Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Leakage of Code Generation Evaluation Datasets
Paper and Code
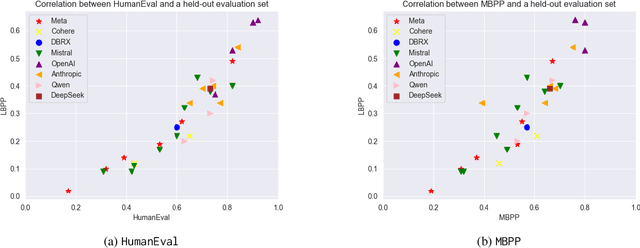
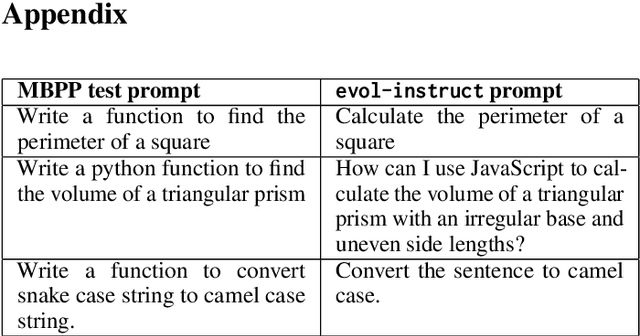
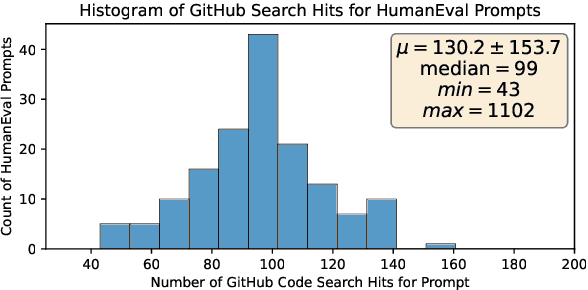
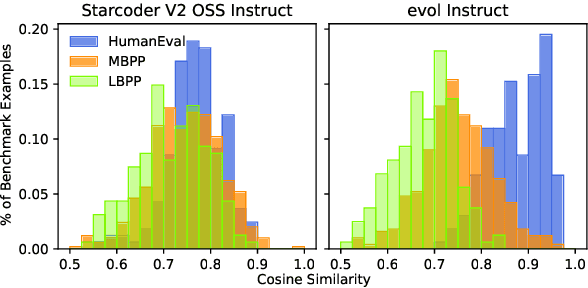
In this paper we consider contamination by code generation test sets, in particular in their use in modern large language models. We discuss three possible sources of such contamination and show findings supporting each of them: (i) direct data leakage, (ii) indirect data leakage through the use of synthetic data and (iii) overfitting to evaluation sets during model selection. Key to our findings is a new dataset of 161 prompts with their associated python solutions, dataset which is released at https://huggingface.co/datasets/CohereForAI/lbpp .
* 4 main pages, 9 in total
View paper on