 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
FLARE: Faithful Logic-Aided Reasoning and Exploration
Oct 14, 2024
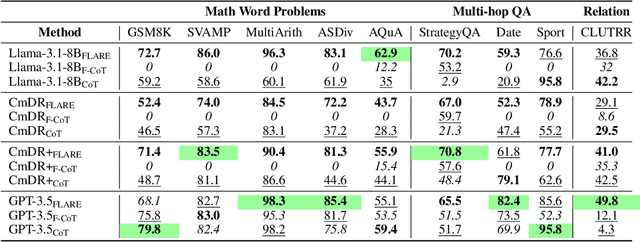
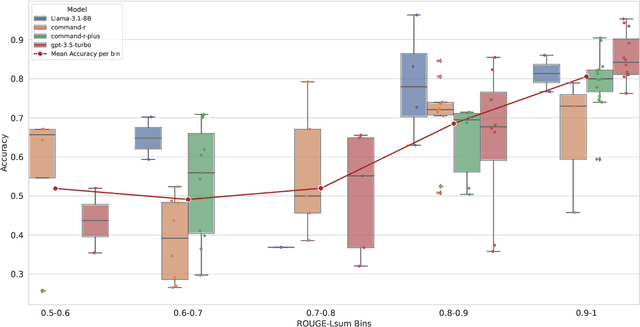

Modern Question Answering (QA) and Reasoning approaches based on Large Language Models (LLMs) commonly use prompting techniques, such as Chain-of-Thought (CoT), assuming the resulting generation will have a more granular exploration and reasoning over the question space and scope. However, such methods struggle with generating outputs that are faithful to the intermediate chain of reasoning produced by the model. On the other end of the spectrum, neuro-symbolic methods such as Faithful CoT (F-CoT) propose to combine LLMs with external symbolic solvers. While such approaches boast a high degree of faithfulness, they usually require a model trained for code generation and struggle with tasks that are ambiguous or hard to formalise strictly. We introduce \textbf{F}aithful \textbf{L}ogic-\textbf{A}ided \textbf{R}easoning and \textbf{E}xploration (\textbf{\ours}), a novel interpretable approach for traversing the problem space using task decompositions. We use the LLM to plan a solution, soft-formalise the query into facts and predicates using a logic programming code and simulate that code execution using an exhaustive multi-hop search over the defined space. Our method allows us to compute the faithfulness of the reasoning process w.r.t. the generated code and analyse the steps of the multi-hop search without relying on external solvers. Our methods achieve SOTA results on $\mathbf{7}$ out of $\mathbf{9}$ diverse reasoning benchmarks. We also show that model faithfulness positively correlates with overall performance and further demonstrate that {\textbf{\ours}} allows pinpointing the decisive factors sufficient for and leading to the correct answer with optimal reasoning during the multi-hop search.
ALR$^2$: A Retrieve-then-Reason Framework for Long-context Question Answering
Oct 04, 2024



The context window of large language models (LLMs) has been extended significantly in recent years. However, while the context length that the LLM can process has grown, the capability of the model to accurately reason over that context degrades noticeably. This occurs because modern LLMs often become overwhelmed by the vast amount of information in the context; when answering questions, the model must identify and reason over relevant evidence sparsely distributed throughout the text. To alleviate the challenge of long-context reasoning, we develop a retrieve-then-reason framework, enabling LLMs to reason over relevant evidence collected during an intermediate retrieval step. We find that modern LLMs struggle to accurately retrieve relevant facts and instead, often hallucinate "retrieved facts", resulting in flawed reasoning and the production of incorrect answers. To address these issues, we introduce ALR$^2$, a method that augments the long-context reasoning capability of LLMs via an explicit two-stage procedure, i.e., aligning LLMs with the objectives of both retrieval and reasoning. We demonstrate the efficacy of ALR$^2$ for mitigating performance degradation in long-context reasoning tasks. Through extensive experiments on long-context QA benchmarks, we find our method to outperform competitive baselines by large margins, achieving at least 8.4 and 7.9 EM gains on the long-context versions of HotpotQA and SQuAD datasets, respectively.
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
May 01, 2024



As Large Language Models (LLMs) have become more advanced, they have outpaced our abilities to accurately evaluate their quality. Not only is finding data to adequately probe particular model properties difficult, but evaluating the correctness of a model's freeform generation alone is a challenge. To address this, many evaluations now rely on using LLMs themselves as judges to score the quality of outputs from other LLMs. Evaluations most commonly use a single large model like GPT4. While this method has grown in popularity, it is costly, has been shown to introduce intramodel bias, and in this work, we find that very large models are often unnecessary. We propose instead to evaluate models using a Panel of LLm evaluators (PoLL). Across three distinct judge settings and spanning six different datasets, we find that using a PoLL composed of a larger number of smaller models outperforms a single large judge, exhibits less intra-model bias due to its composition of disjoint model families, and does so while being over seven times less expensive.
SnapKV: LLM Knows What You are Looking for Before Generation
Apr 22, 2024



Large Language Models (LLMs) have made remarkable progress in processing extensive contexts, with the Key-Value (KV) cache playing a vital role in enhancing their performance. However, the growth of the KV cache in response to increasing input length poses challenges to memory and time efficiency. To address this problem, this paper introduces SnapKV, an innovative and fine-tuning-free approach that efficiently minimizes KV cache size while still delivering comparable performance in real-world applications. We discover that each attention head in the model consistently focuses on specific prompt attention features during generation. Meanwhile, this robust pattern can be obtained from an `observation' window located at the end of the prompts. Drawing on this insight, SnapKV automatically compresses KV caches by selecting clustered important KV positions for each attention head. Our approach significantly reduces the growing computational overhead and memory footprint when processing long input sequences. Specifically, SnapKV achieves a consistent decoding speed with a 3.6x increase in generation speed and an 8.2x enhancement in memory efficiency compared to baseline when processing inputs of 16K tokens. At the same time, it maintains comparable performance to baseline models across 16 long sequence datasets. Moreover, SnapKV can process up to 380K context tokens on a single A100-80GB GPU using HuggingFace implementation with minor changes, exhibiting only a negligible accuracy drop in the Needle-in-a-Haystack test. Further comprehensive studies suggest SnapKV's potential for practical applications.
From One to Many: Expanding the Scope of Toxicity Mitigation in Language Models
Mar 06, 2024



To date, toxicity mitigation in language models has almost entirely been focused on single-language settings. As language models embrace multilingual capabilities, it's crucial our safety measures keep pace. Recognizing this research gap, our approach expands the scope of conventional toxicity mitigation to address the complexities presented by multiple languages. In the absence of sufficient annotated datasets across languages, we employ translated data to evaluate and enhance our mitigation techniques. We also compare finetuning mitigation approaches against retrieval-augmented techniques under both static and continual toxicity mitigation scenarios. This allows us to examine the effects of translation quality and the cross-lingual transfer on toxicity mitigation. We also explore how model size and data quantity affect the success of these mitigation efforts. Covering nine languages, our study represents a broad array of linguistic families and levels of resource availability, ranging from high to mid-resource languages. Through comprehensive experiments, we provide insights into the complexities of multilingual toxicity mitigation, offering valuable insights and paving the way for future research in this increasingly important field. Code and data are available at https://github.com/for-ai/goodtriever.
MultiContrievers: Analysis of Dense Retrieval Representations
Feb 24, 2024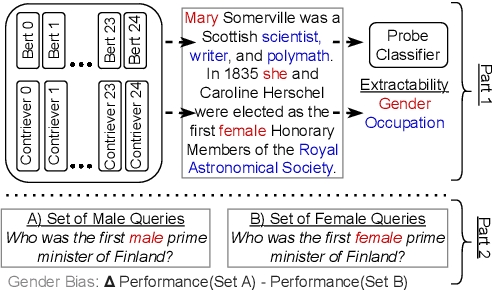

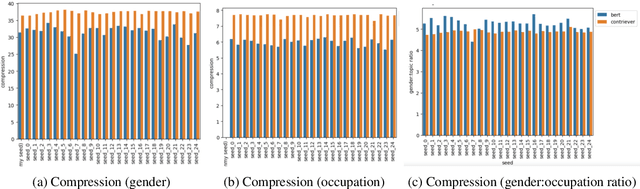
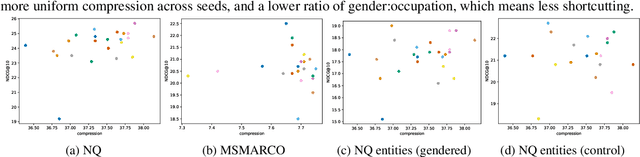
Dense retrievers compress source documents into (possibly lossy) vector representations, yet there is little analysis of what information is lost versus preserved, and how it affects downstream tasks. We conduct the first analysis of the information captured by dense retrievers compared to the language models they are based on (e.g., BERT versus Contriever). We use 25 MultiBert checkpoints as randomized initialisations to train MultiContrievers, a set of 25 contriever models. We test whether specific pieces of information -- such as gender and occupation -- can be extracted from contriever vectors of wikipedia-like documents. We measure this extractability via information theoretic probing. We then examine the relationship of extractability to performance and gender bias, as well as the sensitivity of these results to many random initialisations and data shuffles. We find that (1) contriever models have significantly increased extractability, but extractability usually correlates poorly with benchmark performance 2) gender bias is present, but is not caused by the contriever representations 3) there is high sensitivity to both random initialisation and to data shuffle, suggesting that future retrieval research should test across a wider spread of both.
Rank-without-GPT: Building GPT-Independent Listwise Rerankers on Open-Source Large Language Models
Dec 05, 2023



Listwise rerankers based on large language models (LLM) are the zero-shot state-of-the-art. However, current works in this direction all depend on the GPT models, making it a single point of failure in scientific reproducibility. Moreover, it raises the concern that the current research findings only hold for GPT models but not LLM in general. In this work, we lift this pre-condition and build for the first time effective listwise rerankers without any form of dependency on GPT. Our passage retrieval experiments show that our best list se reranker surpasses the listwise rerankers based on GPT-3.5 by 13% and achieves 97% effectiveness of the ones built on GPT-4. Our results also show that the existing training datasets, which were expressly constructed for pointwise ranking, are insufficient for building such listwise rerankers. Instead, high-quality listwise ranking data is required and crucial, calling for further work on building human-annotated listwise data resources.
Goodtriever: Adaptive Toxicity Mitigation with Retrieval-augmented Models
Oct 11, 2023
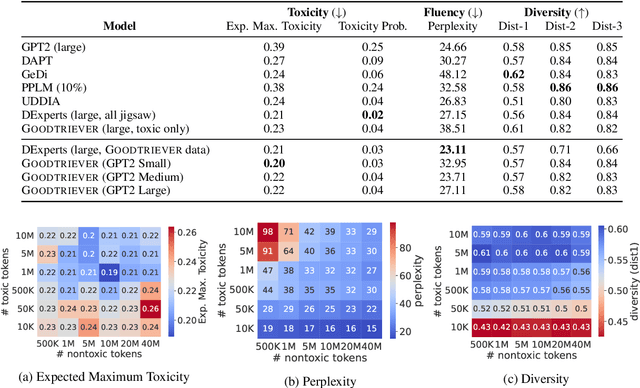


Considerable effort has been dedicated to mitigating toxicity, but existing methods often require drastic modifications to model parameters or the use of computationally intensive auxiliary models. Furthermore, previous approaches have often neglected the crucial factor of language's evolving nature over time. In this work, we present a comprehensive perspective on toxicity mitigation that takes into account its changing nature. We introduce Goodtriever, a flexible methodology that matches the current state-of-the-art toxicity mitigation while achieving 43% relative latency reduction during inference and being more computationally efficient. By incorporating a retrieval-based approach at decoding time, Goodtriever enables toxicity-controlled text generation. Our research advocates for an increased focus on adaptable mitigation techniques, which better reflect the data drift models face when deployed in the wild. Code and data are available at https://github.com/for-ai/goodtriever.
On the Challenges of Using Black-Box APIs for Toxicity Evaluation in Research
Apr 24, 2023



Perception of toxicity evolves over time and often differs between geographies and cultural backgrounds. Similarly, black-box commercially available APIs for detecting toxicity, such as the Perspective API, are not static, but frequently retrained to address any unattended weaknesses and biases. We evaluate the implications of these changes on the reproducibility of findings that compare the relative merits of models and methods that aim to curb toxicity. Our findings suggest that research that relied on inherited automatic toxicity scores to compare models and techniques may have resulted in inaccurate findings. Rescoring all models from HELM, a widely respected living benchmark, for toxicity with the recent version of the API led to a different ranking of widely used foundation models. We suggest caution in applying apples-to-apples comparisons between studies and lay recommendations for a more structured approach to evaluating toxicity over time. Code and data are available at https://github.com/for-ai/black-box-api-challenges.