 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSERA: Soft-Verified Efficient Repository Agents
Jan 28, 2026Open-weight coding agents should hold a fundamental advantage over closed-source systems: they can be specialized to private codebases, encoding repository-specific information directly in their weights. Yet the cost and complexity of training has kept this advantage theoretical. We show it is now practical. We present Soft-Verified Efficient Repository Agents (SERA), an efficient method for training coding agents that enables the rapid and cheap creation of agents specialized to private codebases. Using only supervised finetuning (SFT), SERA achieves state-of-the-art results among fully open-source (open data, method, code) models while matching the performance of frontier open-weight models like Devstral-Small-2. Creating SERA models is 26x cheaper than reinforcement learning and 57x cheaper than previous synthetic data methods to reach equivalent performance. Our method, Soft Verified Generation (SVG), generates thousands of trajectories from a single code repository. Combined with cost-efficiency, this enables specialization to private codebases. Beyond repository specialization, we apply SVG to a larger corpus of codebases, generating over 200,000 synthetic trajectories. We use this dataset to provide detailed analysis of scaling laws, ablations, and confounding factors for training coding agents. Overall, we believe our work will greatly accelerate research on open coding agents and showcase the advantage of open-source models that can specialize to private codebases. We release SERA as the first model in Ai2's Open Coding Agents series, along with all our code, data, and Claude Code integration to support the research community.
OLMoE: Open Mixture-of-Experts Language Models
Sep 03, 2024



We introduce OLMoE, a fully open, state-of-the-art language model leveraging sparse Mixture-of-Experts (MoE). OLMoE-1B-7B has 7 billion (B) parameters but uses only 1B per input token. We pretrain it on 5 trillion tokens and further adapt it to create OLMoE-1B-7B-Instruct. Our models outperform all available models with similar active parameters, even surpassing larger ones like Llama2-13B-Chat and DeepSeekMoE-16B. We present various experiments on MoE training, analyze routing in our model showing high specialization, and open-source all aspects of our work: model weights, training data, code, and logs.
Distributed Inference and Fine-tuning of Large Language Models Over The Internet
Dec 13, 2023



Large language models (LLMs) are useful in many NLP tasks and become more capable with size, with the best open-source models having over 50 billion parameters. However, using these 50B+ models requires high-end hardware, making them inaccessible to most researchers. In this work, we investigate methods for cost-efficient inference and fine-tuning of LLMs, comparing local and distributed strategies. We observe that a large enough model (50B+) can run efficiently even on geodistributed devices in a consumer-grade network. This could allow running LLM efficiently by pooling together idle compute resources of multiple research groups and volunteers. We address two open problems: (1) how to perform inference and fine-tuning reliably if any device can disconnect abruptly and (2) how to partition LLMs between devices with uneven hardware, joining and leaving at will. In order to do that, we develop special fault-tolerant inference algorithms and load-balancing protocols that automatically assign devices to maximize the total system throughput. We showcase these algorithms in Petals - a decentralized system that runs Llama 2 (70B) and BLOOM (176B) over the Internet up to 10x faster than offloading for interactive generation. We evaluate the performance of our system in simulated conditions and a real-world setup spanning two continents.
MatFormer: Nested Transformer for Elastic Inference
Oct 11, 2023



Transformer models are deployed in a wide range of settings, from multi-accelerator clusters to standalone mobile phones. The diverse inference constraints in these scenarios necessitate practitioners to train foundation models such as PaLM 2, Llama, & ViTs as a series of models of varying sizes. Due to significant training costs, only a select few model sizes are trained and supported, limiting more fine-grained control over relevant tradeoffs, including latency, cost, and accuracy. This work introduces MatFormer, a nested Transformer architecture designed to offer elasticity in a variety of deployment constraints. Each Feed Forward Network (FFN) block of a MatFormer model is jointly optimized with a few nested smaller FFN blocks. This training procedure allows for the Mix'n'Match of model granularities across layers -- i.e., a trained universal MatFormer model enables extraction of hundreds of accurate smaller models, which were never explicitly optimized. We empirically demonstrate MatFormer's effectiveness across different model classes (decoders & encoders), modalities (language & vision), and scales (up to 2.6B parameters). We find that a 2.6B decoder-only MatFormer language model (MatLM) allows us to extract smaller models spanning from 1.5B to 2.6B, each exhibiting comparable validation loss and one-shot downstream evaluations to their independently trained counterparts. Furthermore, we observe that smaller encoders extracted from a universal MatFormer-based ViT (MatViT) encoder preserve the metric-space structure for adaptive large-scale retrieval. Finally, we showcase that speculative decoding with the accurate and consistent submodels extracted from MatFormer can further reduce inference latency.
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
Jun 05, 2023

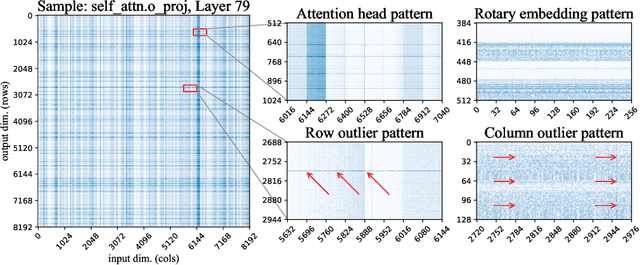

Recent advances in large language model (LLM) pretraining have led to high-quality LLMs with impressive abilities. By compressing such LLMs via quantization to 3-4 bits per parameter, they can fit into memory-limited devices such as laptops and mobile phones, enabling personalized use. However, quantization down to 3-4 bits per parameter usually leads to moderate-to-high accuracy losses, especially for smaller models in the 1-10B parameter range, which are well-suited for edge deployments. To address this accuracy issue, we introduce the Sparse-Quantized Representation (SpQR), a new compressed format and quantization technique which enables for the first time near-lossless compression of LLMs across model scales, while reaching similar compression levels to previous methods. SpQR works by identifying and isolating outlier weights, which cause particularly-large quantization errors, and storing them in higher precision, while compressing all other weights to 3-4 bits, and achieves relative accuracy losses of less than 1% in perplexity for highly-accurate LLaMA and Falcon LLMs. This makes it possible to run 33B parameter LLM on a single 24 GB consumer GPU without any performance degradation at 15% speedup thus making powerful LLMs available to consumer without any downsides. SpQR comes with efficient algorithms for both encoding weights into its format, as well as decoding them efficiently at runtime. Specifically, we provide an efficient GPU inference algorithm for SpQR which yields faster inference than 16-bit baselines at similar accuracy, while enabling memory compression gains of more than 4x.
Towards A Unified View of Sparse Feed-Forward Network in Pretraining Large Language Model
May 23, 2023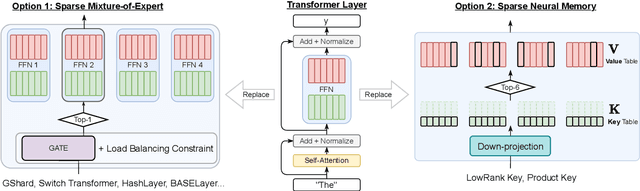
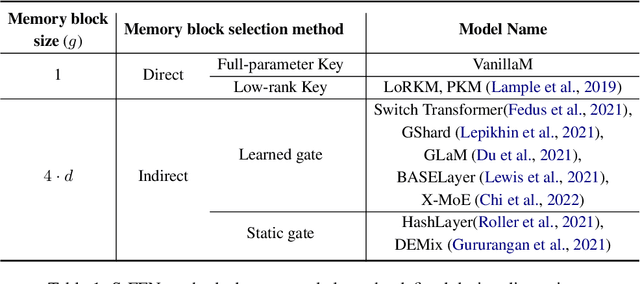

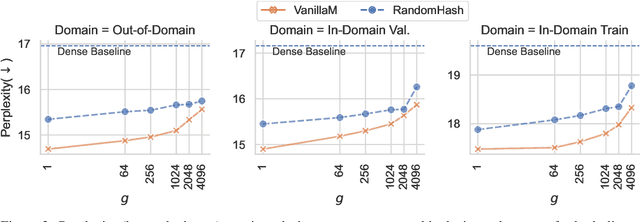
Large and sparse feed-forward networks (S-FFN) such as Mixture-of-Experts (MoE) have demonstrated to be an efficient approach for scaling up Transformers model size for pretraining large language models. By only activating part of the FFN parameters conditioning on input, S-FFN improves generalization performance while keeping training and inference costs (in FLOPs) fixed. In this work, we analyzed the two major design choices of S-FFN: the memory block (or expert) size and the memory block selection method under a general conceptual framework of sparse neural memory. Using this unified framework, we compare several S-FFN architectures for language modeling and provide insights into their relative efficacy and efficiency. From our analysis results, we found a simpler selection method -- Avg-K that selects blocks through their mean aggregated hidden states, achieves lower perplexity in language modeling pretraining compared to existing MoE architectures.
QLoRA: Efficient Finetuning of Quantized LLMs
May 23, 2023



We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters~(LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) paged optimziers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA. We provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation. Furthermore, we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots. A lemon-picked analysis demonstrates where Guanaco fails compared to ChatGPT. We release all of our models and code, including CUDA kernels for 4-bit training.
Stable and low-precision training for large-scale vision-language models
Apr 25, 2023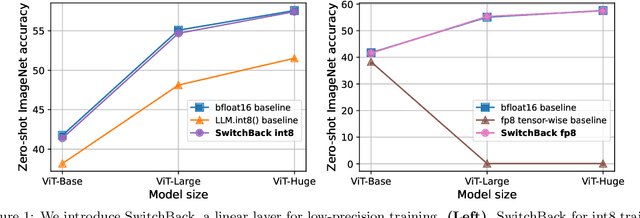
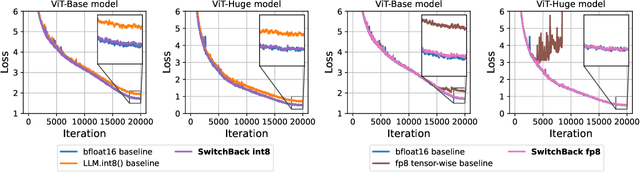
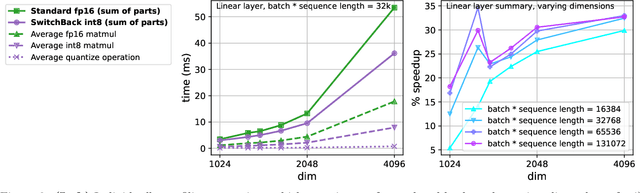
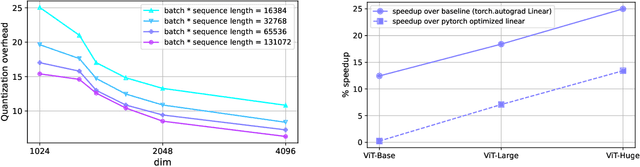
We introduce new methods for 1) accelerating and 2) stabilizing training for large language-vision models. 1) Towards accelerating training, we introduce SwitchBack, a linear layer for int8 quantized training which provides a speed-up of 13-25% while matching the performance of bfloat16 training within 0.1 percentage points for the 1B parameter CLIP ViT-Huge -- the largest int8 training to date. Our main focus is int8 as GPU support for float8 is rare, though we also analyze float8 training through simulation. While SwitchBack proves effective for float8, we show that standard techniques are also successful if the network is trained and initialized so that large feature magnitudes are discouraged, which we accomplish via layer-scale initialized with zeros. 2) Towards stable training, we analyze loss spikes and find they consistently occur 1-8 iterations after the squared gradients become under-estimated by their AdamW second moment estimator. As a result, we recommend an AdamW-Adafactor hybrid, which we refer to as StableAdamW because it avoids loss spikes when training a CLIP ViT-Huge model and outperforms gradient clipping.
SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient
Jan 27, 2023



Many deep learning applications benefit from using large models with billions of parameters. Training these models is notoriously expensive due to the need for specialized HPC clusters. In this work, we consider alternative setups for training large models: using cheap "preemptible" instances or pooling existing resources from multiple regions. We analyze the performance of existing model-parallel algorithms in these conditions and find configurations where training larger models becomes less communication-intensive. Based on these findings, we propose SWARM parallelism, a model-parallel training algorithm designed for poorly connected, heterogeneous and unreliable devices. SWARM creates temporary randomized pipelines between nodes that are rebalanced in case of failure. We empirically validate our findings and compare SWARM parallelism with existing large-scale training approaches. Finally, we combine our insights with compression strategies to train a large Transformer language model with 1B shared parameters (approximately 13B before sharing) on preemptible T4 GPUs with less than 200Mb/s network.
The case for 4-bit precision: k-bit Inference Scaling Laws
Dec 19, 2022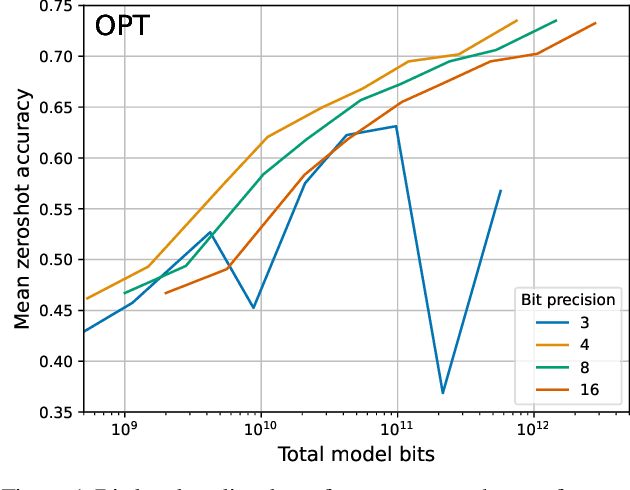
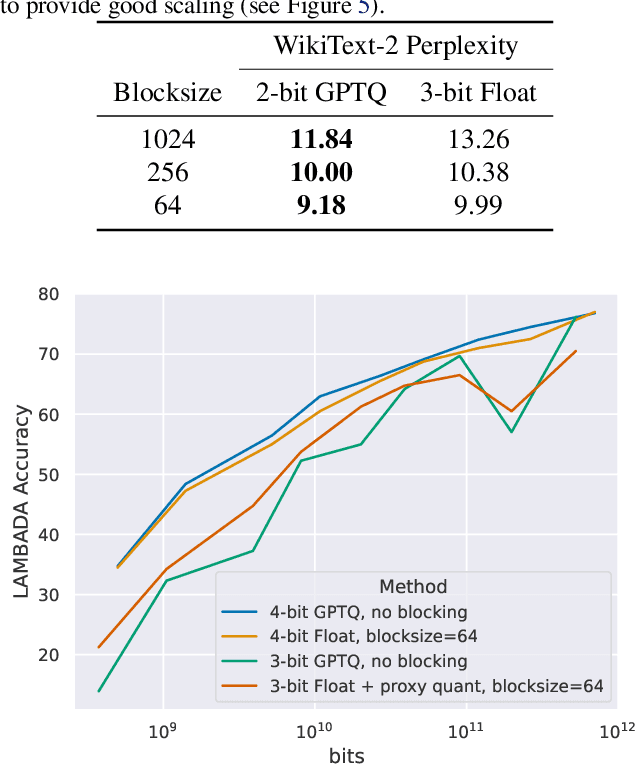
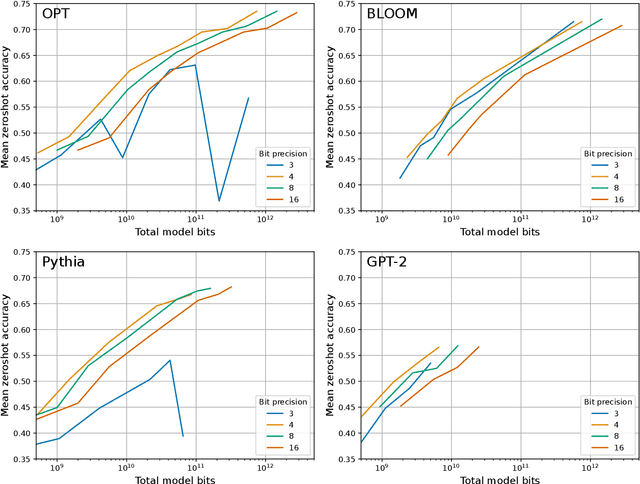
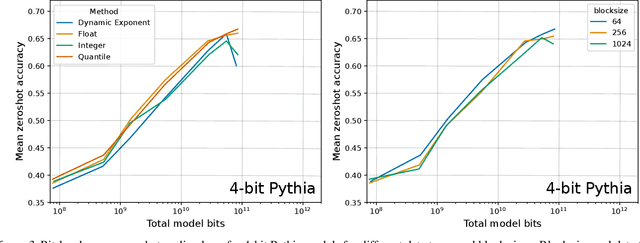
Quantization methods reduce the number of bits required to represent each parameter in a model, trading accuracy for smaller memory footprints and inference latencies. However, the final model size depends on both the number of parameters of the original model and the rate of compression. For example, a 30B 8-bit model and a 60B 4-bit model have the same number of bits but may have very different zero-shot accuracies. In this work, we study this trade-off by developing inference scaling laws of zero-shot performance in Large Language Models (LLMs) to determine the bit-precision and model size that maximizes zero-shot performance. We run more than 35,000 zero-shot experiments with 16-bit inputs and k-bit parameters to examine which quantization methods improve scaling for 3 to 8-bit precision at scales of 19M to 66B parameters across the LLM families BLOOM, OPT, NeoX/Pythia, and GPT-2. We find that it is challenging to improve the bit-level scaling trade-off, with the only improvements being the use of a small block size -- splitting the parameters into small independently quantized blocks -- and the quantization data type being used (e.g., Int vs Float). Overall, our findings show that 4-bit precision is almost universally optimal for total model bits and zero-shot accuracy.