 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression Scaling Laws:Unifying Sparsity and Quantization
Feb 23, 2025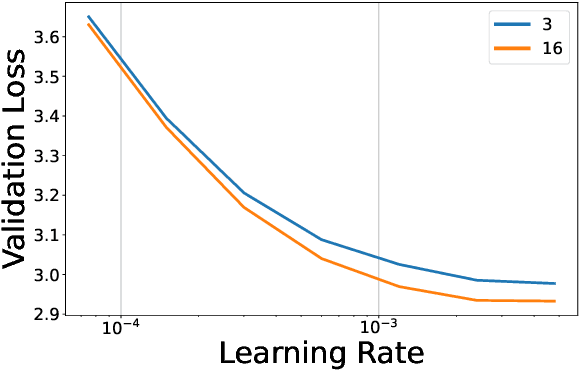
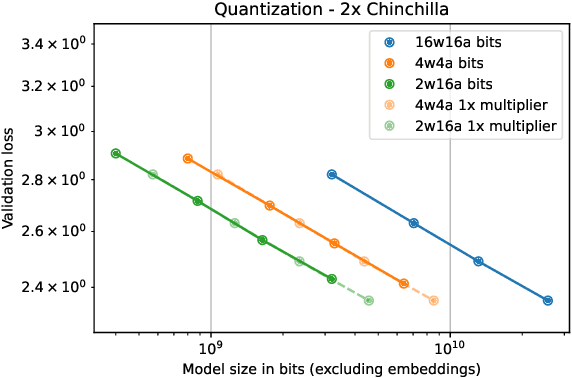
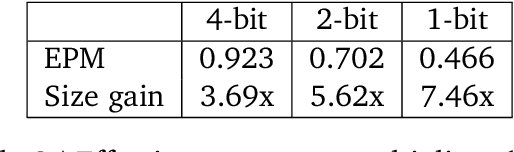
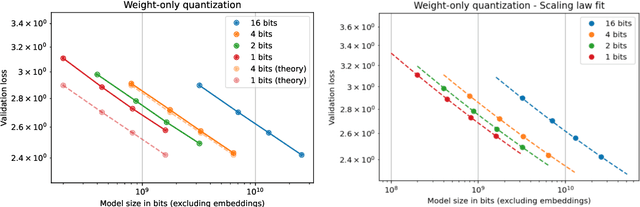
We investigate how different compression techniques -- such as weight and activation quantization, and weight sparsity -- affect the scaling behavior of large language models (LLMs) during pretraining. Building on previous work showing that weight sparsity acts as a constant multiplier on model size in scaling laws, we demonstrate that this "effective parameter" scaling pattern extends to quantization as well. Specifically, we establish that weight-only quantization achieves strong parameter efficiency multipliers, while full quantization of both weights and activations shows diminishing returns at lower bitwidths. Our results suggest that different compression techniques can be unified under a common scaling law framework, enabling principled comparison and combination of these methods.
MARLIN: Mixed-Precision Auto-Regressive Parallel Inference on Large Language Models
Aug 21, 2024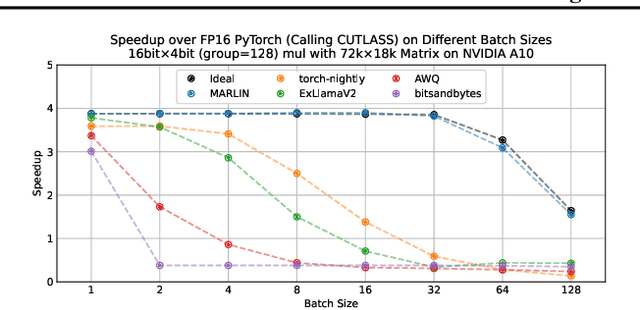
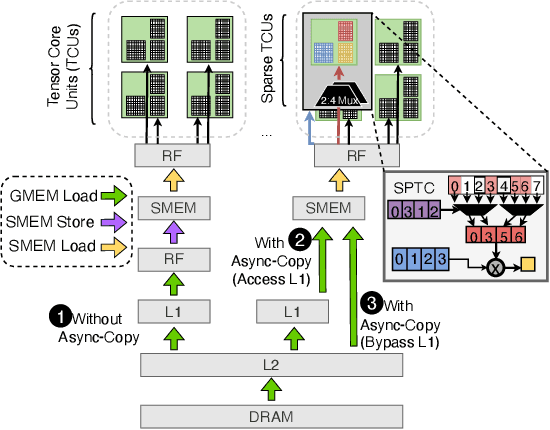
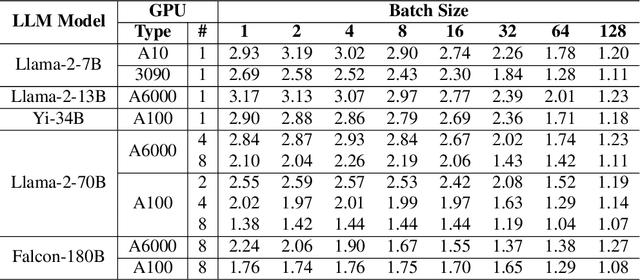
As inference on Large Language Models (LLMs) emerges as an important workload in machine learning applications, weight quantization has become a standard technique for efficient GPU deployment. Quantization not only reduces model size, but has also been shown to yield substantial speedups for single-user inference, due to reduced memory movement, with low accuracy impact. Yet, it remains open whether speedups are achievable also in \emph{batched} settings with multiple parallel clients, which are highly relevant for practical serving. It is unclear whether GPU kernels can be designed to remain practically memory-bound, while supporting the substantially increased compute requirements of batched workloads. This paper resolves this question positively by describing the design of Mixed-precision Auto-Regressive LINear kernels, called MARLIN. Concretely, given a model whose weights are compressed via quantization to, e.g., 4 bits per element, MARLIN shows that batchsizes up to 16-32 can be supported with close to maximum ($4\times$) quantization speedup, and larger batchsizes up to 64-128 with gradually decreasing, but still significant, acceleration. MARLIN accomplishes this via a combination of techniques, such as asynchronous memory access, complex task scheduling and pipelining, and bespoke quantization support. Our experiments show that MARLIN's near-optimal performance on individual LLM layers across different scenarios can also lead to end-to-end LLM inference speedups (of up to $2.8\times$) when integrated with the popular vLLM serving engine. Finally, MARLIN is extensible to further compression techniques, like NVIDIA 2:4 sparsity, leading to additional speedups.
Extreme Compression of Large Language Models via Additive Quantization
Jan 11, 2024



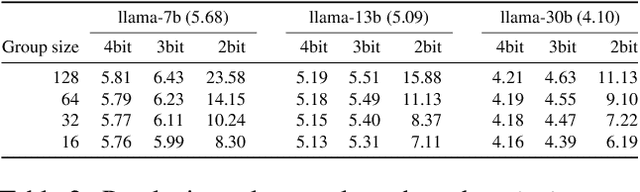
The emergence of accurate open large language models (LLMs) has led to a race towards quantization techniques for such models enabling execution on end-user devices. In this paper, we revisit the problem of "extreme" LLM compression--defined as targeting extremely low bit counts, such as 2 to 3 bits per parameter, from the point of view of classic methods in Multi-Codebook Quantization (MCQ). Our work builds on top of Additive Quantization, a classic algorithm from the MCQ family, and adapts it to the quantization of language models. The resulting algorithm advances the state-of-the-art in LLM compression, outperforming all recently-proposed techniques in terms of accuracy at a given compression budget. For instance, when compressing Llama 2 models to 2 bits per parameter, our algorithm quantizes the 7B model to 6.93 perplexity (a 1.29 improvement relative to the best prior work, and 1.81 points from FP16), the 13B model to 5.70 perplexity (a .36 improvement) and the 70B model to 3.94 perplexity (a .22 improvement) on WikiText2. We release our implementation of Additive Quantization for Language Models AQLM as a baseline to facilitate future research in LLM quantization.
QMoE: Practical Sub-1-Bit Compression of Trillion-Parameter Models
Oct 25, 2023Mixture-of-Experts (MoE) architectures offer a general solution to the high inference costs of large language models (LLMs) via sparse routing, bringing faster and more accurate models, at the cost of massive parameter counts. For example, the SwitchTransformer-c2048 model has 1.6 trillion parameters, requiring 3.2TB of accelerator memory to run efficiently, which makes practical deployment challenging and expensive. In this paper, we present a solution to this memory problem, in form of a new compression and execution framework called QMoE. Specifically, QMoE consists of a scalable algorithm which accurately compresses trillion-parameter MoEs to less than 1 bit per parameter, in a custom format co-designed with bespoke GPU decoding kernels to facilitate efficient end-to-end compressed inference, with minor runtime overheads relative to uncompressed execution. Concretely, QMoE can compress the 1.6 trillion parameter SwitchTransformer-c2048 model to less than 160GB (20x compression, 0.8 bits per parameter) at only minor accuracy loss, in less than a day on a single GPU. This enables, for the first time, the execution of a trillion-parameter model on affordable commodity hardware, like a single server with 4x NVIDIA A6000 or 8x NVIDIA 3090 GPUs, at less than 5% runtime overhead relative to ideal uncompressed inference. The source code and compressed models are available at github.com/IST-DASLab/qmoe.
Sparse Fine-tuning for Inference Acceleration of Large Language Models
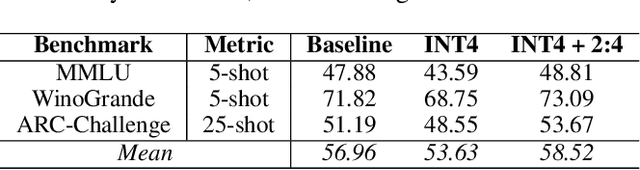
Oct 13, 2023We consider the problem of accurate sparse fine-tuning of large language models (LLMs), that is, fine-tuning pretrained LLMs on specialized tasks, while inducing sparsity in their weights. On the accuracy side, we observe that standard loss-based fine-tuning may fail to recover accuracy, especially at high sparsities. To address this, we perform a detailed study of distillation-type losses, determining an L2-based distillation approach we term SquareHead which enables accurate recovery even at higher sparsities, across all model types. On the practical efficiency side, we show that sparse LLMs can be executed with speedups by taking advantage of sparsity, for both CPU and GPU runtimes. While the standard approach is to leverage sparsity for computational reduction, we observe that in the case of memory-bound LLMs sparsity can also be leveraged for reducing memory bandwidth. We exhibit end-to-end results showing speedups due to sparsity, while recovering accuracy, on T5 (language translation), Whisper (speech translation), and open GPT-type (MPT for text generation). For MPT text generation, we show for the first time that sparse fine-tuning can reach 75% sparsity without accuracy drops, provide notable end-to-end speedups for both CPU and GPU inference, and highlight that sparsity is also compatible with quantization approaches. Models and software for reproducing our results are provided in Section 6.
Towards End-to-end 4-Bit Inference on Generative Large Language Models
Oct 13, 2023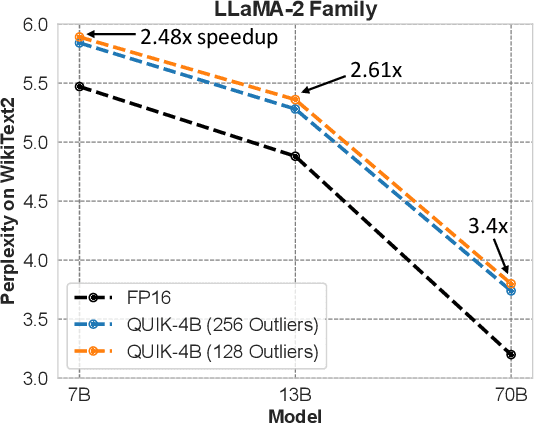
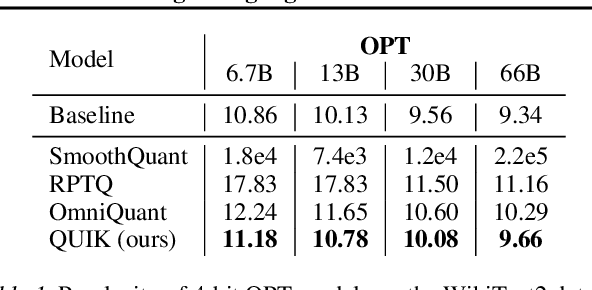
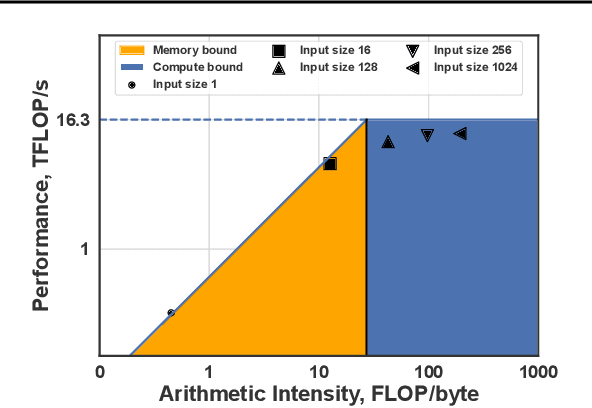
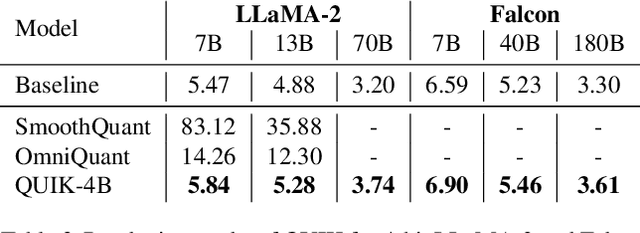
We show that the majority of the inference computations for large generative models such as LLaMA and OPT can be performed with both weights and activations being cast to 4 bits, in a way that leads to practical speedups while at the same time maintaining good accuracy. We achieve this via a hybrid quantization strategy called QUIK, which compresses most of the weights and activations to 4-bit, while keeping some outlier weights and activations in higher-precision. Crucially, our scheme is designed with computational efficiency in mind: we provide GPU kernels with highly-efficient layer-wise runtimes, which lead to practical end-to-end throughput improvements of up to 3.1x relative to FP16 execution. Code and models are provided at https://github.com/IST-DASLab/QUIK.
Scaling Laws for Sparsely-Connected Foundation Models
Sep 15, 2023We explore the impact of parameter sparsity on the scaling behavior of Transformers trained on massive datasets (i.e., "foundation models"), in both vision and language domains. In this setting, we identify the first scaling law describing the relationship between weight sparsity, number of non-zero parameters, and amount of training data, which we validate empirically across model and data scales; on ViT/JFT-4B and T5/C4. These results allow us to characterize the "optimal sparsity", the sparsity level which yields the best performance for a given effective model size and training budget. For a fixed number of non-zero parameters, we identify that the optimal sparsity increases with the amount of data used for training. We also extend our study to different sparsity structures (such as the hardware-friendly n:m pattern) and strategies (such as starting from a pretrained dense model). Our findings shed light on the power and limitations of weight sparsity across various parameter and computational settings, offering both theoretical understanding and practical implications for leveraging sparsity towards computational efficiency improvements.
Accurate Neural Network Pruning Requires Rethinking Sparse Optimization
Aug 03, 2023Obtaining versions of deep neural networks that are both highly-accurate and highly-sparse is one of the main challenges in the area of model compression, and several high-performance pruning techniques have been investigated by the community. Yet, much less is known about the interaction between sparsity and the standard stochastic optimization techniques used for training sparse networks, and most existing work uses standard dense schedules and hyperparameters for training sparse networks. In this work, we examine the impact of high sparsity on model training using the standard computer vision and natural language processing sparsity benchmarks. We begin by showing that using standard dense training recipes for sparse training is suboptimal, and results in under-training. We provide new approaches for mitigating this issue for both sparse pre-training of vision models (e.g. ResNet50/ImageNet) and sparse fine-tuning of language models (e.g. BERT/GLUE), achieving state-of-the-art results in both settings in the high-sparsity regime, and providing detailed analyses for the difficulty of sparse training in both scenarios. Our work sets a new threshold in terms of the accuracies that can be achieved under high sparsity, and should inspire further research into improving sparse model training, to reach higher accuracies under high sparsity, but also to do so efficiently.
QIGen: Generating Efficient Kernels for Quantized Inference on Large Language Models
Jul 07, 2023


We present ongoing work on a new automatic code generation approach for supporting quantized generative inference on LLMs such as LLaMA or OPT on off-the-shelf CPUs. Our approach is informed by the target architecture and a performance model, including both hardware characteristics and method-specific accuracy constraints. Results on CPU-based inference for LLaMA models show that our approach can lead to high performance and high accuracy, comparing favorably to the best existing open-source solution. A preliminary implementation is available at https://github.com/IST-DASLab/QIGen.
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
Jun 05, 2023

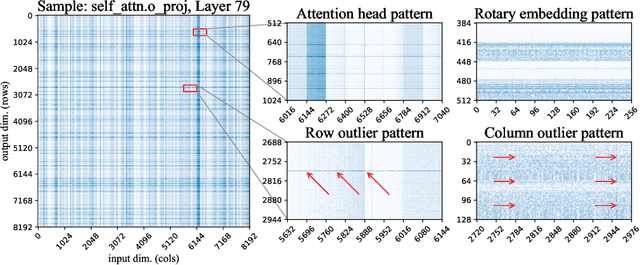

Recent advances in large language model (LLM) pretraining have led to high-quality LLMs with impressive abilities. By compressing such LLMs via quantization to 3-4 bits per parameter, they can fit into memory-limited devices such as laptops and mobile phones, enabling personalized use. However, quantization down to 3-4 bits per parameter usually leads to moderate-to-high accuracy losses, especially for smaller models in the 1-10B parameter range, which are well-suited for edge deployments. To address this accuracy issue, we introduce the Sparse-Quantized Representation (SpQR), a new compressed format and quantization technique which enables for the first time near-lossless compression of LLMs across model scales, while reaching similar compression levels to previous methods. SpQR works by identifying and isolating outlier weights, which cause particularly-large quantization errors, and storing them in higher precision, while compressing all other weights to 3-4 bits, and achieves relative accuracy losses of less than 1% in perplexity for highly-accurate LLaMA and Falcon LLMs. This makes it possible to run 33B parameter LLM on a single 24 GB consumer GPU without any performance degradation at 15% speedup thus making powerful LLMs available to consumer without any downsides. SpQR comes with efficient algorithms for both encoding weights into its format, as well as decoding them efficiently at runtime. Specifically, we provide an efficient GPU inference algorithm for SpQR which yields faster inference than 16-bit baselines at similar accuracy, while enabling memory compression gains of more than 4x.