 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Generalisation for Explainable Hate Speech Detection
Jun 04, 2025Hate speech detection is key to online content moderation, but current models struggle to generalise beyond their training data. This has been linked to dataset biases and the use of sentence-level labels, which fail to teach models the underlying structure of hate speech. In this work, we show that even when models are trained with more fine-grained, span-level annotations (e.g., "artists" is labeled as target and "are parasites" as dehumanising comparison), they struggle to disentangle the meaning of these labels from the surrounding context. As a result, combinations of expressions that deviate from those seen during training remain particularly difficult for models to detect. We investigate whether training on a dataset where expressions occur with equal frequency across all contexts can improve generalisation. To this end, we create U-PLEAD, a dataset of ~364,000 synthetic posts, along with a novel compositional generalisation benchmark of ~8,000 manually validated posts. Training on a combination of U-PLEAD and real data improves compositional generalisation while achieving state-of-the-art performance on the human-sourced PLEAD.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
If You Can't Use Them, Recycle Them: Optimizing Merging at Scale Mitigates Performance Tradeoffs
Dec 05, 2024
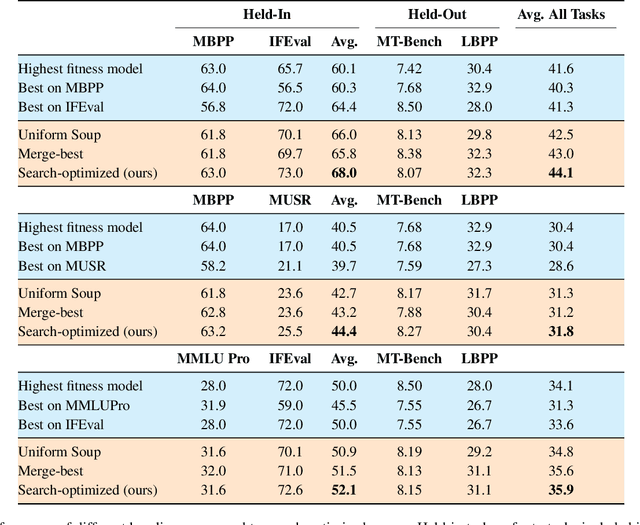
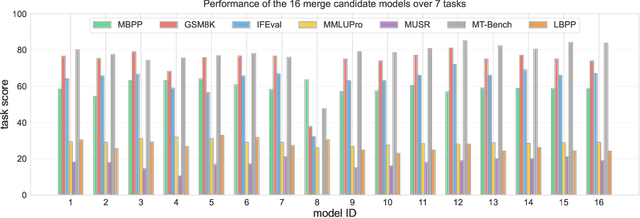
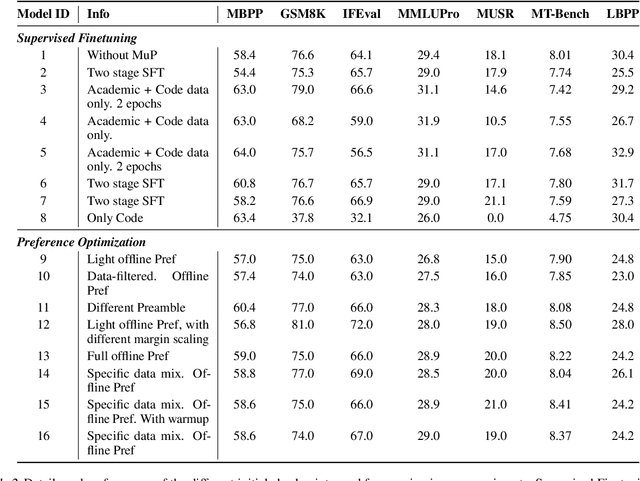
Model merging has shown great promise at combining expert models, but the benefit of merging is unclear when merging ``generalist'' models trained on many tasks. We explore merging in the context of large ($\sim100$B) models, by \textit{recycling} checkpoints that exhibit tradeoffs among different tasks. Such checkpoints are often created in the process of developing a frontier model, and many suboptimal ones are usually discarded. Given a pool of model checkpoints obtained from different training runs (e.g., different stages, objectives, hyperparameters, and data mixtures), which naturally show tradeoffs across different language capabilities (e.g., instruction following vs. code generation), we investigate whether merging can recycle such suboptimal models into a Pareto-optimal one. Our optimization algorithm tunes the weight of each checkpoint in a linear combination, resulting in a Pareto-optimal models that outperforms both individual models and merge-based baselines. Further analysis shows that good merges tend to include almost all checkpoints with with non-zero weights, indicating that even seemingly bad initial checkpoints can contribute to good final merges.
Scalable Data Ablation Approximations for Language Models through Modular Training and Merging
Oct 21, 2024


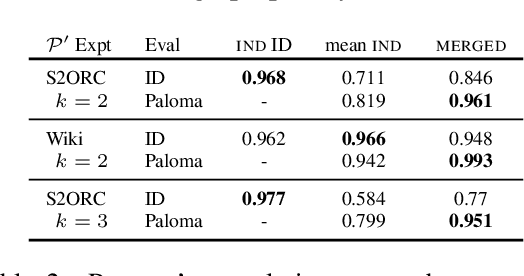
Training data compositions for Large Language Models (LLMs) can significantly affect their downstream performance. However, a thorough data ablation study exploring large sets of candidate data mixtures is typically prohibitively expensive since the full effect is seen only after training the models; this can lead practitioners to settle for sub-optimal data mixtures. We propose an efficient method for approximating data ablations which trains individual models on subsets of a training corpus and reuses them across evaluations of combinations of subsets. In continued pre-training experiments, we find that, given an arbitrary evaluation set, the perplexity score of a single model trained on a candidate set of data is strongly correlated with perplexity scores of parameter averages of models trained on distinct partitions of that data. From this finding, we posit that researchers and practitioners can conduct inexpensive simulations of data ablations by maintaining a pool of models that were each trained on partitions of a large training corpus, and assessing candidate data mixtures by evaluating parameter averages of combinations of these models. This approach allows for substantial improvements in amortized training efficiency -- scaling only linearly with respect to new data -- by enabling reuse of previous training computation, opening new avenues for improving model performance through rigorous, incremental data assessment and mixing.
On Leakage of Code Generation Evaluation Datasets
Jul 11, 2024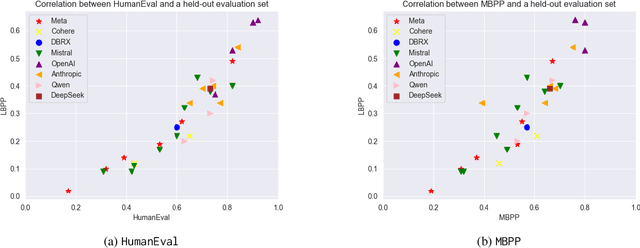
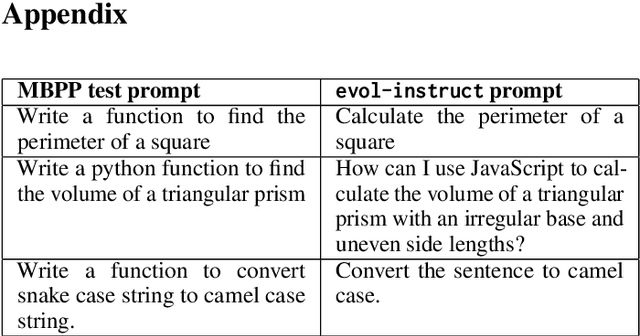
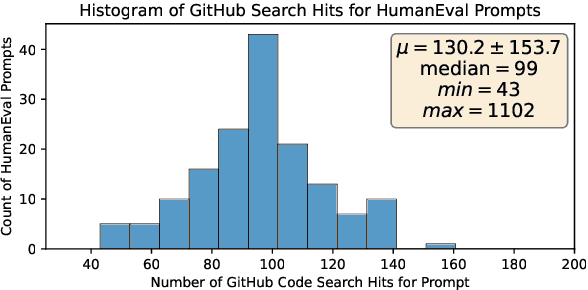
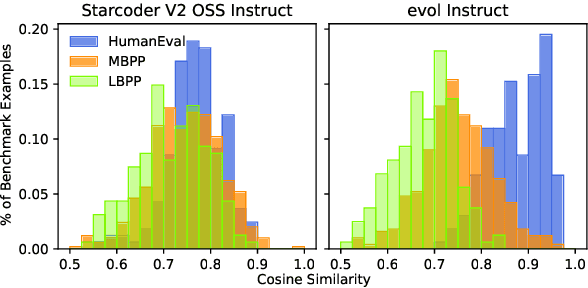
In this paper we consider contamination by code generation test sets, in particular in their use in modern large language models. We discuss three possible sources of such contamination and show findings supporting each of them: (i) direct data leakage, (ii) indirect data leakage through the use of synthetic data and (iii) overfitting to evaluation sets during model selection. Key to our findings is a new dataset of 161 prompts with their associated python solutions, dataset which is released at https://huggingface.co/datasets/CohereForAI/lbpp .
TRAM: Bridging Trust Regions and Sharpness Aware Minimization
Oct 05, 2023
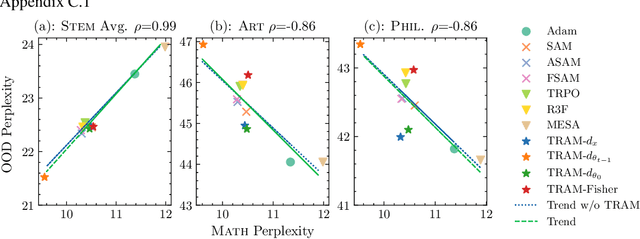

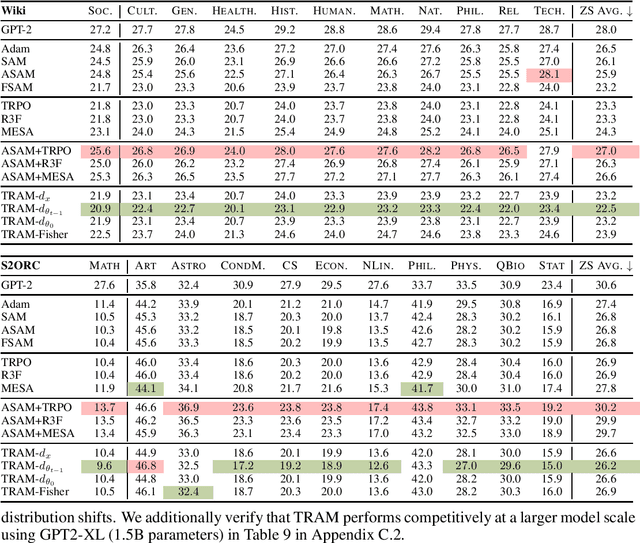
By reducing the curvature of the loss surface in the parameter space, Sharpness-aware minimization (SAM) yields widespread robustness improvement under domain transfer. Instead of focusing on parameters, however, this work considers the transferability of representations as the optimization target for out-of-domain generalization in a fine-tuning setup. To encourage the retention of transferable representations, we consider trust region-based fine-tuning methods, which exploit task-specific skills without forgetting task-agnostic representations from pre-training. We unify parameter- and representation-space smoothing approaches by using trust region bounds to inform SAM-style regularizers on both of these optimization surfaces. We propose Trust Region Aware Minimization (TRAM), a fine-tuning algorithm that optimizes for flat minima and smooth, informative representations without forgetting pre-trained structure. We find that TRAM outperforms both sharpness-aware and trust region-based optimization methods on cross-domain language modeling and cross-lingual transfer, where robustness to domain transfer and representation generality are critical for success. TRAM establishes a new standard in training generalizable models with minimal additional computation.
Efficiency Pentathlon: A Standardized Arena for Efficiency Evaluation
Jul 19, 2023Rising computational demands of modern natural language processing (NLP) systems have increased the barrier to entry for cutting-edge research while posing serious environmental concerns. Yet, progress on model efficiency has been impeded by practical challenges in model evaluation and comparison. For example, hardware is challenging to control due to disparate levels of accessibility across different institutions. Moreover, improvements in metrics such as FLOPs often fail to translate to progress in real-world applications. In response, we introduce Pentathlon, a benchmark for holistic and realistic evaluation of model efficiency. Pentathlon focuses on inference, which accounts for a majority of the compute in a model's lifecycle. It offers a strictly-controlled hardware platform, and is designed to mirror real-world applications scenarios. It incorporates a suite of metrics that target different aspects of efficiency, including latency, throughput, memory overhead, and energy consumption. Pentathlon also comes with a software library that can be seamlessly integrated into any codebase and enable evaluation. As a standardized and centralized evaluation platform, Pentathlon can drastically reduce the workload to make fair and reproducible efficiency comparisons. While initially focused on natural language processing (NLP) models, Pentathlon is designed to allow flexible extension to other fields. We envision Pentathlon will stimulate algorithmic innovations in building efficient models, and foster an increased awareness of the social and environmental implications in the development of future-generation NLP models.
Optimal Transport Posterior Alignment for Cross-lingual Semantic Parsing
Jul 09, 2023Cross-lingual semantic parsing transfers parsing capability from a high-resource language (e.g., English) to low-resource languages with scarce training data. Previous work has primarily considered silver-standard data augmentation or zero-shot methods, however, exploiting few-shot gold data is comparatively unexplored. We propose a new approach to cross-lingual semantic parsing by explicitly minimizing cross-lingual divergence between probabilistic latent variables using Optimal Transport. We demonstrate how this direct guidance improves parsing from natural languages using fewer examples and less training. We evaluate our method on two datasets, MTOP and MultiATIS++SQL, establishing state-of-the-art results under a few-shot cross-lingual regime. Ablation studies further reveal that our method improves performance even without parallel input translations. In addition, we show that our model better captures cross-lingual structure in the latent space to improve semantic representation similarity.
Extrinsic Evaluation of Machine Translation Metrics
Dec 20, 2022



Automatic machine translation (MT) metrics are widely used to distinguish the translation qualities of machine translation systems across relatively large test sets (system-level evaluation). However, it is unclear if automatic metrics are reliable at distinguishing good translations from bad translations at the sentence level (segment-level evaluation). In this paper, we investigate how useful MT metrics are at detecting the success of a machine translation component when placed in a larger platform with a downstream task. We evaluate the segment-level performance of the most widely used MT metrics (chrF, COMET, BERTScore, etc.) on three downstream cross-lingual tasks (dialogue state tracking, question answering, and semantic parsing). For each task, we only have access to a monolingual task-specific model. We calculate the correlation between the metric's ability to predict a good/bad translation with the success/failure on the final task for the Translate-Test setup. Our experiments demonstrate that all metrics exhibit negligible correlation with the extrinsic evaluation of the downstream outcomes. We also find that the scores provided by neural metrics are not interpretable mostly because of undefined ranges. Our analysis suggests that future MT metrics be designed to produce error labels rather than scores to facilitate extrinsic evaluation.
Meta-Learning a Cross-lingual Manifold for Semantic Parsing
Sep 27, 2022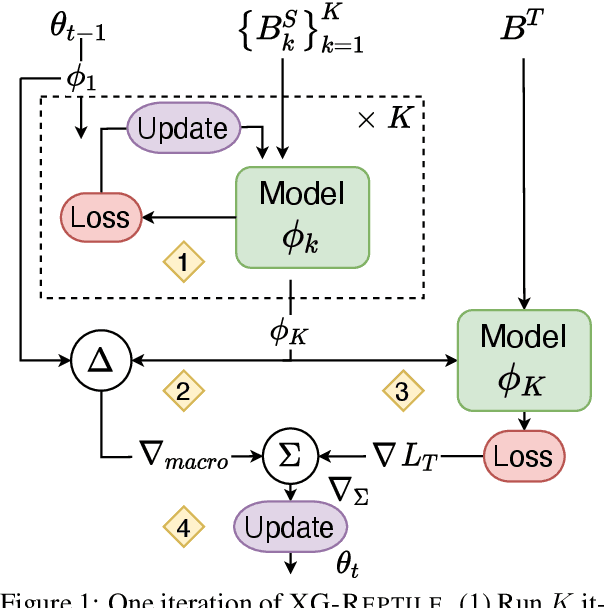


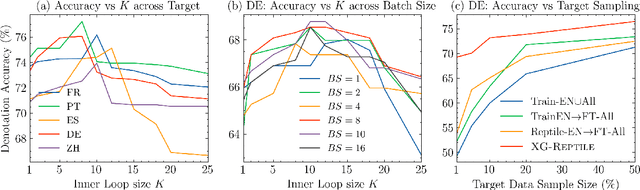
Localizing a semantic parser to support new languages requires effective cross-lingual generalization. Recent work has found success with machine-translation or zero-shot methods although these approaches can struggle to model how native speakers ask questions. We consider how to effectively leverage minimal annotated examples in new languages for few-shot cross-lingual semantic parsing. We introduce a first-order meta-learning algorithm to train a semantic parser with maximal sample efficiency during cross-lingual transfer. Our algorithm uses high-resource languages to train the parser and simultaneously optimizes for cross-lingual generalization for lower-resource languages. Results across six languages on ATIS demonstrate that our combination of generalization steps yields accurate semantic parsers sampling $\le$10% of source training data in each new language. Our approach also trains a competitive model on Spider using English with generalization to Chinese similarly sampling $\le$10% of training data.