 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
On Leakage of Code Generation Evaluation Datasets
Jul 11, 2024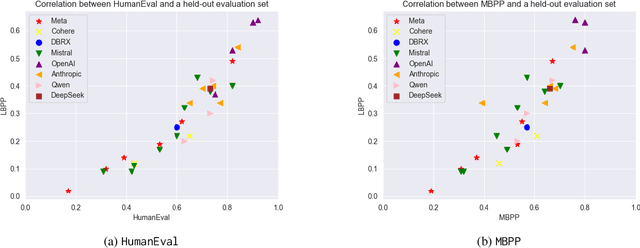
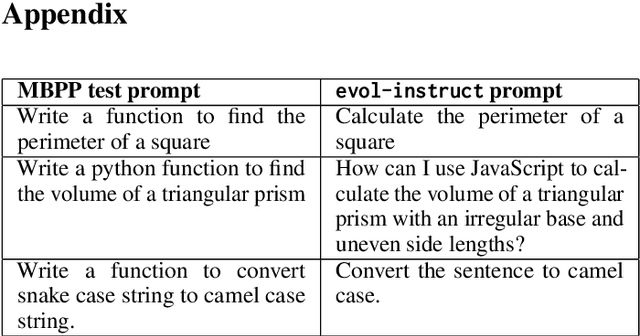
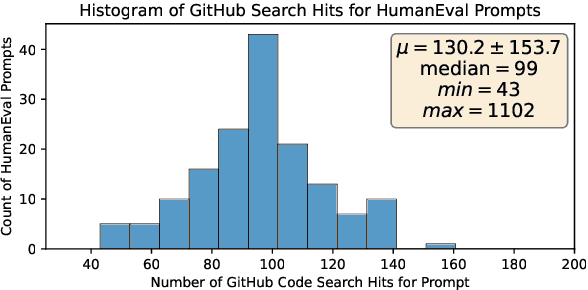
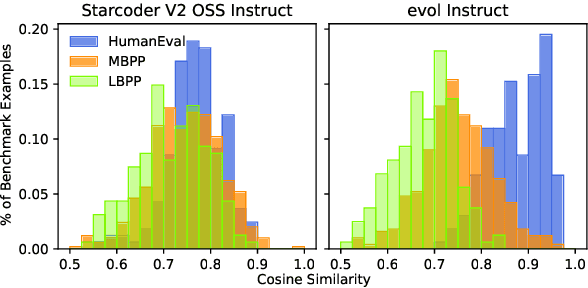
In this paper we consider contamination by code generation test sets, in particular in their use in modern large language models. We discuss three possible sources of such contamination and show findings supporting each of them: (i) direct data leakage, (ii) indirect data leakage through the use of synthetic data and (iii) overfitting to evaluation sets during model selection. Key to our findings is a new dataset of 161 prompts with their associated python solutions, dataset which is released at https://huggingface.co/datasets/CohereForAI/lbpp .
CAR-Net: Clairvoyant Attentive Recurrent Network
Jul 31, 2018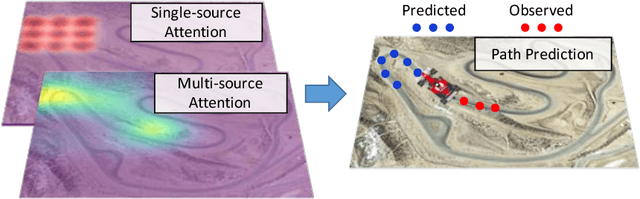

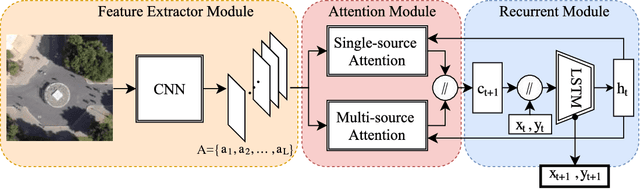
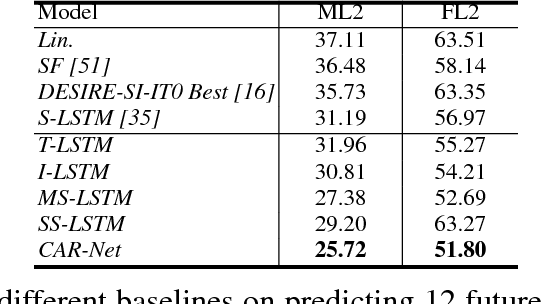
We present an interpretable framework for path prediction that leverages dependencies between agents' behaviors and their spatial navigation environment. We exploit two sources of information: the past motion trajectory of the agent of interest and a wide top-view image of the navigation scene. We propose a Clairvoyant Attentive Recurrent Network (CAR-Net) that learns where to look in a large image of the scene when solving the path prediction task. Our method can attend to any area, or combination of areas, within the raw image (e.g., road intersections) when predicting the trajectory of the agent. This allows us to visualize fine-grained semantic elements of navigation scenes that influence the prediction of trajectories. To study the impact of space on agents' trajectories, we build a new dataset made of top-view images of hundreds of scenes (Formula One racing tracks) where agents' behaviors are heavily influenced by known areas in the images (e.g., upcoming turns). CAR-Net successfully attends to these salient regions. Additionally, CAR-Net reaches state-of-the-art accuracy on the standard trajectory forecasting benchmark, Stanford Drone Dataset (SDD). Finally, we show CAR-Net's ability to generalize to unseen scenes.
* The 2nd and 3rd authors contributed equally
An Improved Training Procedure for Neural Autoregressive Data Completion
Nov 23, 2017
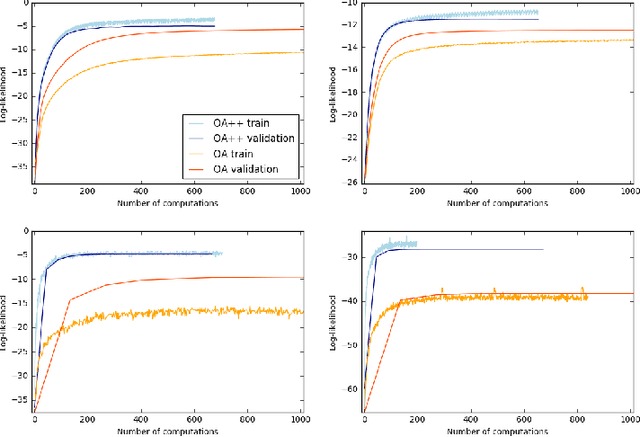
Neural autoregressive models are explicit density estimators that achieve state-of-the-art likelihoods for generative modeling. The D-dimensional data distribution is factorized into an autoregressive product of one-dimensional conditional distributions according to the chain rule. Data completion is a more involved task than data generation: the model must infer missing variables for any partially observed input vector. Previous work introduced an order-agnostic training procedure for data completion with autoregressive models. Missing variables in any partially observed input vector can be imputed efficiently by choosing an ordering where observed dimensions precede unobserved ones and by computing the autoregressive product in this order. In this paper, we provide evidence that the order-agnostic (OA) training procedure is suboptimal for data completion. We propose an alternative procedure (OA++) that reaches better performance in fewer computations. It can handle all data completion queries while training fewer one-dimensional conditional distributions than the OA procedure. In addition, these one-dimensional conditional distributions are trained proportionally to their expected usage at inference time, reducing overfitting. Finally, our OA++ procedure can exploit prior knowledge about the distribution of inference completion queries, as opposed to OA. We support these claims with quantitative experiments on standard datasets used to evaluate autoregressive generative models.
Dataiku's Solution to SPHERE's Activity Recognition Challenge
Oct 10, 2016
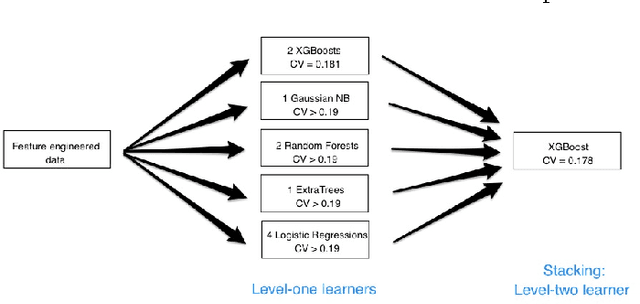
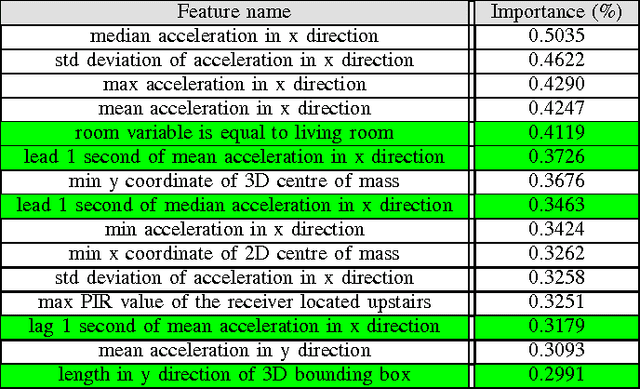
Our team won the second prize of the Safe Aging with SPHERE Challenge organized by SPHERE, in conjunction with ECML-PKDD and Driven Data. The goal of the competition was to recognize activities performed by humans, using sensor data. This paper presents our solution. It is based on a rich pre-processing and state of the art machine learning methods. From the raw train data, we generate a synthetic train set with the same statistical characteristics as the test set. We then perform feature engineering. The machine learning modeling part is based on stacking weak learners through a grid searched XGBoost algorithm. Finally, we use post-processing to smooth our predictions over time.