 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
On Leakage of Code Generation Evaluation Datasets
Jul 11, 2024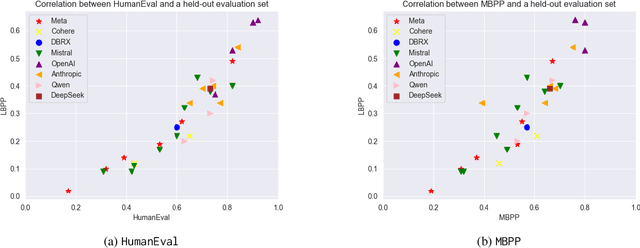
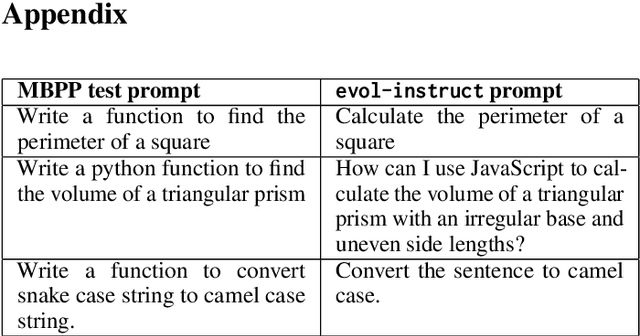
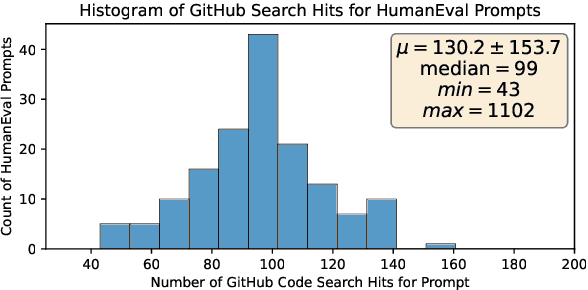
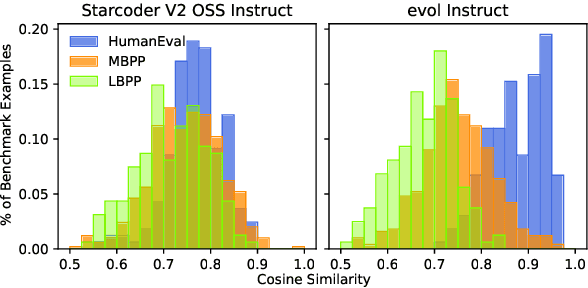
In this paper we consider contamination by code generation test sets, in particular in their use in modern large language models. We discuss three possible sources of such contamination and show findings supporting each of them: (i) direct data leakage, (ii) indirect data leakage through the use of synthetic data and (iii) overfitting to evaluation sets during model selection. Key to our findings is a new dataset of 161 prompts with their associated python solutions, dataset which is released at https://huggingface.co/datasets/CohereForAI/lbpp .
A Survey of Deep Learning Approaches for OCR and Document Understanding
Nov 27, 2020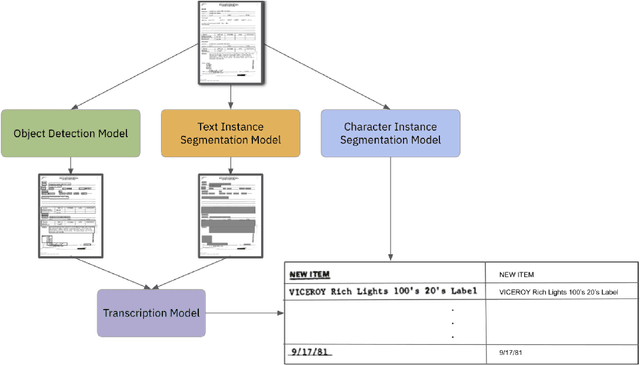
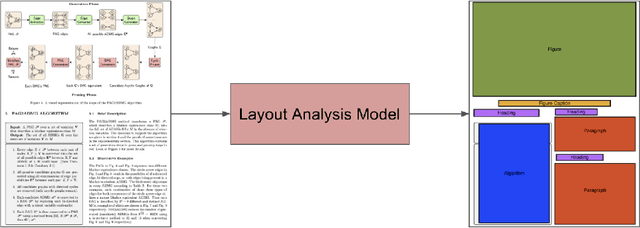
Documents are a core part of many businesses in many fields such as law, finance, and technology among others. Automatic understanding of documents such as invoices, contracts, and resumes is lucrative, opening up many new avenues of business. The fields of natural language processing and computer vision have seen tremendous progress through the development of deep learning such that these methods have started to become infused in contemporary document understanding systems. In this survey paper, we review different techniques for document understanding for documents written in English and consolidate methodologies present in literature to act as a jumping-off point for researchers exploring this area.
Emergent Properties of Finetuned Language Representation Models
Oct 23, 2019
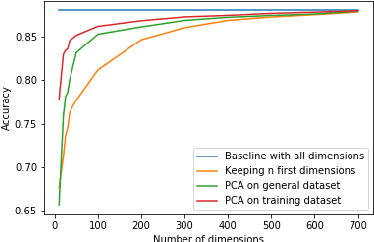
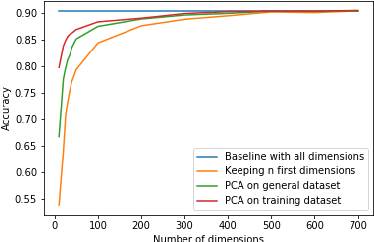
Large, self-supervised transformer-based language representation models have recently received significant amounts of attention, and have produced state-of-the-art results across a variety of tasks simply by scaling up pre-training on larger and larger corpora. Such models usually produce high dimensional vectors, on top of which additional task-specific layers and architectural modifications are added to adapt them to specific downstream tasks. Though there exists ample evidence that such models work well, we aim to understand what happens when they work well. We analyze the redundancy and location of information contained in output vectors for one such language representation model -- BERT. We show empirical evidence that the [CLS] embedding in BERT contains highly redundant information, and can be compressed with minimal loss of accuracy, especially for finetuned models, dovetailing into open threads in the field about the role of over-parameterization in learning. We also shed light on the existence of specific output dimensions which alone give very competitive results when compared to using all dimensions of output vectors.