 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Augmentation with Unimodal Fine-tuning for Multimodal Learning
May 10, 2025This paper proposes batch augmentation with unimodal fine-tuning to detect the fetus's organs from ultrasound images and associated clinical textual information. We also prescribe pre-training initial layers with investigated medical data before the multimodal training. At first, we apply a transferred initialization with the unimodal image portion of the dataset with batch augmentation. This step adjusts the initial layer weights for medical data. Then, we apply neural networks (NNs) with fine-tuned initial layers to images in batches with batch augmentation to obtain features. We also extract information from descriptions of images. We combine this information with features obtained from images to train the head layer. We write a dataloader script to load the multimodal data and use existing unimodal image augmentation techniques with batch augmentation for the multimodal data. The dataloader brings a new random augmentation for each batch to get a good generalization. We investigate the FPU23 ultrasound and UPMC Food-101 multimodal datasets. The multimodal large language model (LLM) with the proposed training provides the best results among the investigated methods. We receive near state-of-the-art (SOTA) performance on the UPMC Food-101 dataset. We share the scripts of the proposed method with traditional counterparts at the following repository: github.com/dipuk0506/multimodal
Reduction of Class Activation Uncertainty with Background Information
May 05, 2023Multitask learning is a popular approach to training high-performing neural networks with improved generalization. In this paper, we propose a background class to achieve improved generalization at a lower computation compared to multitask learning to help researchers and organizations with limited computation power. We also present a methodology for selecting background images and discuss potential future improvements. We apply our approach to several datasets and achieved improved generalization with much lower computation. We also investigate class activation mappings (CAMs) of the trained model and observed the tendency towards looking at a bigger picture in a few class classification problems with the proposed model training methodology. Example scripts are available in the `CAM' folder of the following GitHub Repository: github.com/dipuk0506/UQ
Uncertainty Aware Neural Network from Similarity and Sensitivity
Apr 27, 2023Researchers have proposed several approaches for neural network (NN) based uncertainty quantification (UQ). However, most of the approaches are developed considering strong assumptions. Uncertainty quantification algorithms often perform poorly in an input domain and the reason for poor performance remains unknown. Therefore, we present a neural network training method that considers similar samples with sensitivity awareness in this paper. In the proposed NN training method for UQ, first, we train a shallow NN for the point prediction. Then, we compute the absolute differences between prediction and targets and train another NN for predicting those absolute differences or absolute errors. Domains with high average absolute errors represent a high uncertainty. In the next step, we select each sample in the training set one by one and compute both prediction and error sensitivities. Then we select similar samples with sensitivity consideration and save indexes of similar samples. The ranges of an input parameter become narrower when the output is highly sensitive to that parameter. After that, we construct initial uncertainty bounds (UB) by considering the distribution of sensitivity aware similar samples. Prediction intervals (PIs) from initial uncertainty bounds are larger and cover more samples than required. Therefore, we train bound correction NN. As following all the steps for finding UB for each sample requires a lot of computation and memory access, we train a UB computation NN. The UB computation NN takes an input sample and provides an uncertainty bound. The UB computation NN is the final product of the proposed approach. Scripts of the proposed method are available in the following GitHub repository: github.com/dipuk0506/UQ
CoV-TI-Net: Transferred Initialization with Modified End Layer for COVID-19 Diagnosis
Sep 20, 2022
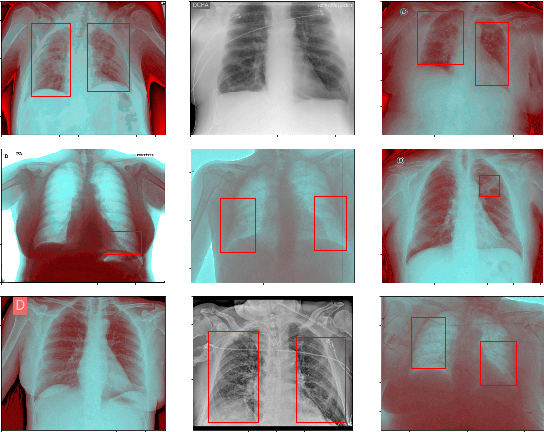
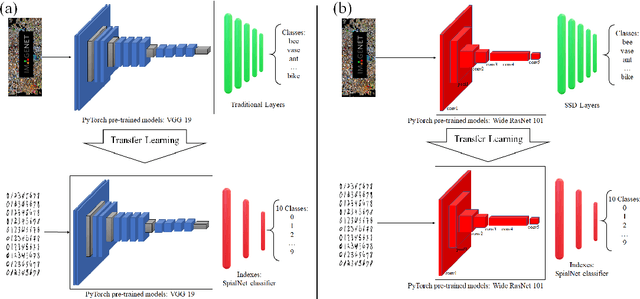
This paper proposes transferred initialization with modified fully connected layers for COVID-19 diagnosis. Convolutional neural networks (CNN) achieved a remarkable result in image classification. However, training a high-performing model is a very complicated and time-consuming process because of the complexity of image recognition applications. On the other hand, transfer learning is a relatively new learning method that has been employed in many sectors to achieve good performance with fewer computations. In this research, the PyTorch pre-trained models (VGG19\_bn and WideResNet -101) are applied in the MNIST dataset for the first time as initialization and with modified fully connected layers. The employed PyTorch pre-trained models were previously trained in ImageNet. The proposed model is developed and verified in the Kaggle notebook, and it reached the outstanding accuracy of 99.77% without taking a huge computational time during the training process of the network. We also applied the same methodology to the SIIM-FISABIO-RSNA COVID-19 Detection dataset and achieved 80.01% accuracy. In contrast, the previous methods need a huge compactional time during the training process to reach a high-performing model. Codes are available at the following link: github.com/dipuk0506/SpinalNet
Resource allocation optimization using artificial intelligence methods in various computing paradigms: A Review
Mar 23, 2022
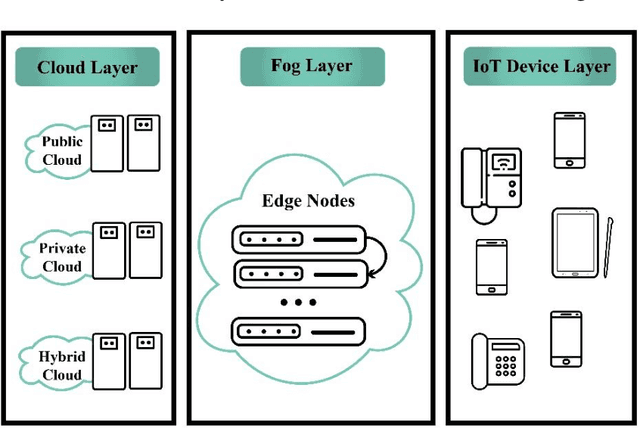
With the advent of smart devices, the demand for various computational paradigms such as the Internet of Things, fog, and cloud computing has increased. However, effective resource allocation remains challenging in these paradigms. This paper presents a comprehensive literature review on the application of artificial intelligence (AI) methods such as deep learning (DL) and machine learning (ML) for resource allocation optimization in computational paradigms. To the best of our knowledge, there are no existing reviews on AI-based resource allocation approaches in different computational paradigms. The reviewed ML-based approaches are categorized as supervised and reinforcement learning (RL). Moreover, DL-based approaches and their combination with RL are surveyed. The review ends with a discussion on open research directions and a conclusion.
A Comprehensive Study on Torchvision Pre-trained Models for Fine-grained Inter-species Classification
Oct 14, 2021



This study aims to explore different pre-trained models offered in the Torchvision package which is available in the PyTorch library. And investigate their effectiveness on fine-grained images classification. Transfer Learning is an effective method of achieving extremely good performance with insufficient training data. In many real-world situations, people cannot collect sufficient data required to train a deep neural network model efficiently. Transfer Learning models are pre-trained on a large data set, and can bring a good performance on smaller datasets with significantly lower training time. Torchvision package offers us many models to apply the Transfer Learning on smaller datasets. Therefore, researchers may need a guideline for the selection of a good model. We investigate Torchvision pre-trained models on four different data sets: 10 Monkey Species, 225 Bird Species, Fruits 360, and Oxford 102 Flowers. These data sets have images of different resolutions, class numbers, and different achievable accuracies. We also apply their usual fully-connected layer and the Spinal fully-connected layer to investigate the effectiveness of SpinalNet. The Spinal fully-connected layer brings better performance in most situations. We apply the same augmentation for different models for the same data set for a fair comparison. This paper may help future Computer Vision researchers in choosing a proper Transfer Learning model.
* Accepted
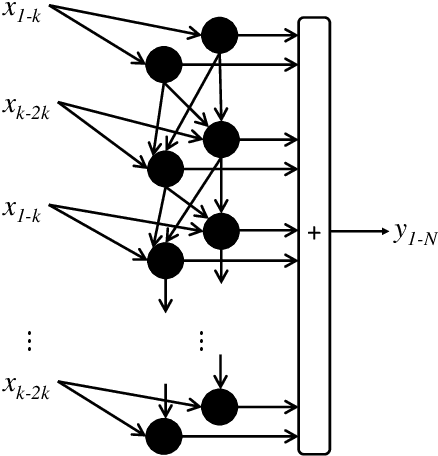
SpinalNet: Deep Neural Network with Gradual Input
Jul 07, 2020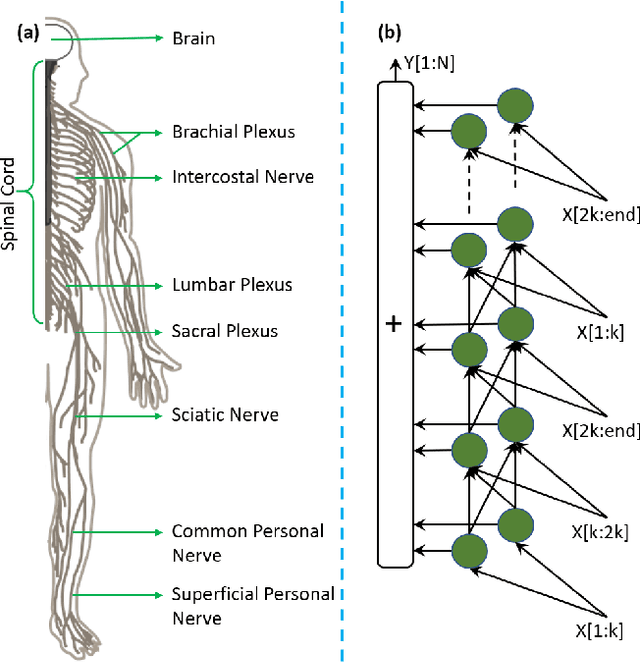
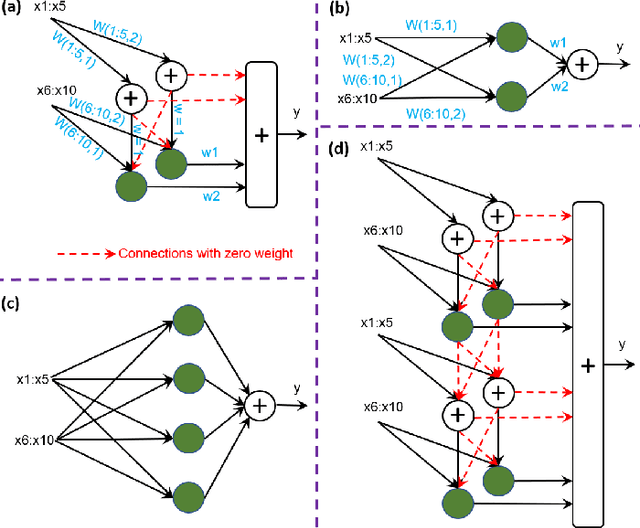
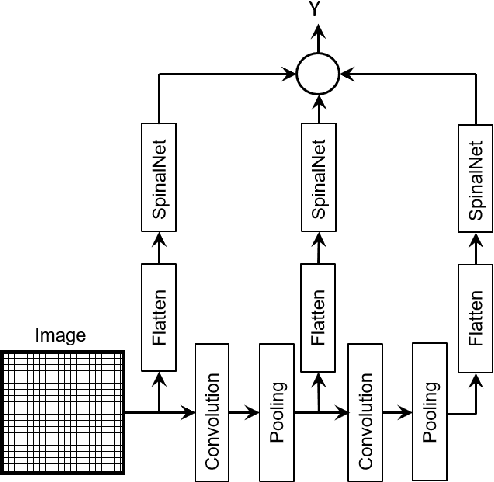
Deep neural networks (DNNs) have achieved the state of the art performance in numerous fields. However, DNNs need high computation times, and people always expect better performance with lower computation. Therefore, we study the human somatosensory system and design a neural network (SpinalNet) to achieve higher accuracy with lower computation time. This paper aims to present the SpinalNet. Hidden layers of the proposed SpinalNet consist of three parts: 1) Input row, 2) Intermediate row, and 3) output row. The intermediate row of the SpinalNet usually contains a small number of neurons. Input segmentation enables each hidden layer to receive a part of the input and outputs of the previous layer. Therefore, the number of incoming weights in a hidden layer is significantly lower than traditional DNNs. As the network directly contributes to outputs in each layer, the vanishing gradient problem of DNN does not exist. We integrate the SpinalNet as the fully-connected layer of the convolutional neural network (CNN), residual neural network (ResNet), and Dense Convolutional Network (DenseNet), Visual Geometry Group (VGG) network. We observe a significant error reduction with lower computation in most situations. We have received state-of-the-art performance for the QMNIST, Kuzushiji-MNIST, and EMNIST(digits) datasets. Scripts of the proposed SpinalNet is available at the following link: https://github.com/dipuk0506/SpinalNet
Optimal Uncertainty-guided Neural Network Training
Dec 30, 2019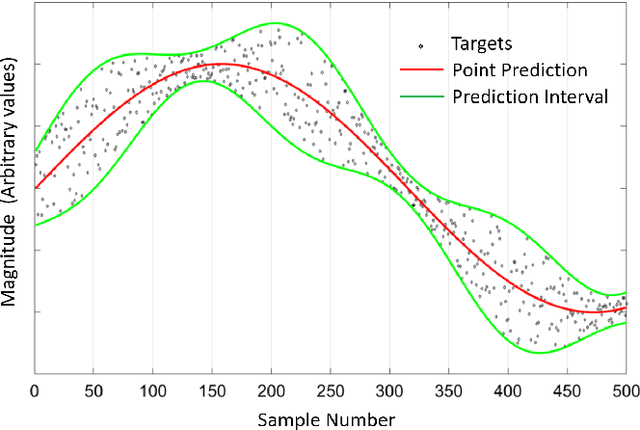
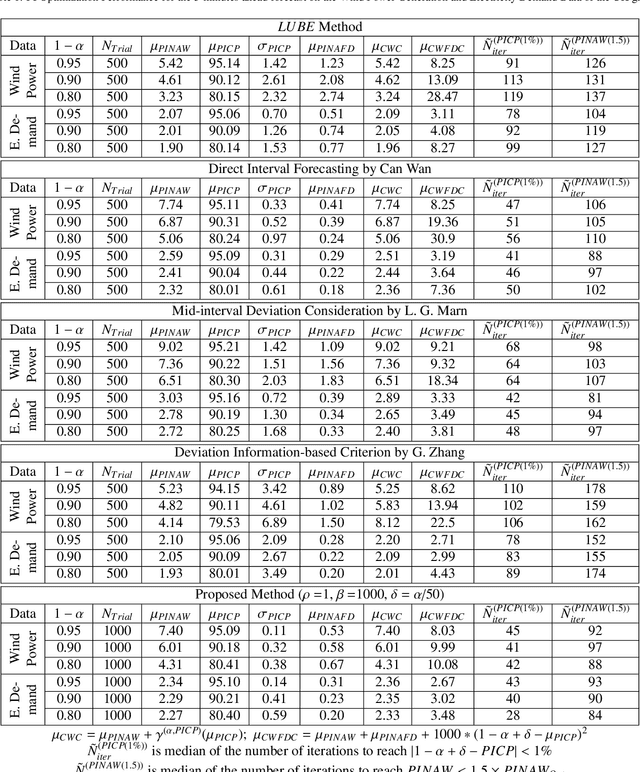
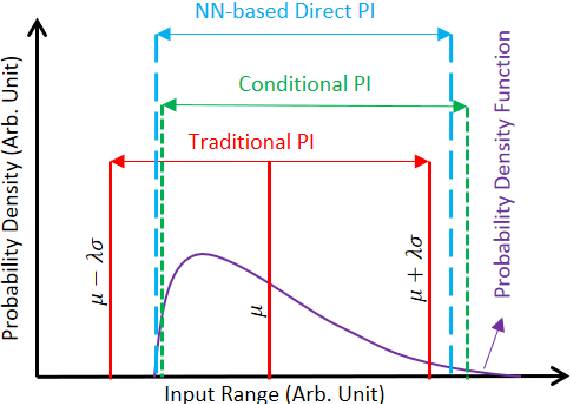
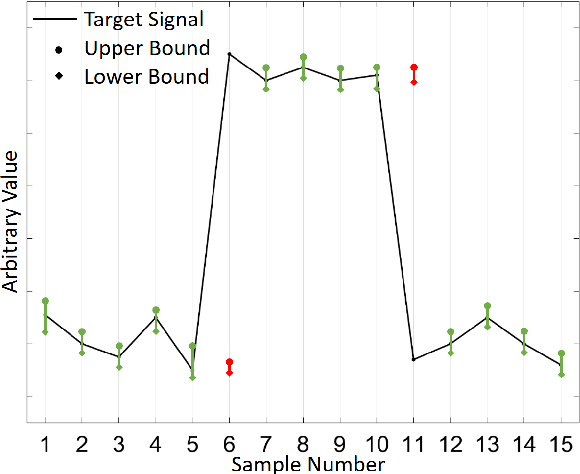
The neural network (NN)-based direct uncertainty quantification (UQ) methods have achieved the state of the art performance since the first inauguration, known as the lower-upper-bound estimation (LUBE) method. However, currently-available cost functions for uncertainty guided NN training are not always converging and all converged NNs are not generating optimized prediction intervals (PIs). Moreover, several groups have proposed different quality criteria for PIs. These raise a question about their relative effectiveness. Most of the existing cost functions of uncertainty guided NN training are not customizable and the convergence of training is uncertain. Therefore, in this paper, we propose a highly customizable smooth cost function for developing NNs to construct optimal PIs. The optimized average width of PIs, PI-failure distances and the PI coverage probability (PICP) are computed for the test dataset. The performance of the proposed method is examined for the wind power generation and the electricity demand data. Results show that the proposed method reduces variation in the quality of PIs, accelerates the training, and improves convergence probability from 99.2% to 99.8%.