 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Classroom Dialogue Sequences Analysis with a Hybrid AI Agent: Merging Expert Rule-Base with Large Language Models
Nov 13, 2024



Classroom dialogue plays a crucial role in fostering student engagement and deeper learning. However, analysing dialogue sequences has traditionally relied on either theoretical frameworks or empirical descriptions of practice, with limited integration between the two. This study addresses this gap by developing a comprehensive rule base of dialogue sequences and an Artificial Intelligence (AI) agent that combines expert-informed rule-based systems with a large language model (LLM). The agent applies expert knowledge while adapting to the complexities of natural language, enabling accurate and flexible categorisation of classroom dialogue sequences. By synthesising findings from over 30 studies, we established a comprehensive framework for dialogue analysis. The agent was validated against human expert coding, achieving high levels of precision and reliability. The results demonstrate that the agent provides theory-grounded and adaptive functions, tremendously enhancing the efficiency and scalability of classroom dialogue analysis, offering significant potential in improving classroom teaching practices and supporting teacher professional development.
Evaluating Large Language Models in Analysing Classroom Dialogue
Feb 06, 2024This study explores the application of Large Language Models (LLMs), specifically GPT-4, in the analysis of classroom dialogue, a crucial research task for both teaching diagnosis and quality improvement. Recognizing the knowledge-intensive and labor-intensive nature of traditional qualitative methods in educational research, this study investigates the potential of LLM to streamline and enhance the analysis process. The study involves datasets from a middle school, encompassing classroom dialogues across mathematics and Chinese classes. These dialogues were manually coded by educational experts and then analyzed using a customised GPT-4 model. This study focuses on comparing manual annotations with the outputs of GPT-4 to evaluate its efficacy in analyzing educational dialogues. Time efficiency, inter-coder agreement, and inter-coder reliability between human coders and GPT-4 are evaluated. Results indicate substantial time savings with GPT-4, and a high degree of consistency in coding between the model and human coders, with some discrepancies in specific codes. These findings highlight the strong potential of LLM in teaching evaluation and facilitation.
JaxPruner: A concise library for sparsity research
May 02, 2023


This paper introduces JaxPruner, an open-source JAX-based pruning and sparse training library for machine learning research. JaxPruner aims to accelerate research on sparse neural networks by providing concise implementations of popular pruning and sparse training algorithms with minimal memory and latency overhead. Algorithms implemented in JaxPruner use a common API and work seamlessly with the popular optimization library Optax, which, in turn, enables easy integration with existing JAX based libraries. We demonstrate this ease of integration by providing examples in four different codebases: Scenic, t5x, Dopamine and FedJAX and provide baseline experiments on popular benchmarks.
LayerNAS: Neural Architecture Search in Polynomial Complexity
Apr 23, 2023Neural Architecture Search (NAS) has become a popular method for discovering effective model architectures, especially for target hardware. As such, NAS methods that find optimal architectures under constraints are essential. In our paper, we propose LayerNAS to address the challenge of multi-objective NAS by transforming it into a combinatorial optimization problem, which effectively constrains the search complexity to be polynomial. For a model architecture with $L$ layers, we perform layerwise-search for each layer, selecting from a set of search options $\mathbb{S}$. LayerNAS groups model candidates based on one objective, such as model size or latency, and searches for the optimal model based on another objective, thereby splitting the cost and reward elements of the search. This approach limits the search complexity to $ O(H \cdot |\mathbb{S}| \cdot L) $, where $H$ is a constant set in LayerNAS. Our experiments show that LayerNAS is able to consistently discover superior models across a variety of search spaces in comparison to strong baselines, including search spaces derived from NATS-Bench, MobileNetV2 and MobileNetV3.
Data-Free Neural Architecture Search via Recursive Label Calibration
Dec 03, 2021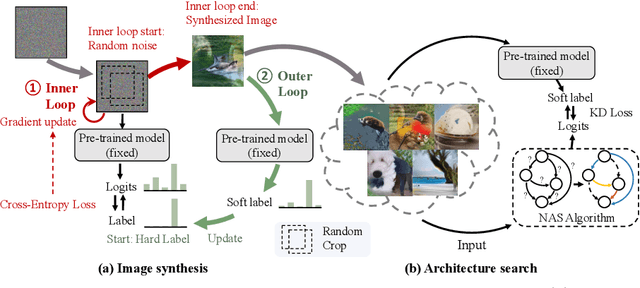
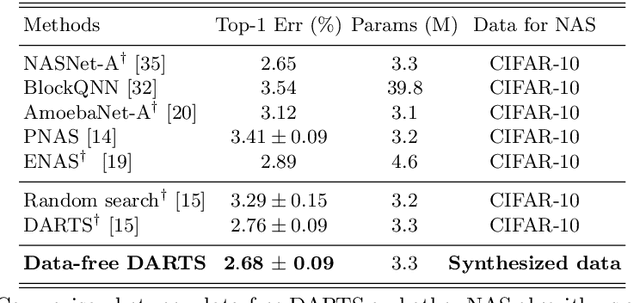
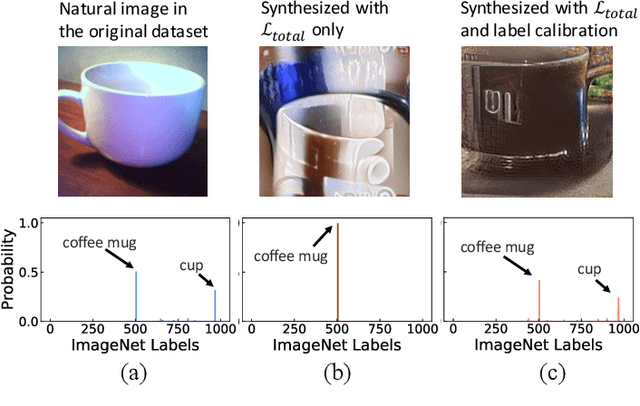
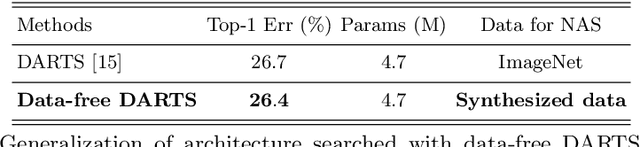
This paper aims to explore the feasibility of neural architecture search (NAS) given only a pre-trained model without using any original training data. This is an important circumstance for privacy protection, bias avoidance, etc., in real-world scenarios. To achieve this, we start by synthesizing usable data through recovering the knowledge from a pre-trained deep neural network. Then we use the synthesized data and their predicted soft-labels to guide neural architecture search. We identify that the NAS task requires the synthesized data (we target at image domain here) with enough semantics, diversity, and a minimal domain gap from the natural images. For semantics, we propose recursive label calibration to produce more informative outputs. For diversity, we propose a regional update strategy to generate more diverse and semantically-enriched synthetic data. For minimal domain gap, we use input and feature-level regularization to mimic the original data distribution in latent space. We instantiate our proposed framework with three popular NAS algorithms: DARTS, ProxylessNAS and SPOS. Surprisingly, our results demonstrate that the architectures discovered by searching with our synthetic data achieve accuracy that is comparable to, or even higher than, architectures discovered by searching from the original ones, for the first time, deriving the conclusion that NAS can be done effectively with no need of access to the original or called natural data if the synthesis method is well designed. Our code will be publicly available.
MagNet: Discovering Multi-agent Interaction Dynamics using Neural Network
Mar 03, 2020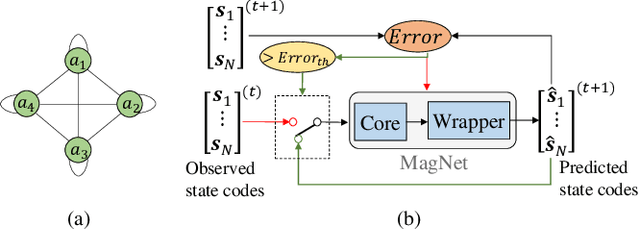
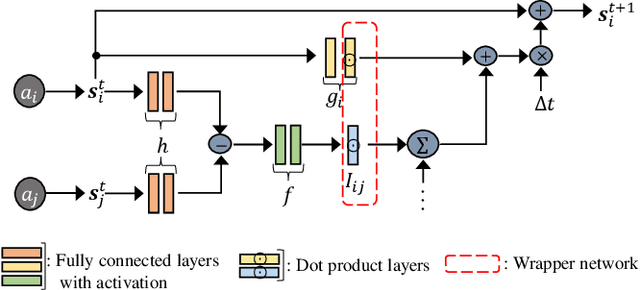
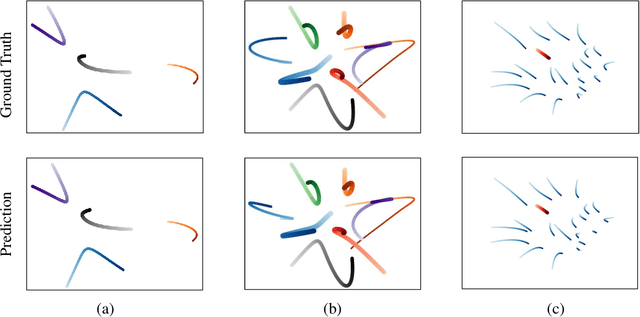
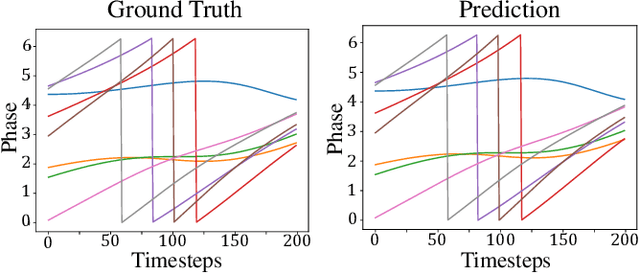
We present the MagNet, a neural network-based multi-agent interaction model to discover the governing dynamics and predict evolution of a complex multi-agent system from observations. We formulate a multi-agent system as a coupled non-linear network with a generic ordinary differential equation (ODE) based state evolution, and develop a neural network-based realization of its time-discretized model. MagNet is trained to discover the core dynamics of a multi-agent system from observations, and tuned on-line to learn agent-specific parameters of the dynamics to ensure accurate prediction even when physical or relational attributes of agents, or number of agents change. We evaluate MagNet on a point-mass system in two-dimensional space, Kuramoto phase synchronization dynamics and predator-swarm interaction dynamics demonstrating orders of magnitude improvement in prediction accuracy over traditional deep learning models.
Improving Robustness of ReRAM-based Spiking Neural Network Accelerator with Stochastic Spike-timing-dependent-plasticity
Sep 11, 2019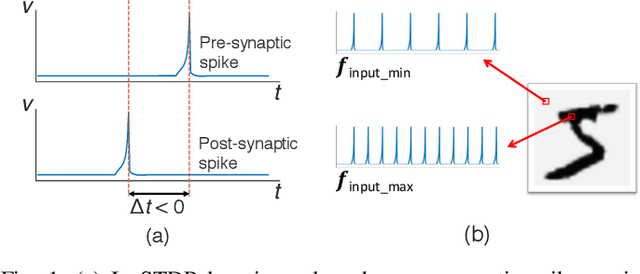
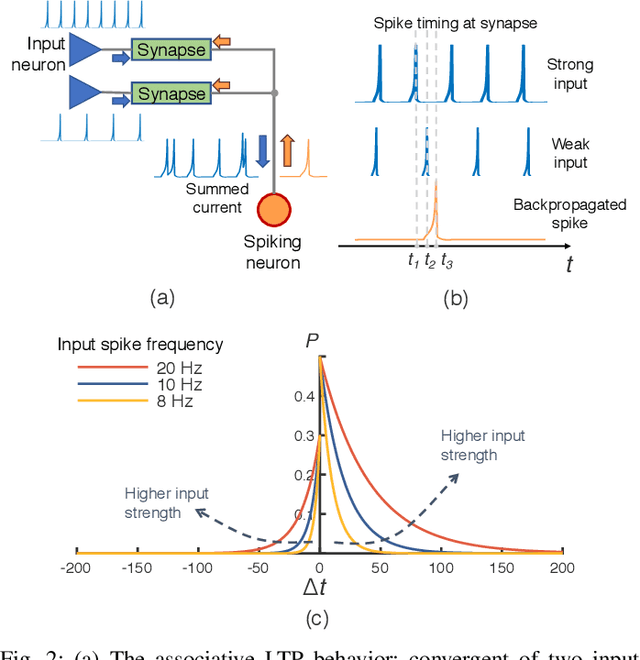
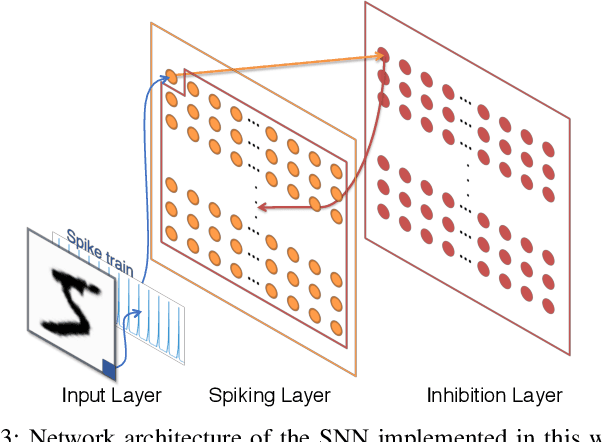
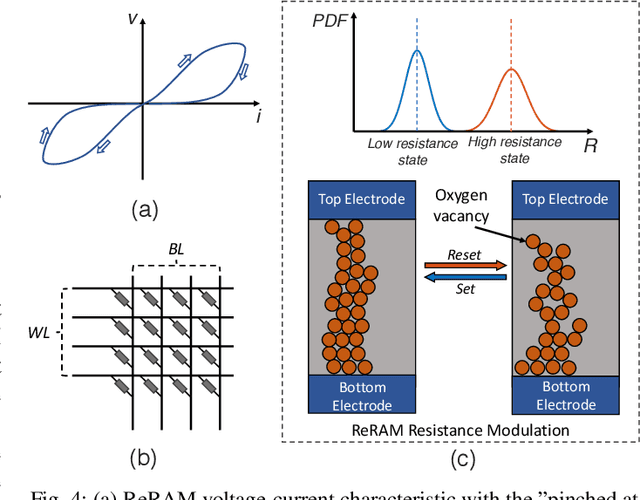
Spike-timing-dependent-plasticity (STDP) is an unsupervised learning algorithm for spiking neural network (SNN), which promises to achieve deeper understanding of human brain and more powerful artificial intelligence. While conventional computing system fails to simulate SNN efficiently, process-in-memory (PIM) based on devices such as ReRAM can be used in designing fast and efficient STDP based SNN accelerators, as it operates in high resemblance with biological neural network. However, the real-life implementation of such design still suffers from impact of input noise and device variation. In this work, we present a novel stochastic STDP algorithm that uses spiking frequency information to dynamically adjust synaptic behavior. The algorithm is tested in pattern recognition task with noisy input and shows accuracy improvement over deterministic STDP. In addition, we show that the new algorithm can be used for designing a robust ReRAM based SNN accelerator that has strong resilience to device variation.
ScieNet: Deep Learning with Spike-assisted Contextual Information Extraction
Sep 11, 2019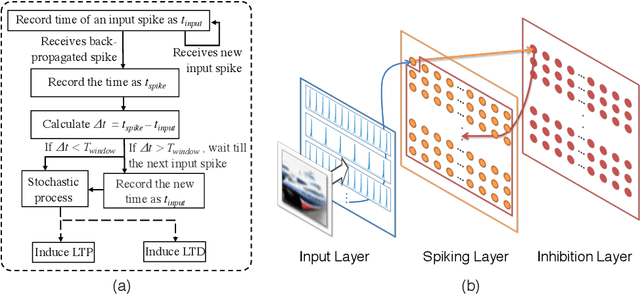
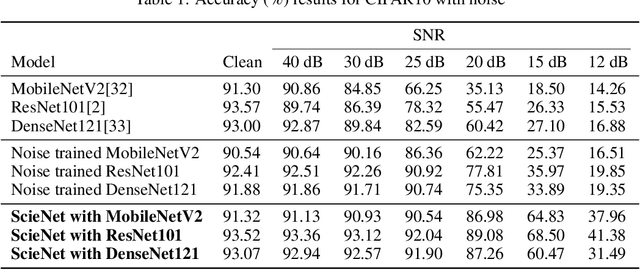
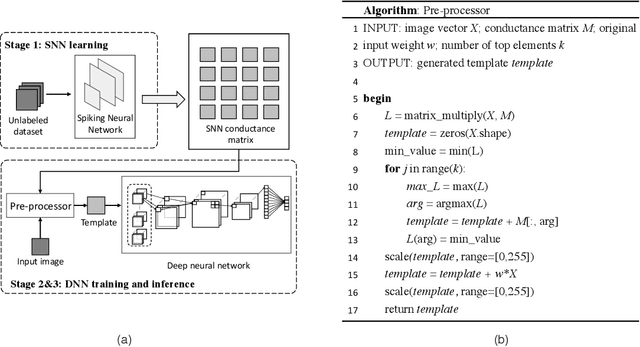
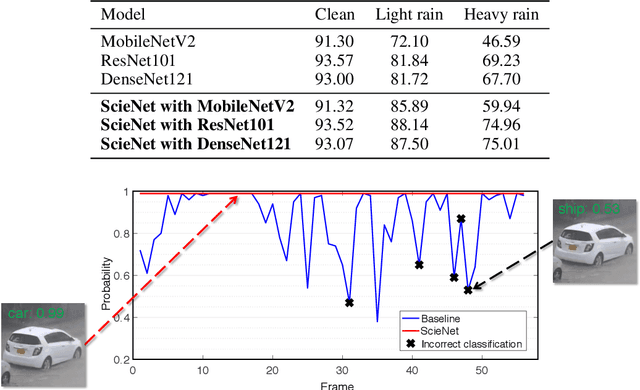
Deep neural networks (DNNs) provide high image classification accuracy, but experience significant performance degradation when perturbation from various sources are present in the input. The lack of resilience to input perturbations makes DNN less reliable for systems interacting with physical world such as autonomous vehicles, robotics, to name a few, where imperfect input is the normal condition. We present a hybrid deep network architecture with spike-assisted contextual information extraction (ScieNet). ScieNet integrates unsupervised learning using spiking neural network (SNN) for unsupervised contextual informationextraction with a back-end DNN trained for classification. The integrated network demonstrates high resilience to input perturbations without relying on prior training on perturbed inputs. We demonstrate ScieNet with different back-end DNNs for image classification using CIFAR dataset considering stochastic (noise) and structured (rain) input perturbations. Experimental results demonstrate significant improvement in accuracy on noisy and rainy images without prior training, while maintaining state-of-the-art accuracy on clean images.
HybridNet: Integrating Model-based and Data-driven Learning to Predict Evolution of Dynamical Systems
Jun 19, 2018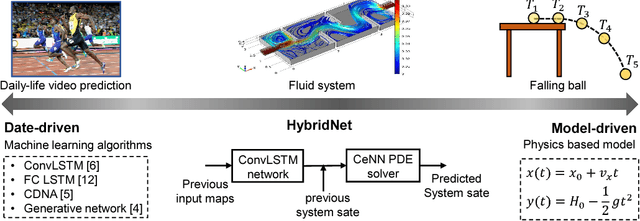

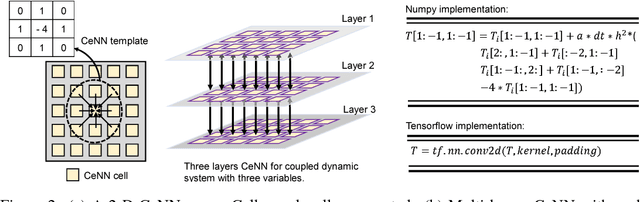
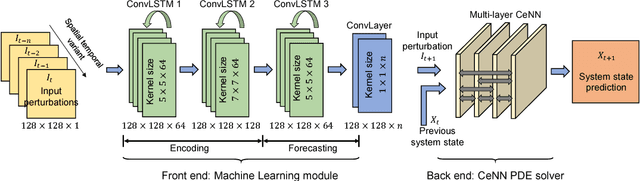
The robotic systems continuously interact with complex dynamical systems in the physical world. Reliable predictions of spatiotemporal evolution of these dynamical systems, with limited knowledge of system dynamics, are crucial for autonomous operation. In this paper, we present HybridNet, a framework that integrates data-driven deep learning and model-driven computation to reliably predict spatiotemporal evolution of a dynamical systems even with in-exact knowledge of their parameters. A data-driven deep neural network (DNN) with Convolutional LSTM (ConvLSTM) as the backbone is employed to predict the time-varying evolution of the external forces/perturbations. On the other hand, the model-driven computation is performed using Cellular Neural Network (CeNN), a neuro-inspired algorithm to model dynamical systems defined by coupled partial differential equations (PDEs). CeNN converts the intricate numerical computation into a series of convolution operations, enabling a trainable PDE solver. With a feedback control loop, HybridNet can learn the physical parameters governing the system's dynamics in real-time, and accordingly adapt the computation models to enhance prediction accuracy for time-evolving dynamical systems. The experimental results on two dynamical systems, namely, heat convection-diffusion system, and fluid dynamical system, demonstrate that the HybridNet produces higher accuracy than the state-of-the-art deep learning based approach.