 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Generate Harmful Content Using a Distinct, Unified Mechanism
Apr 10, 2026Large language models (LLMs) undergo alignment training to avoid harmful behaviors, yet the resulting safeguards remain brittle: jailbreaks routinely bypass them, and fine-tuning on narrow domains can induce ``emergent misalignment'' that generalizes broadly. Whether this brittleness reflects a fundamental lack of coherent internal organization for harmfulness remains unclear. Here we use targeted weight pruning as a causal intervention to probe the internal organization of harmfulness in LLMs. We find that harmful content generation depends on a compact set of weights that are general across harm types and distinct from benign capabilities. Aligned models exhibit a greater compression of harm generation weights than unaligned counterparts, indicating that alignment reshapes harmful representations internally--despite the brittleness of safety guardrails at the surface level. This compression explains emergent misalignment: if weights of harmful capabilities are compressed, fine-tuning that engages these weights in one domain can trigger broad misalignment. Consistent with this, pruning harm generation weights in a narrow domain substantially reduces emergent misalignment. Notably, LLMs harmful generation capability is dissociated from how they recognize and explain such content. Together, these results reveal a coherent internal structure for harmfulness in LLMs that may serve as a foundation for more principled approaches to safety.
Learning is Forgetting: LLM Training As Lossy Compression
Apr 08, 2026Despite the increasing prevalence of large language models (LLMs), we still have a limited understanding of how their representational spaces are structured. This limits our ability to interpret how and what they learn or relate them to learning in humans. We argue LLMs are best seen as an instance of lossy compression, where over training they learn by retaining only information in their training data relevant to their objective(s). We show pre-training results in models that are optimally compressed for next-sequence prediction, approaching the Information Bottleneck bound on compression. Across an array of open weights models, each compresses differently, likely due to differences in the data and training recipes used. However even across different families of LLMs the optimality of a model's compression, and the information present in it, can predict downstream performance on across a wide array of benchmarks, letting us directly link representational structure to actionable insights about model performance. In the general case the work presented here offers a unified Information-Theoretic framing for how these models learn that is deployable at scale.
Lost in Simulation: LLM-Simulated Users are Unreliable Proxies for Human Users in Agentic Evaluations
Jan 23, 2026Agentic benchmarks increasingly rely on LLM-simulated users to scalably evaluate agent performance, yet the robustness, validity, and fairness of this approach remain unexamined. Through a user study with participants across the United States, India, Kenya, and Nigeria, we investigate whether LLM-simulated users serve as reliable proxies for real human users in evaluating agents on τ-Bench retail tasks. We find that user simulation lacks robustness, with agent success rates varying up to 9 percentage points across different user LLMs. Furthermore, evaluations using simulated users exhibit systematic miscalibration, underestimating agent performance on challenging tasks and overestimating it on moderately difficult ones. African American Vernacular English (AAVE) speakers experience consistently worse success rates and calibration errors than Standard American English (SAE) speakers, with disparities compounding significantly with age. We also find simulated users to be a differentially effective proxy for different populations, performing worst for AAVE and Indian English speakers. Additionally, simulated users introduce conversational artifacts and surface different failure patterns than human users. These findings demonstrate that current evaluation practices risk misrepresenting agent capabilities across diverse user populations and may obscure real-world deployment challenges.
The Multilingual Divide and Its Impact on Global AI Safety
May 27, 2025Despite advances in large language model capabilities in recent years, a large gap remains in their capabilities and safety performance for many languages beyond a relatively small handful of globally dominant languages. This paper provides researchers, policymakers and governance experts with an overview of key challenges to bridging the "language gap" in AI and minimizing safety risks across languages. We provide an analysis of why the language gap in AI exists and grows, and how it creates disparities in global AI safety. We identify barriers to address these challenges, and recommend how those working in policy and governance can help address safety concerns associated with the language gap by supporting multilingual dataset creation, transparency, and research.
MAPS: A Multilingual Benchmark for Global Agent Performance and Security
May 21, 2025Agentic AI systems, which build on Large Language Models (LLMs) and interact with tools and memory, have rapidly advanced in capability and scope. Yet, since LLMs have been shown to struggle in multilingual settings, typically resulting in lower performance and reduced safety, agentic systems risk inheriting these limitations. This raises concerns about the global accessibility of such systems, as users interacting in languages other than English may encounter unreliable or security-critical agent behavior. Despite growing interest in evaluating agentic AI, existing benchmarks focus exclusively on English, leaving multilingual settings unexplored. To address this gap, we propose MAPS, a multilingual benchmark suite designed to evaluate agentic AI systems across diverse languages and tasks. MAPS builds on four widely used agentic benchmarks - GAIA (real-world tasks), SWE-bench (code generation), MATH (mathematical reasoning), and the Agent Security Benchmark (security). We translate each dataset into ten diverse languages, resulting in 805 unique tasks and 8,855 total language-specific instances. Our benchmark suite enables a systematic analysis of how multilingual contexts affect agent performance and robustness. Empirically, we observe consistent degradation in both performance and security when transitioning from English to other languages, with severity varying by task and correlating with the amount of translated input. Building on these findings, we provide actionable recommendations to guide agentic AI systems development and assessment under multilingual settings. This work establishes a standardized evaluation framework, encouraging future research towards equitable, reliable, and globally accessible agentic AI. MAPS benchmark suite is publicly available at https://huggingface.co/datasets/Fujitsu-FRE/MAPS
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Safer or Luckier? LLMs as Safety Evaluators Are Not Robust to Artifacts
Mar 12, 2025



Large Language Models (LLMs) are increasingly employed as automated evaluators to assess the safety of generated content, yet their reliability in this role remains uncertain. This study evaluates a diverse set of 11 LLM judge models across critical safety domains, examining three key aspects: self-consistency in repeated judging tasks, alignment with human judgments, and susceptibility to input artifacts such as apologetic or verbose phrasing. Our findings reveal that biases in LLM judges can significantly distort the final verdict on which content source is safer, undermining the validity of comparative evaluations. Notably, apologetic language artifacts alone can skew evaluator preferences by up to 98\%. Contrary to expectations, larger models do not consistently exhibit greater robustness, while smaller models sometimes show higher resistance to specific artifacts. To mitigate LLM evaluator robustness issues, we investigate jury-based evaluations aggregating decisions from multiple models. Although this approach both improves robustness and enhances alignment to human judgements, artifact sensitivity persists even with the best jury configurations. These results highlight the urgent need for diversified, artifact-resistant methodologies to ensure reliable safety assessments.
Who Does the Giant Number Pile Like Best: Analyzing Fairness in Hiring Contexts
Jan 08, 2025

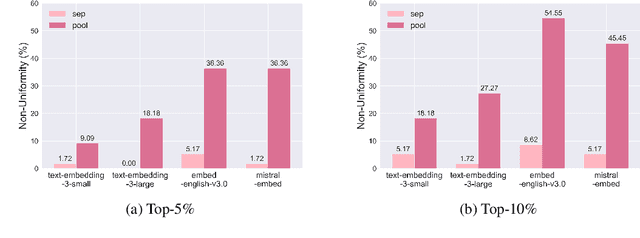
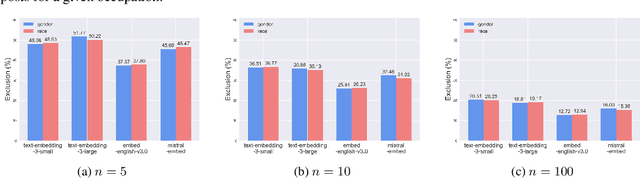
Large language models (LLMs) are increasingly being deployed in high-stakes applications like hiring, yet their potential for unfair decision-making and outcomes remains understudied, particularly in generative settings. In this work, we examine the fairness of LLM-based hiring systems through two real-world tasks: resume summarization and retrieval. By constructing a synthetic resume dataset and curating job postings, we investigate whether model behavior differs across demographic groups and is sensitive to demographic perturbations. Our findings reveal that race-based differences appear in approximately 10% of generated summaries, while gender-based differences occur in only 1%. In the retrieval setting, all evaluated models display non-uniform selection patterns across demographic groups and exhibit high sensitivity to both gender and race-based perturbations. Surprisingly, retrieval models demonstrate comparable sensitivity to non-demographic changes, suggesting that fairness issues may stem, in part, from general brittleness issues. Overall, our results indicate that LLM-based hiring systems, especially at the retrieval stage, can exhibit notable biases that lead to discriminatory outcomes in real-world contexts.
Mix Data or Merge Models? Optimizing for Diverse Multi-Task Learning
Oct 14, 2024



Large Language Models (LLMs) have been adopted and deployed worldwide for a broad variety of applications. However, ensuring their safe use remains a significant challenge. Preference training and safety measures often overfit to harms prevalent in Western-centric datasets, and safety protocols frequently fail to extend to multilingual settings. In this work, we explore model merging in a diverse multi-task setting, combining safety and general-purpose tasks within a multilingual context. Each language introduces unique and varied learning challenges across tasks. We find that objective-based merging is more effective than mixing data, with improvements of up to 8% and 10% in general performance and safety respectively. We also find that language-based merging is highly effective -- by merging monolingually fine-tuned models, we achieve a 4% increase in general performance and 7% reduction in harm across all languages on top of the data mixtures method using the same available data. Overall, our comprehensive study of merging approaches provides a useful framework for building strong and safe multilingual models.
The Multilingual Alignment Prism: Aligning Global and Local Preferences to Reduce Harm
Jun 26, 2024



A key concern with the concept of "alignment" is the implicit question of "alignment to what?". AI systems are increasingly used across the world, yet safety alignment is often focused on homogeneous monolingual settings. Additionally, preference training and safety measures often overfit to harms common in Western-centric datasets. Here, we explore the viability of different alignment approaches when balancing dual objectives: addressing and optimizing for a non-homogeneous set of languages and cultural preferences while minimizing both global and local harms. We collect the first set of human annotated red-teaming prompts in different languages distinguishing between global and local harm, which serve as a laboratory for understanding the reliability of alignment techniques when faced with preference distributions that are non-stationary across geographies and languages. While this setting is seldom covered by the literature to date, which primarily centers on English harm mitigation, it captures real-world interactions with AI systems around the world. We establish a new precedent for state-of-the-art alignment techniques across 6 languages with minimal degradation in general performance. Our work provides important insights into cross-lingual transfer and novel optimization approaches to safeguard AI systems designed to serve global populations.