 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Generalisation for Explainable Hate Speech Detection
Jun 04, 2025Hate speech detection is key to online content moderation, but current models struggle to generalise beyond their training data. This has been linked to dataset biases and the use of sentence-level labels, which fail to teach models the underlying structure of hate speech. In this work, we show that even when models are trained with more fine-grained, span-level annotations (e.g., "artists" is labeled as target and "are parasites" as dehumanising comparison), they struggle to disentangle the meaning of these labels from the surrounding context. As a result, combinations of expressions that deviate from those seen during training remain particularly difficult for models to detect. We investigate whether training on a dataset where expressions occur with equal frequency across all contexts can improve generalisation. To this end, we create U-PLEAD, a dataset of ~364,000 synthetic posts, along with a novel compositional generalisation benchmark of ~8,000 manually validated posts. Training on a combination of U-PLEAD and real data improves compositional generalisation while achieving state-of-the-art performance on the human-sourced PLEAD.
The Only Way is Ethics: A Guide to Ethical Research with Large Language Models
Dec 20, 2024
There is a significant body of work looking at the ethical considerations of large language models (LLMs): critiquing tools to measure performance and harms; proposing toolkits to aid in ideation; discussing the risks to workers; considering legislation around privacy and security etc. As yet there is no work that integrates these resources into a single practical guide that focuses on LLMs; we attempt this ambitious goal. We introduce 'LLM Ethics Whitepaper', which we provide as an open and living resource for NLP practitioners, and those tasked with evaluating the ethical implications of others' work. Our goal is to translate ethics literature into concrete recommendations and provocations for thinking with clear first steps, aimed at computer scientists. 'LLM Ethics Whitepaper' distils a thorough literature review into clear Do's and Don'ts, which we present also in this paper. We likewise identify useful toolkits to support ethical work. We refer the interested reader to the full LLM Ethics Whitepaper, which provides a succinct discussion of ethical considerations at each stage in a project lifecycle, as well as citations for the hundreds of papers from which we drew our recommendations. The present paper can be thought of as a pocket guide to conducting ethical research with LLMs.
Explainability and Hate Speech: Structured Explanations Make Social Media Moderators Faster
Jun 06, 2024

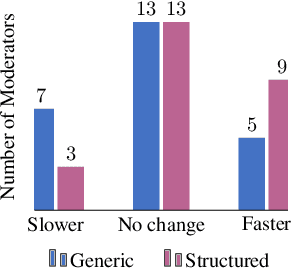
Content moderators play a key role in keeping the conversation on social media healthy. While the high volume of content they need to judge represents a bottleneck to the moderation pipeline, no studies have explored how models could support them to make faster decisions. There is, by now, a vast body of research into detecting hate speech, sometimes explicitly motivated by a desire to help improve content moderation, but published research using real content moderators is scarce. In this work we investigate the effect of explanations on the speed of real-world moderators. Our experiments show that while generic explanations do not affect their speed and are often ignored, structured explanations lower moderators' decision making time by 7.4%.
Detecting Statements in Text: A Domain-Agnostic Few-Shot Solution
May 09, 2024Many tasks related to Computational Social Science and Web Content Analysis involve classifying pieces of text based on the claims they contain. State-of-the-art approaches usually involve fine-tuning models on large annotated datasets, which are costly to produce. In light of this, we propose and release a qualitative and versatile few-shot learning methodology as a common paradigm for any claim-based textual classification task. This methodology involves defining the classes as arbitrarily sophisticated taxonomies of claims, and using Natural Language Inference models to obtain the textual entailment between these and a corpus of interest. The performance of these models is then boosted by annotating a minimal sample of data points, dynamically sampled using the well-established statistical heuristic of Probabilistic Bisection. We illustrate this methodology in the context of three tasks: climate change contrarianism detection, topic/stance classification and depression-relates symptoms detection. This approach rivals traditional pre-train/fine-tune approaches while drastically reducing the need for data annotation.
Stereotypes and Smut: The (Mis)representation of Non-cisgender Identities by Text-to-Image Models
May 26, 2023



Cutting-edge image generation has been praised for producing high-quality images, suggesting a ubiquitous future in a variety of applications. However, initial studies have pointed to the potential for harm due to predictive bias, reflecting and potentially reinforcing cultural stereotypes. In this work, we are the first to investigate how multimodal models handle diverse gender identities. Concretely, we conduct a thorough analysis in which we compare the output of three image generation models for prompts containing cisgender vs. non-cisgender identity terms. Our findings demonstrate that certain non-cisgender identities are consistently (mis)represented as less human, more stereotyped and more sexualised. We complement our experimental analysis with (a)~a survey among non-cisgender individuals and (b) a series of interviews, to establish which harms affected individuals anticipate, and how they would like to be represented. We find respondents are particularly concerned about misrepresentation, and the potential to drive harmful behaviours and beliefs. Simple heuristics to limit offensive content are widely rejected, and instead respondents call for community involvement, curated training data and the ability to customise. These improvements could pave the way for a future where change is led by the affected community, and technology is used to positively ``[portray] queerness in ways that we haven't even thought of'' rather than reproducing stale, offensive stereotypes.
Cross-lingual Transfer Can Worsen Bias in Sentiment Analysis
May 22, 2023Sentiment analysis (SA) systems are widely deployed in many of the world's languages, and there is well-documented evidence of demographic bias in these systems. In languages beyond English, scarcer training data is often supplemented with transfer learning using pre-trained models, including multilingual models trained on other languages. In some cases, even supervision data comes from other languages. Does cross-lingual transfer also import new biases? To answer this question, we use counterfactual evaluation to test whether gender or racial biases are imported when using cross-lingual transfer, compared to a monolingual transfer setting. Across five languages, we find that systems using cross-lingual transfer usually become more biased than their monolingual counterparts. We also find racial biases to be much more prevalent than gender biases. To spur further research on this topic, we release the sentiment models we used for this study, and the intermediate checkpoints throughout training, yielding 1,525 distinct models; we also release our evaluation code.
A Robust Bias Mitigation Procedure Based on the Stereotype Content Model
Oct 26, 2022


The Stereotype Content model (SCM) states that we tend to perceive minority groups as cold, incompetent or both. In this paper we adapt existing work to demonstrate that the Stereotype Content model holds for contextualised word embeddings, then use these results to evaluate a fine-tuning process designed to drive a language model away from stereotyped portrayals of minority groups. We find the SCM terms are better able to capture bias than demographic agnostic terms related to pleasantness. Further, we were able to reduce the presence of stereotypes in the model through a simple fine-tuning procedure that required minimal human and computer resources, without harming downstream performance. We present this work as a prototype of a debiasing procedure that aims to remove the need for a priori knowledge of the specifics of bias in the model.
Explainable Abuse Detection as Intent Classification and Slot Filling
Oct 06, 2022

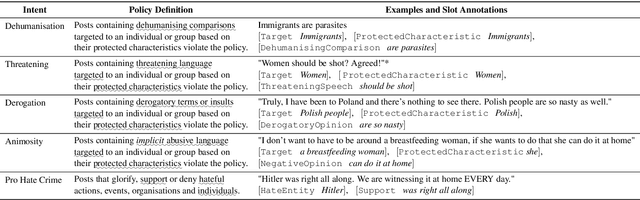
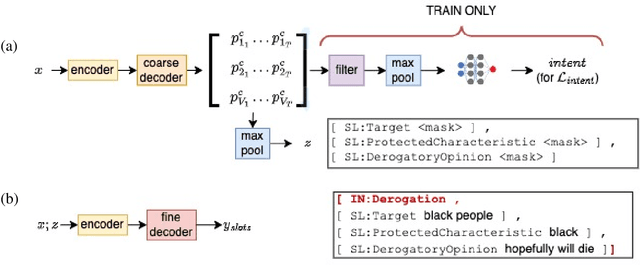
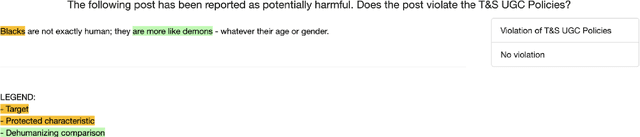
To proactively offer social media users a safe online experience, there is a need for systems that can detect harmful posts and promptly alert platform moderators. In order to guarantee the enforcement of a consistent policy, moderators are provided with detailed guidelines. In contrast, most state-of-the-art models learn what abuse is from labelled examples and as a result base their predictions on spurious cues, such as the presence of group identifiers, which can be unreliable. In this work we introduce the concept of policy-aware abuse detection, abandoning the unrealistic expectation that systems can reliably learn which phenomena constitute abuse from inspecting the data alone. We propose a machine-friendly representation of the policy that moderators wish to enforce, by breaking it down into a collection of intents and slots. We collect and annotate a dataset of 3,535 English posts with such slots, and show how architectures for intent classification and slot filling can be used for abuse detection, while providing a rationale for model decisions.
Towards Successful Collaboration: Design Guidelines for AI-based Services enriching Information Systems in Organisations
Dec 02, 2019Information systems (IS) are widely used in organisations to improve business performance. The steady progression in improving technologies like artificial intelligence (AI) and the need of securing future success of organisations lead to new requirements for IS. This research in progress firstly introduces the term AI-based services (AIBS) describing AI as a component enriching IS aiming at collaborating with employees and assisting in the execution of work-related tasks. The study derives requirements from ten expert interviews to successful design AIBS following Design Science Research (DSR). For a successful deployment of AIBS in organisations the D&M IS Success Model will be considered to validated requirements within three major dimensions of quality: Information Quality, System Quality, and Service Quality. Amongst others, preliminary findings propose that AIBS must be preferably authentic. Further discussion and research on AIBS is forced, thus, providing first insights on the deployment of AIBS in organisations.
Measuring the Reliability of Hate Speech Annotations: The Case of the European Refugee Crisis
Jan 27, 2017
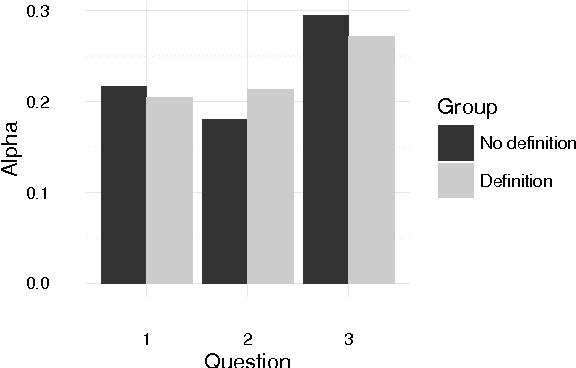
Some users of social media are spreading racist, sexist, and otherwise hateful content. For the purpose of training a hate speech detection system, the reliability of the annotations is crucial, but there is no universally agreed-upon definition. We collected potentially hateful messages and asked two groups of internet users to determine whether they were hate speech or not, whether they should be banned or not and to rate their degree of offensiveness. One of the groups was shown a definition prior to completing the survey. We aimed to assess whether hate speech can be annotated reliably, and the extent to which existing definitions are in accordance with subjective ratings. Our results indicate that showing users a definition caused them to partially align their own opinion with the definition but did not improve reliability, which was very low overall. We conclude that the presence of hate speech should perhaps not be considered a binary yes-or-no decision, and raters need more detailed instructions for the annotation.