 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaguna M.1/XS.2 Technical Report
May 26, 2026We present Laguna M.1 and Laguna XS.2, two Mixture-of-Experts foundation models built for long-horizon, agentic coding: M.1 has $225.8$B total parameters ($23.4$B activated per token) and XS.2 has $33.4$B total ($3$B activated). Both models were trained from scratch end-to-end inside the same internal system that we refer to as our Model Factory: a tightly-integrated stack of versioned data, training, evaluation, and inference components that turn model development into an industrial process. We describe the principles and design choices of the Model Factory and also detail the end-to-end training process of our models, throughout pre-training data and architecture, post-training stages, evaluation, and quantization. On agentic software engineering and terminal benchmarks (SWE-bench Verified, SWE-bench Multilingual, SWE-Bench Pro, and Terminal-Bench 2.0) M.1 and XS.2 are competitive with state-of-the-art open models in their respective weight classes. Laguna XS.2 weights are released under Apache~2.0 at https://huggingface.co/collections/poolside/laguna-xs2.
Agents Explore but Agents Ignore: LLMs Lack Environmental Curiosity
Apr 19, 2026LLM-based agents are assumed to integrate environmental observations into their reasoning: discovering highly relevant but unexpected information should naturally lead to a model exploiting its own discoveries. We show that this assumption is false for current LLM-based agents, which struggle to reflect or react to unexpected information. Across three benchmarks (Terminal-Bench, SWE-Bench, AppWorld), we inject complete task solutions into the agent environments to deliberately expose a task's solution to a model. While agents discover these solutions on Terminal-Bench in 79-81% of runs, they interact, or exploit, them in only 37-50% of cases. This gap is starkest in AppWorld: agents see documentation stating that a command "returns the complete solution to this task" in over 90% of attempts but exploit this in fewer than 7% of trials. We show that agents lack what we call environmental curiosity: the capability to recognize and investigate unexpected but relevant observations in response to environmental stimuli. We identify three main factors influencing environmental curiosity: available tools in the agent scaffold, test-time compute, and training data distribution. Our findings identify configurations that maximize curiosity also achieve the best performance on the unmodified benchmarks. Yet even jointly optimized agents still ignore discovered solutions in the majority of trials: current agents use the environment to fetch expected information, but not to revise their strategy or maximally exploit useful stimuli.
A Unified Framework for Rethinking Policy Divergence Measures in GRPO
Feb 05, 2026Reinforcement Learning with Verified Reward (RLVR) has emerged as a critical paradigm for advancing the reasoning capabilities of Large Language Models (LLMs). Most existing RLVR methods, such as GRPO and its variants, ensure stable updates by constraining policy divergence through clipping likelihood ratios. This paper introduces a unified clipping framework that characterizes existing methods via a general notion of policy divergence, encompassing both likelihood ratios and Kullback-Leibler (KL) divergences and extending to alternative measures. The framework provides a principled foundation for systematically analyzing how different policy divergence measures affect exploration and performance. We further identify the KL3 estimator, a variance-reduced Monte Carlo estimator of the KL divergence, as a key policy divergence constraint. We theoretically demonstrate that the KL3-based constraint is mathematically equivalent to an asymmetric ratio-based clipping that reallocates probability mass toward high-confidence actions, promoting stronger exploration while retaining the simplicity of GRPO-style methods. Empirical results on mathematical reasoning benchmarks demonstrate that incorporating the KL3 estimator into GRPO improves both training stability and final performance, highlighting the importance of principled policy divergence constraints in policy optimization.
The Multilingual Divide and Its Impact on Global AI Safety
May 27, 2025Despite advances in large language model capabilities in recent years, a large gap remains in their capabilities and safety performance for many languages beyond a relatively small handful of globally dominant languages. This paper provides researchers, policymakers and governance experts with an overview of key challenges to bridging the "language gap" in AI and minimizing safety risks across languages. We provide an analysis of why the language gap in AI exists and grows, and how it creates disparities in global AI safety. We identify barriers to address these challenges, and recommend how those working in policy and governance can help address safety concerns associated with the language gap by supporting multilingual dataset creation, transparency, and research.
Aya Vision: Advancing the Frontier of Multilingual Multimodality
May 13, 2025Building multimodal language models is fundamentally challenging: it requires aligning vision and language modalities, curating high-quality instruction data, and avoiding the degradation of existing text-only capabilities once vision is introduced. These difficulties are further magnified in the multilingual setting, where the need for multimodal data in different languages exacerbates existing data scarcity, machine translation often distorts meaning, and catastrophic forgetting is more pronounced. To address the aforementioned challenges, we introduce novel techniques spanning both data and modeling. First, we develop a synthetic annotation framework that curates high-quality, diverse multilingual multimodal instruction data, enabling Aya Vision models to produce natural, human-preferred responses to multimodal inputs across many languages. Complementing this, we propose a cross-modal model merging technique that mitigates catastrophic forgetting, effectively preserving text-only capabilities while simultaneously enhancing multimodal generative performance. Aya-Vision-8B achieves best-in-class performance compared to strong multimodal models such as Qwen-2.5-VL-7B, Pixtral-12B, and even much larger Llama-3.2-90B-Vision. We further scale this approach with Aya-Vision-32B, which outperforms models more than twice its size, such as Molmo-72B and LLaMA-3.2-90B-Vision. Our work advances multilingual progress on the multi-modal frontier, and provides insights into techniques that effectively bend the need for compute while delivering extremely high performance.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
If You Can't Use Them, Recycle Them: Optimizing Merging at Scale Mitigates Performance Tradeoffs
Dec 05, 2024
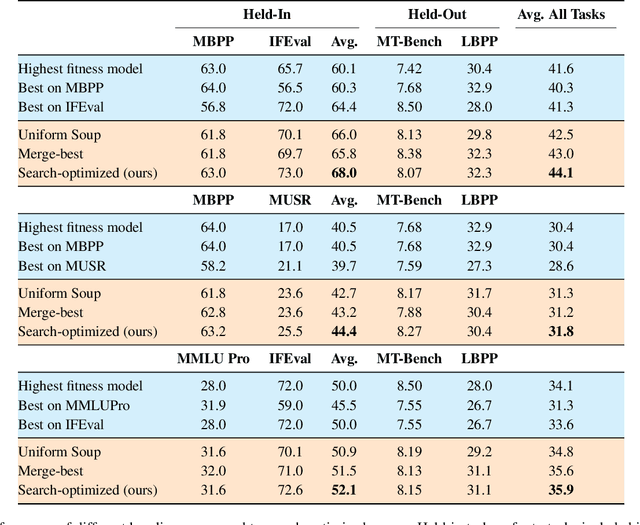
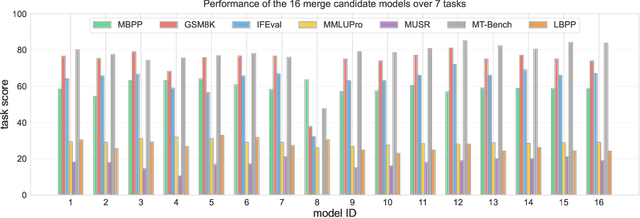
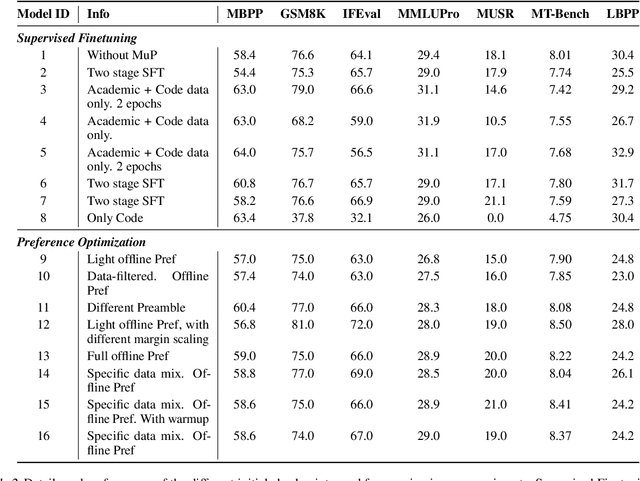
Model merging has shown great promise at combining expert models, but the benefit of merging is unclear when merging ``generalist'' models trained on many tasks. We explore merging in the context of large ($\sim100$B) models, by \textit{recycling} checkpoints that exhibit tradeoffs among different tasks. Such checkpoints are often created in the process of developing a frontier model, and many suboptimal ones are usually discarded. Given a pool of model checkpoints obtained from different training runs (e.g., different stages, objectives, hyperparameters, and data mixtures), which naturally show tradeoffs across different language capabilities (e.g., instruction following vs. code generation), we investigate whether merging can recycle such suboptimal models into a Pareto-optimal one. Our optimization algorithm tunes the weight of each checkpoint in a linear combination, resulting in a Pareto-optimal models that outperforms both individual models and merge-based baselines. Further analysis shows that good merges tend to include almost all checkpoints with with non-zero weights, indicating that even seemingly bad initial checkpoints can contribute to good final merges.
Commit0: Library Generation from Scratch
Dec 02, 2024With the goal of benchmarking generative systems beyond expert software development ability, we introduce Commit0, a benchmark that challenges AI agents to write libraries from scratch. Agents are provided with a specification document outlining the library's API as well as a suite of interactive unit tests, with the goal of producing an implementation of this API accordingly. The implementation is validated through running these unit tests. As a benchmark, Commit0 is designed to move beyond static one-shot code generation towards agents that must process long-form natural language specifications, adapt to multi-stage feedback, and generate code with complex dependencies. Commit0 also offers an interactive environment where models receive static analysis and execution feedback on the code they generate. Our experiments demonstrate that while current agents can pass some unit tests, none can yet fully reproduce full libraries. Results also show that interactive feedback is quite useful for models to generate code that passes more unit tests, validating the benchmarks that facilitate its use.
On Leakage of Code Generation Evaluation Datasets
Jul 11, 2024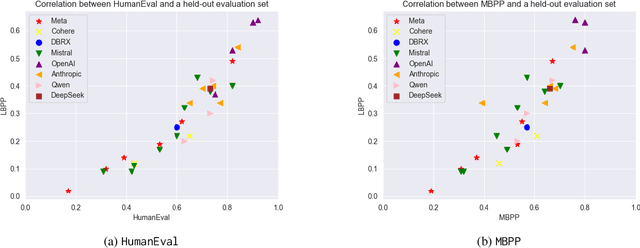
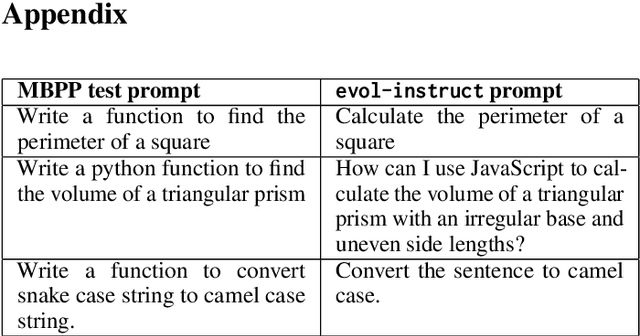
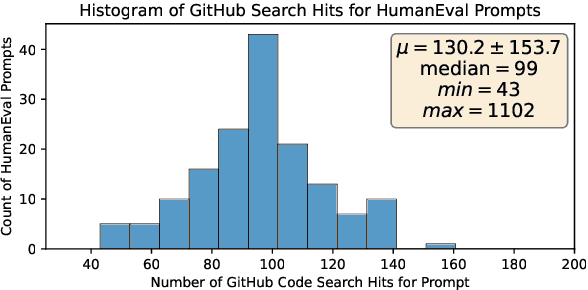
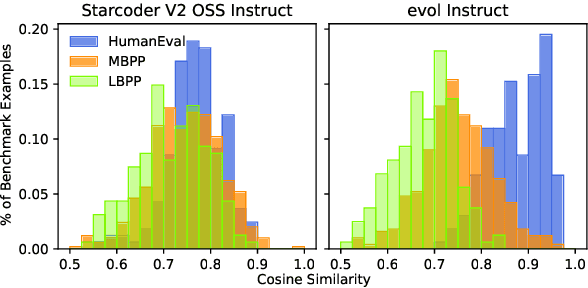
In this paper we consider contamination by code generation test sets, in particular in their use in modern large language models. We discuss three possible sources of such contamination and show findings supporting each of them: (i) direct data leakage, (ii) indirect data leakage through the use of synthetic data and (iii) overfitting to evaluation sets during model selection. Key to our findings is a new dataset of 161 prompts with their associated python solutions, dataset which is released at https://huggingface.co/datasets/CohereForAI/lbpp .
Improving Reward Models with Synthetic Critiques
May 31, 2024

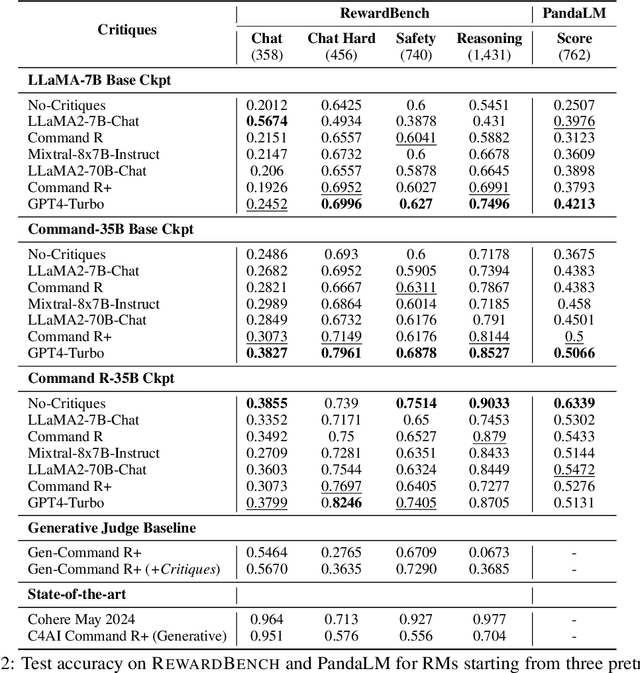
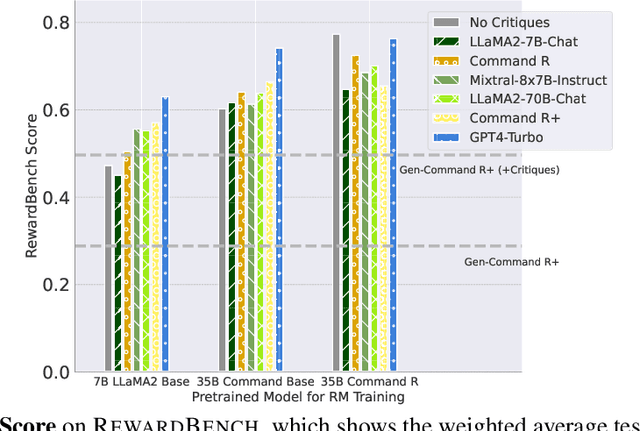
Reward models (RM) play a critical role in aligning language models through the process of reinforcement learning from human feedback. RMs are trained to predict a score reflecting human preference, which requires significant time and cost for human annotation. Additionally, RMs tend to quickly overfit on superficial features in the training set, hindering their generalization performance on unseen distributions. We propose a novel approach using synthetic natural language critiques generated by large language models to provide additional feedback, evaluating aspects such as instruction following, correctness, and style. This offers richer signals and more robust features for RMs to assess and score on. We demonstrate that high-quality critiques improve the performance and data efficiency of RMs initialized from different pretrained models. Conversely, we also show that low-quality critiques negatively impact performance. Furthermore, incorporating critiques enhances the interpretability and robustness of RM training.