 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Inference and Fine-tuning of Large Language Models Over The Internet
Dec 13, 2023



Large language models (LLMs) are useful in many NLP tasks and become more capable with size, with the best open-source models having over 50 billion parameters. However, using these 50B+ models requires high-end hardware, making them inaccessible to most researchers. In this work, we investigate methods for cost-efficient inference and fine-tuning of LLMs, comparing local and distributed strategies. We observe that a large enough model (50B+) can run efficiently even on geodistributed devices in a consumer-grade network. This could allow running LLM efficiently by pooling together idle compute resources of multiple research groups and volunteers. We address two open problems: (1) how to perform inference and fine-tuning reliably if any device can disconnect abruptly and (2) how to partition LLMs between devices with uneven hardware, joining and leaving at will. In order to do that, we develop special fault-tolerant inference algorithms and load-balancing protocols that automatically assign devices to maximize the total system throughput. We showcase these algorithms in Petals - a decentralized system that runs Llama 2 (70B) and BLOOM (176B) over the Internet up to 10x faster than offloading for interactive generation. We evaluate the performance of our system in simulated conditions and a real-world setup spanning two continents.
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
Jun 05, 2023Recent advances in large language model (LLM) pretraining have led to high-quality LLMs with impressive abilities. By compressing such LLMs via quantization to 3-4 bits per parameter, they can fit into memory-limited devices such as laptops and mobile phones, enabling personalized use. However, quantization down to 3-4 bits per parameter usually leads to moderate-to-high accuracy losses, especially for smaller models in the 1-10B parameter range, which are well-suited for edge deployments. To address this accuracy issue, we introduce the Sparse-Quantized Representation (SpQR), a new compressed format and quantization technique which enables for the first time near-lossless compression of LLMs across model scales, while reaching similar compression levels to previous methods. SpQR works by identifying and isolating outlier weights, which cause particularly-large quantization errors, and storing them in higher precision, while compressing all other weights to 3-4 bits, and achieves relative accuracy losses of less than 1% in perplexity for highly-accurate LLaMA and Falcon LLMs. This makes it possible to run 33B parameter LLM on a single 24 GB consumer GPU without any performance degradation at 15% speedup thus making powerful LLMs available to consumer without any downsides. SpQR comes with efficient algorithms for both encoding weights into its format, as well as decoding them efficiently at runtime. Specifically, we provide an efficient GPU inference algorithm for SpQR which yields faster inference than 16-bit baselines at similar accuracy, while enabling memory compression gains of more than 4x.
SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient
Jan 27, 2023



Many deep learning applications benefit from using large models with billions of parameters. Training these models is notoriously expensive due to the need for specialized HPC clusters. In this work, we consider alternative setups for training large models: using cheap "preemptible" instances or pooling existing resources from multiple regions. We analyze the performance of existing model-parallel algorithms in these conditions and find configurations where training larger models becomes less communication-intensive. Based on these findings, we propose SWARM parallelism, a model-parallel training algorithm designed for poorly connected, heterogeneous and unreliable devices. SWARM creates temporary randomized pipelines between nodes that are rebalanced in case of failure. We empirically validate our findings and compare SWARM parallelism with existing large-scale training approaches. Finally, we combine our insights with compression strategies to train a large Transformer language model with 1B shared parameters (approximately 13B before sharing) on preemptible T4 GPUs with less than 200Mb/s network.
Petals: Collaborative Inference and Fine-tuning of Large Models
Sep 02, 2022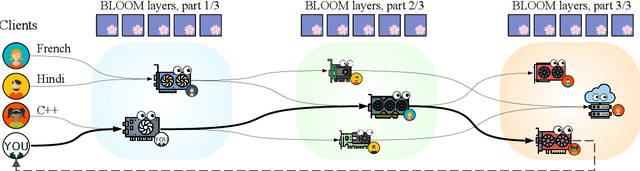


Many NLP tasks benefit from using large language models (LLMs) that often have more than 100 billion parameters. With the release of BLOOM-176B and OPT-175B, everyone can download pretrained models of this scale. Still, using these models requires high-end hardware unavailable to many researchers. In some cases, LLMs can be used more affordably via RAM offloading or hosted APIs. However, these techniques have innate limitations: offloading is too slow for interactive inference, while APIs are not flexible enough for research. In this work, we propose Petals $-$ a system for inference and fine-tuning of large models collaboratively by joining the resources of multiple parties trusted to process client's data. We demonstrate that this strategy significantly outperforms offloading for very large models, running inference of BLOOM-176B on consumer GPUs with $\approx$ 1 step per second. Unlike most inference APIs, Petals also natively exposes the hidden states of served models, allowing its users to train and share custom model extensions based on efficient fine-tuning methods.
Training Transformers Together
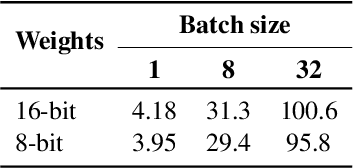
Jul 07, 2022

The infrastructure necessary for training state-of-the-art models is becoming overly expensive, which makes training such models affordable only to large corporations and institutions. Recent work proposes several methods for training such models collaboratively, i.e., by pooling together hardware from many independent parties and training a shared model over the Internet. In this demonstration, we collaboratively trained a text-to-image transformer similar to OpenAI DALL-E. We invited the viewers to join the ongoing training run, showing them instructions on how to contribute using the available hardware. We explained how to address the engineering challenges associated with such a training run (slow communication, limited memory, uneven performance between devices, and security concerns) and discussed how the viewers can set up collaborative training runs themselves. Finally, we show that the resulting model generates images of reasonable quality on a number of prompts.
Secure Distributed Training at Scale
Jun 21, 2021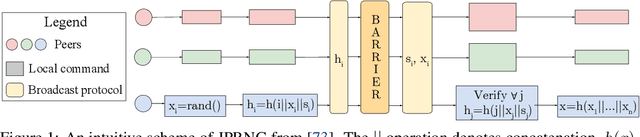
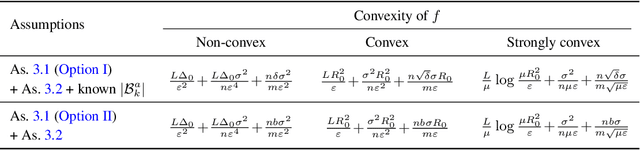
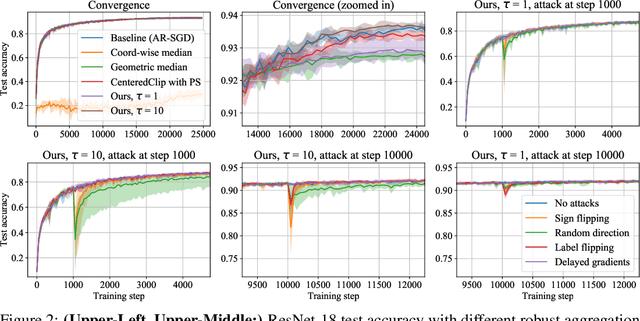
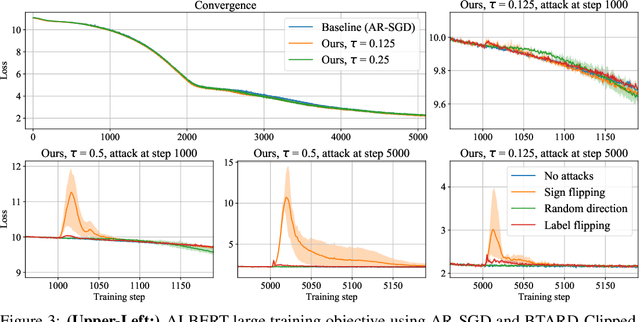
Some of the hardest problems in deep learning can be solved with the combined effort of many independent parties, as is the case for volunteer computing and federated learning. These setups rely on high numbers of peers to provide computational resources or train on decentralized datasets. Unfortunately, participants in such systems are not always reliable. Any single participant can jeopardize the entire training run by sending incorrect updates, whether deliberately or by mistake. Training in presence of such peers requires specialized distributed training algorithms with Byzantine tolerance. These algorithms often sacrifice efficiency by introducing redundant communication or passing all updates through a trusted server. As a result, it can be infeasible to apply such algorithms to large-scale distributed deep learning, where models can have billions of parameters. In this work, we propose a novel protocol for secure (Byzantine-tolerant) decentralized training that emphasizes communication efficiency. We rigorously analyze this protocol: in particular, we provide theoretical bounds for its resistance against Byzantine and Sybil attacks and show that it has a marginal communication overhead. To demonstrate its practical effectiveness, we conduct large-scale experiments on image classification and language modeling in presence of Byzantine attackers.
Distributed Deep Learning in Open Collaborations
Jun 18, 2021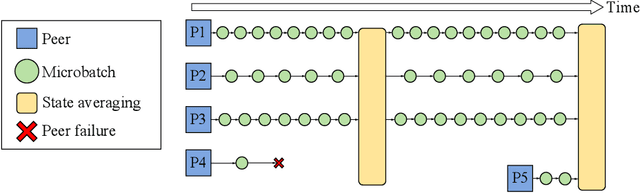
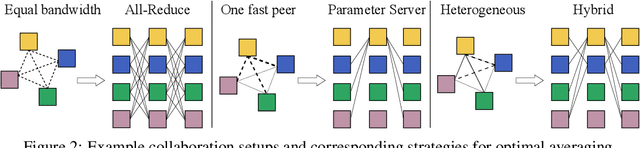
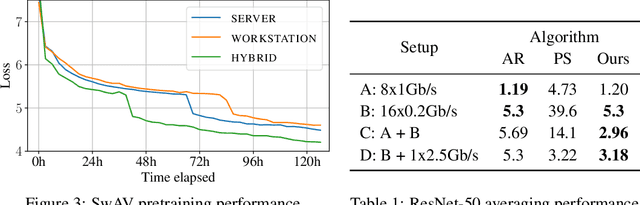

Modern deep learning applications require increasingly more compute to train state-of-the-art models. To address this demand, large corporations and institutions use dedicated High-Performance Computing clusters, whose construction and maintenance are both environmentally costly and well beyond the budget of most organizations. As a result, some research directions become the exclusive domain of a few large industrial and even fewer academic actors. To alleviate this disparity, smaller groups may pool their computational resources and run collaborative experiments that benefit all participants. This paradigm, known as grid- or volunteer computing, has seen successful applications in numerous scientific areas. However, using this approach for machine learning is difficult due to high latency, asymmetric bandwidth, and several challenges unique to volunteer computing. In this work, we carefully analyze these constraints and propose a novel algorithmic framework designed specifically for collaborative training. We demonstrate the effectiveness of our approach for SwAV and ALBERT pretraining in realistic conditions and achieve performance comparable to traditional setups at a fraction of the cost. Finally, we provide a detailed report of successful collaborative language model pretraining with 40 participants.