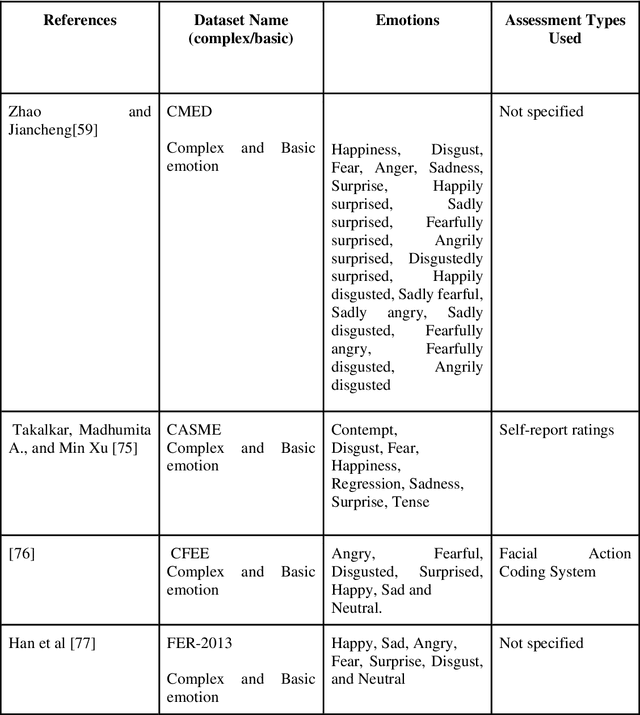

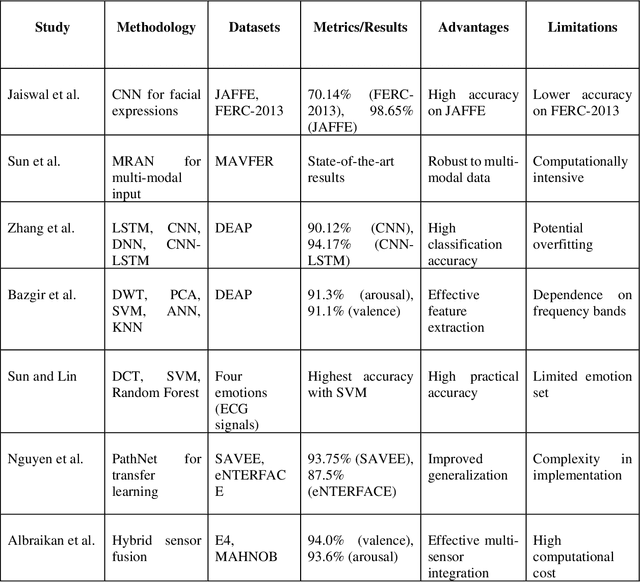
The Complex Emotion Recognition System (CERS) deciphers complex emotional states by examining combinations of basic emotions expressed, their interconnections, and the dynamic variations. Through the utilization of advanced algorithms, CERS provides profound insights into emotional dynamics, facilitating a nuanced understanding and customized responses. The attainment of such a level of emotional recognition in machines necessitates the knowledge distillation and the comprehension of novel concepts akin to human cognition. The development of AI systems for discerning complex emotions poses a substantial challenge with significant implications for affective computing. Furthermore, obtaining a sizable dataset for CERS proves to be a daunting task due to the intricacies involved in capturing subtle emotions, necessitating specialized methods for data collection and processing. Incorporating physiological signals such as Electrocardiogram (ECG) and Electroencephalogram (EEG) can notably enhance CERS by furnishing valuable insights into the user's emotional state, enhancing the quality of datasets, and fortifying system dependability. A comprehensive literature review was conducted in this study to assess the efficacy of machine learning, deep learning, and meta-learning approaches in both basic and complex emotion recognition utilizing EEG, ECG signals, and facial expression datasets. The chosen research papers offer perspectives on potential applications, clinical implications, and results of CERSs, with the objective of promoting their acceptance and integration into clinical decision-making processes. This study highlights research gaps and challenges in understanding CERSs, encouraging further investigation by relevant studies and organizations. Lastly, the significance of meta-learning approaches in improving CERS performance and guiding future research endeavors is underscored.
Malicious URL Detection using optimized Hist Gradient Boosting Classifier based on grid search method
Jun 12, 2024



Trusting the accuracy of data inputted on online platforms can be difficult due to the possibility of malicious websites gathering information for unlawful reasons. Analyzing each website individually becomes challenging with the presence of such malicious sites, making it hard to efficiently list all Uniform Resource Locators (URLs) on a blacklist. This ongoing challenge emphasizes the crucial need for strong security measures to safeguard against potential threats and unauthorized data collection. To detect the risk posed by malicious websites, it is proposed to utilize Machine Learning (ML)-based techniques. To this, we used several ML techniques such as Hist Gradient Boosting Classifier (HGBC), K-Nearest Neighbor (KNN), Logistic Regression (LR), Decision Tree (DT), Random Forest (RF), Multi-Layer Perceptron (MLP), Light Gradient Boosting Machine (LGBM), and Support Vector Machine (SVM) for detection of the benign and malicious website dataset. The dataset used contains 1781 records of malicious and benign website data with 13 features. First, we investigated missing value imputation on the dataset. Then, we normalized this data by scaling to a range of zero and one. Next, we utilized the Synthetic Minority Oversampling Technique (SMOTE) to balance the training data since the data set was unbalanced. After that, we applied ML algorithms to the balanced training set. Meanwhile, all algorithms were optimized based on grid search. Finally, the models were evaluated based on accuracy, precision, recall, F1 score, and the Area Under the Curve (AUC) metrics. The results demonstrated that the HGBC classifier has the best performance in terms of the mentioned metrics compared to the other classifiers.