 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA nonlinear real time capable motion cueing algorithm based on deep reinforcement learning
Mar 13, 2025
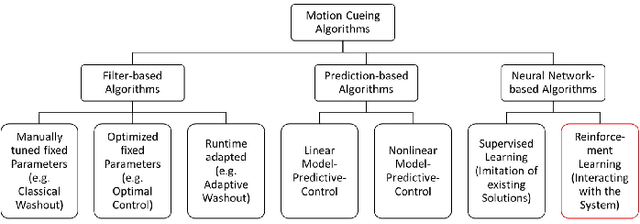
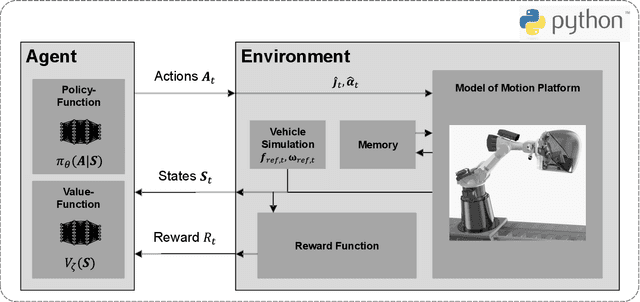
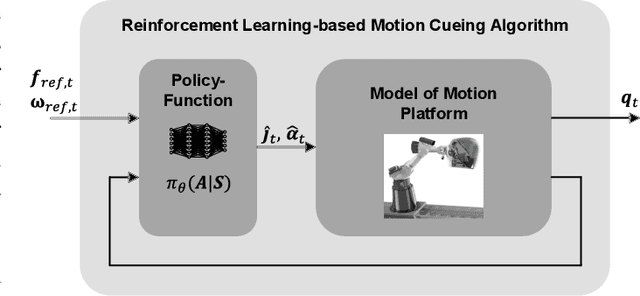
In motion simulation, motion cueing algorithms are used for the trajectory planning of the motion simulator platform, where workspace limitations prevent direct reproduction of reference trajectories. Strategies such as motion washout, which return the platform to its center, are crucial in these settings. For serial robotic MSPs with highly nonlinear workspaces, it is essential to maximize the efficient utilization of the MSPs kinematic and dynamic capabilities. Traditional approaches, including classical washout filtering and linear model predictive control, fail to consider platform-specific, nonlinear properties, while nonlinear model predictive control, though comprehensive, imposes high computational demands that hinder real-time, pilot-in-the-loop application without further simplification. To overcome these limitations, we introduce a novel approach using deep reinforcement learning for motion cueing, demonstrated here for the first time in a 6-degree-of-freedom setting with full consideration of the MSPs kinematic nonlinearities. Previous work by the authors successfully demonstrated the application of DRL to a simplified 2-DOF setup, which did not consider kinematic or dynamic constraints. This approach has been extended to all 6 DOF by incorporating a complete kinematic model of the MSP into the algorithm, a crucial step for enabling its application on a real motion simulator. The training of the DRL-MCA is based on Proximal Policy Optimization in an actor-critic implementation combined with an automated hyperparameter optimization. After detailing the necessary training framework and the algorithm itself, we provide a comprehensive validation, demonstrating that the DRL MCA achieves competitive performance against established algorithms. Moreover, it generates feasible trajectories by respecting all system constraints and meets all real-time requirements with low...
A Review on Robot Manipulation Methods in Human-Robot Interactions
Sep 09, 2023



Robot manipulation is an important part of human-robot interaction technology. However, traditional pre-programmed methods can only accomplish simple and repetitive tasks. To enable effective communication between robots and humans, and to predict and adapt to uncertain environments, this paper reviews recent autonomous and adaptive learning in robotic manipulation algorithms. It includes typical applications and challenges of human-robot interaction, fundamental tasks of robot manipulation and one of the most widely used formulations of robot manipulation, Markov Decision Process. Recent research focusing on robot manipulation is mainly based on Reinforcement Learning and Imitation Learning. This review paper shows the importance of Deep Reinforcement Learning, which plays an important role in manipulating robots to complete complex tasks in disturbed and unfamiliar environments. With the introduction of Imitation Learning, it is possible for robot manipulation to get rid of reward function design and achieve a simple, stable and supervised learning process. This paper reviews and compares the main features and popular algorithms for both Reinforcement Learning and Imitation Learning.
Uncertainty Aware Neural Network from Similarity and Sensitivity
Apr 27, 2023Researchers have proposed several approaches for neural network (NN) based uncertainty quantification (UQ). However, most of the approaches are developed considering strong assumptions. Uncertainty quantification algorithms often perform poorly in an input domain and the reason for poor performance remains unknown. Therefore, we present a neural network training method that considers similar samples with sensitivity awareness in this paper. In the proposed NN training method for UQ, first, we train a shallow NN for the point prediction. Then, we compute the absolute differences between prediction and targets and train another NN for predicting those absolute differences or absolute errors. Domains with high average absolute errors represent a high uncertainty. In the next step, we select each sample in the training set one by one and compute both prediction and error sensitivities. Then we select similar samples with sensitivity consideration and save indexes of similar samples. The ranges of an input parameter become narrower when the output is highly sensitive to that parameter. After that, we construct initial uncertainty bounds (UB) by considering the distribution of sensitivity aware similar samples. Prediction intervals (PIs) from initial uncertainty bounds are larger and cover more samples than required. Therefore, we train bound correction NN. As following all the steps for finding UB for each sample requires a lot of computation and memory access, we train a UB computation NN. The UB computation NN takes an input sample and provides an uncertainty bound. The UB computation NN is the final product of the proposed approach. Scripts of the proposed method are available in the following GitHub repository: github.com/dipuk0506/UQ
A novel approach of a deep reinforcement learning based motion cueing algorithm for vehicle driving simulation
Apr 15, 2023
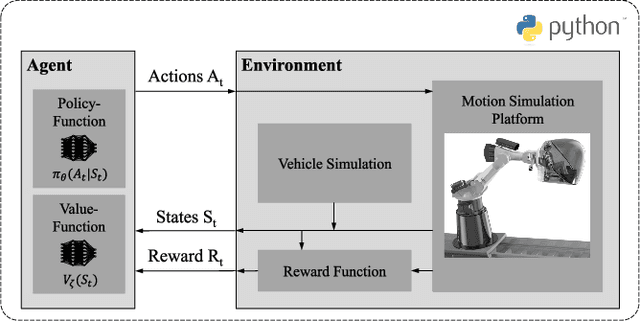
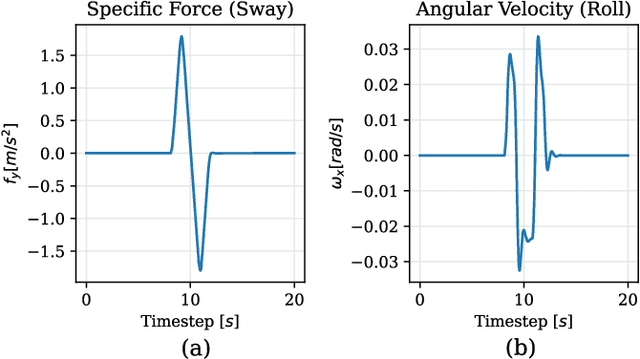
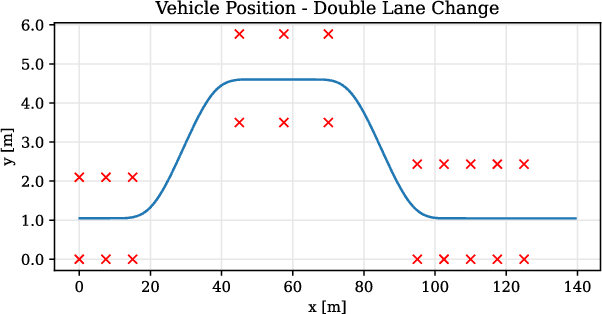
In the field of motion simulation, the level of immersion strongly depends on the motion cueing algorithm (MCA), as it transfers the reference motion of the simulated vehicle to a motion of the motion simulation platform (MSP). The challenge for the MCA is to reproduce the motion perception of a real vehicle driver as accurately as possible without exceeding the limits of the workspace of the MSP in order to provide a realistic virtual driving experience. In case of a large discrepancy between the perceived motion signals and the optical cues, motion sickness may occur with the typical symptoms of nausea, dizziness, headache and fatigue. Existing approaches either produce non-optimal results, e.g., due to filtering, linearization, or simplifications, or the required computational time exceeds the real-time requirements of a closed-loop application. In this work a new solution is presented, where not a human designer specifies the principles of the MCA but an artificial intelligence (AI) learns the optimal motion by trial and error in an interaction with the MSP. To achieve this, deep reinforcement learning (RL) is applied, where an agent interacts with an environment formulated as a Markov decision process~(MDP). This allows the agent to directly control a simulated MSP to obtain feedback on its performance in terms of platform workspace usage and the motion acting on the simulator user. The RL algorithm used is proximal policy optimization (PPO), where the value function and the policy corresponding to the control strategy are learned and both are mapped in artificial neural networks (ANN). This approach is implemented in Python and the functionality is demonstrated by the practical example of pre-recorded lateral maneuvers. The subsequent validation on a standardized double lane change shows that the RL algorithm is able to learn the control strategy and improve the quality of...
A Comprehensive Review on Autonomous Navigation
Dec 24, 2022



The field of autonomous mobile robots has undergone dramatic advancements over the past decades. Despite achieving important milestones, several challenges are yet to be addressed. Aggregating the achievements of the robotic community as survey papers is vital to keep the track of current state-of-the-art and the challenges that must be tackled in the future. This paper tries to provide a comprehensive review of autonomous mobile robots covering topics such as sensor types, mobile robot platforms, simulation tools, path planning and following, sensor fusion methods, obstacle avoidance, and SLAM. The urge to present a survey paper is twofold. First, autonomous navigation field evolves fast so writing survey papers regularly is crucial to keep the research community well-aware of the current status of this field. Second, deep learning methods have revolutionized many fields including autonomous navigation. Therefore, it is necessary to give an appropriate treatment of the role of deep learning in autonomous navigation as well which is covered in this paper. Future works and research gaps will also be discussed.
CoV-TI-Net: Transferred Initialization with Modified End Layer for COVID-19 Diagnosis
Sep 20, 2022
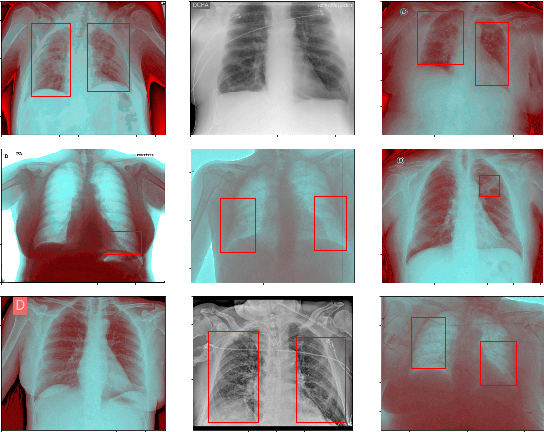
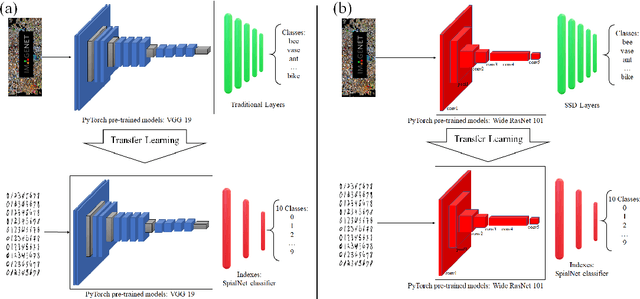
This paper proposes transferred initialization with modified fully connected layers for COVID-19 diagnosis. Convolutional neural networks (CNN) achieved a remarkable result in image classification. However, training a high-performing model is a very complicated and time-consuming process because of the complexity of image recognition applications. On the other hand, transfer learning is a relatively new learning method that has been employed in many sectors to achieve good performance with fewer computations. In this research, the PyTorch pre-trained models (VGG19\_bn and WideResNet -101) are applied in the MNIST dataset for the first time as initialization and with modified fully connected layers. The employed PyTorch pre-trained models were previously trained in ImageNet. The proposed model is developed and verified in the Kaggle notebook, and it reached the outstanding accuracy of 99.77% without taking a huge computational time during the training process of the network. We also applied the same methodology to the SIIM-FISABIO-RSNA COVID-19 Detection dataset and achieved 80.01% accuracy. In contrast, the previous methods need a huge compactional time during the training process to reach a high-performing model. Codes are available at the following link: github.com/dipuk0506/SpinalNet