 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlideSpawn: An Automatic Slides Generation System for Research Publications
Nov 20, 2024Research papers are well structured documents. They have text, figures, equations, tables etc., to covey their ideas and findings. They are divided into sections like Introduction, Model, Experiments etc., which deal with different aspects of research. Characteristics like these set research papers apart from ordinary documents and allows us to significantly improve their summarization. In this paper, we propose a novel system, SlideSpwan, that takes PDF of a research document as an input and generates a quality presentation providing it's summary in a visual and concise fashion. The system first converts the PDF of the paper to an XML document that has the structural information about various elements. Then a machine learning model, trained on PS5K dataset and Aminer 9.5K Insights dataset (that we introduce), is used to predict salience of each sentence in the paper. Sentences for slides are selected using ILP and clustered based on their similarity with each cluster being given a suitable title. Finally a slide is generated by placing any graphical element referenced in the selected sentences next to them. Experiments on a test set of 650 pairs of papers and slides demonstrate that our system generates presentations with better quality.
LayerNAS: Neural Architecture Search in Polynomial Complexity
Apr 23, 2023Neural Architecture Search (NAS) has become a popular method for discovering effective model architectures, especially for target hardware. As such, NAS methods that find optimal architectures under constraints are essential. In our paper, we propose LayerNAS to address the challenge of multi-objective NAS by transforming it into a combinatorial optimization problem, which effectively constrains the search complexity to be polynomial. For a model architecture with $L$ layers, we perform layerwise-search for each layer, selecting from a set of search options $\mathbb{S}$. LayerNAS groups model candidates based on one objective, such as model size or latency, and searches for the optimal model based on another objective, thereby splitting the cost and reward elements of the search. This approach limits the search complexity to $ O(H \cdot |\mathbb{S}| \cdot L) $, where $H$ is a constant set in LayerNAS. Our experiments show that LayerNAS is able to consistently discover superior models across a variety of search spaces in comparison to strong baselines, including search spaces derived from NATS-Bench, MobileNetV2 and MobileNetV3.
CoV-TI-Net: Transferred Initialization with Modified End Layer for COVID-19 Diagnosis
Sep 20, 2022
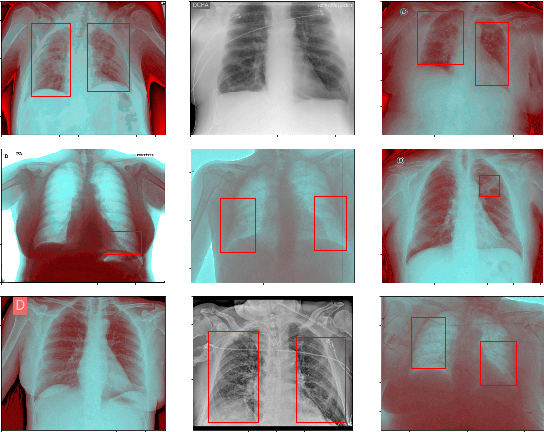
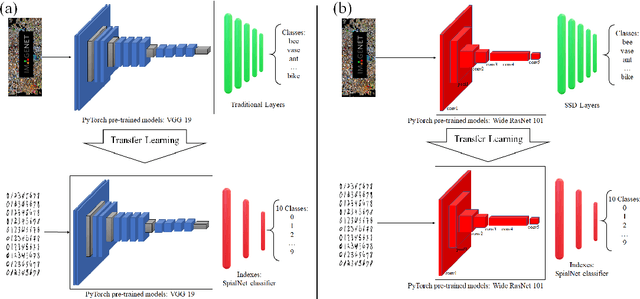
This paper proposes transferred initialization with modified fully connected layers for COVID-19 diagnosis. Convolutional neural networks (CNN) achieved a remarkable result in image classification. However, training a high-performing model is a very complicated and time-consuming process because of the complexity of image recognition applications. On the other hand, transfer learning is a relatively new learning method that has been employed in many sectors to achieve good performance with fewer computations. In this research, the PyTorch pre-trained models (VGG19\_bn and WideResNet -101) are applied in the MNIST dataset for the first time as initialization and with modified fully connected layers. The employed PyTorch pre-trained models were previously trained in ImageNet. The proposed model is developed and verified in the Kaggle notebook, and it reached the outstanding accuracy of 99.77% without taking a huge computational time during the training process of the network. We also applied the same methodology to the SIIM-FISABIO-RSNA COVID-19 Detection dataset and achieved 80.01% accuracy. In contrast, the previous methods need a huge compactional time during the training process to reach a high-performing model. Codes are available at the following link: github.com/dipuk0506/SpinalNet
Using Static and Dynamic Malware features to perform Malware Ascription
Dec 05, 2021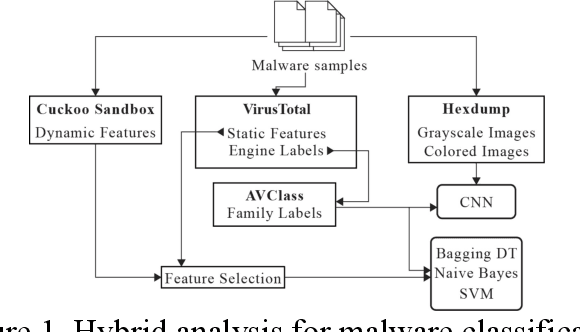


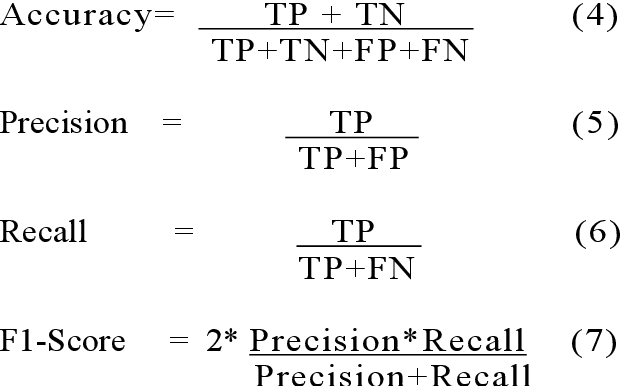
Malware ascription is a relatively unexplored area, and it is rather difficult to attribute malware and detect authorship. In this paper, we employ various Static and Dynamic features of malicious executables to classify malware based on their family. We leverage Cuckoo Sandbox and machine learning to make progress in this research. Post analysis, classification is performed using various deep learning and machine learning algorithms. Using the features gathered from VirusTotal (static) and Cuckoo (dynamic) reports, we ran the vectorized data against Multinomial Naive Bayes, Support Vector Machine, and Bagging using Decision Trees as the base estimator. For each classifier, we tuned the hyper-parameters using exhaustive search methods. Our reports can be extremely useful in malware ascription.
Problems with automating translation of movie/TV show subtitles
Sep 04, 2019

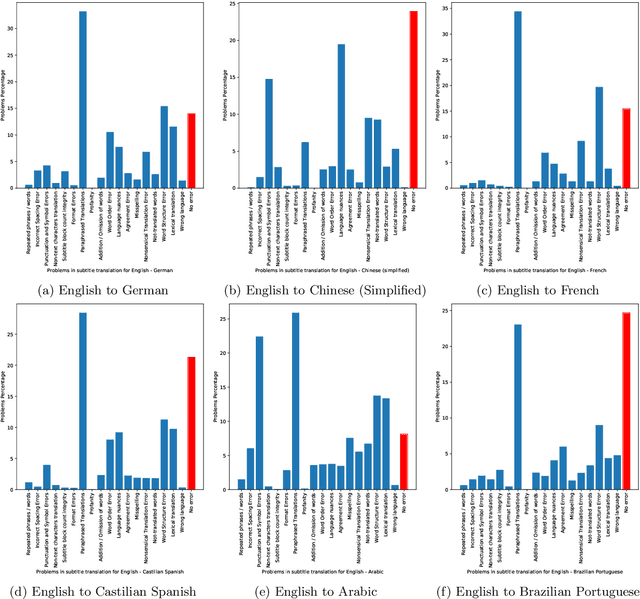

We present 27 problems encountered in automating the translation of movie/TV show subtitles. We categorize each problem in one of the three categories viz. problems directly related to textual translation, problems related to subtitle creation guidelines, and problems due to adaptability of machine translation (MT) engines. We also present the findings of a translation quality evaluation experiment where we share the frequency of 16 key problems. We show that the systems working at the frontiers of Natural Language Processing do not perform well for subtitles and require some post-processing solutions for redressal of these problems