 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRePo: Language Models with Context Re-Positioning
Dec 16, 2025



In-context learning is fundamental to modern Large Language Models (LLMs); however, prevailing architectures impose a rigid and fixed contextual structure by assigning linear or constant positional indices. Drawing on Cognitive Load Theory (CLT), we argue that this uninformative structure increases extraneous cognitive load, consuming finite working memory capacity that should be allocated to deep reasoning and attention allocation. To address this, we propose RePo, a novel mechanism that reduces extraneous load via context re-positioning. Unlike standard approaches, RePo utilizes a differentiable module, $f_φ$, to assign token positions that capture contextual dependencies, rather than replying on pre-defined integer range. By continually pre-training on the OLMo-2 1B backbone, we demonstrate that RePo significantly enhances performance on tasks involving noisy contexts, structured data, and longer context length, while maintaining competitive performance on general short-context tasks. Detailed analysis reveals that RePo successfully allocate higher attention to distant but relevant information, assign positions in dense and non-linear space, and capture the intrinsic structure of the input context. Our code is available at https://github.com/SakanaAI/repo.
ALR$^2$: A Retrieve-then-Reason Framework for Long-context Question Answering
Oct 04, 2024



The context window of large language models (LLMs) has been extended significantly in recent years. However, while the context length that the LLM can process has grown, the capability of the model to accurately reason over that context degrades noticeably. This occurs because modern LLMs often become overwhelmed by the vast amount of information in the context; when answering questions, the model must identify and reason over relevant evidence sparsely distributed throughout the text. To alleviate the challenge of long-context reasoning, we develop a retrieve-then-reason framework, enabling LLMs to reason over relevant evidence collected during an intermediate retrieval step. We find that modern LLMs struggle to accurately retrieve relevant facts and instead, often hallucinate "retrieved facts", resulting in flawed reasoning and the production of incorrect answers. To address these issues, we introduce ALR$^2$, a method that augments the long-context reasoning capability of LLMs via an explicit two-stage procedure, i.e., aligning LLMs with the objectives of both retrieval and reasoning. We demonstrate the efficacy of ALR$^2$ for mitigating performance degradation in long-context reasoning tasks. Through extensive experiments on long-context QA benchmarks, we find our method to outperform competitive baselines by large margins, achieving at least 8.4 and 7.9 EM gains on the long-context versions of HotpotQA and SQuAD datasets, respectively.
On the Transformations across Reward Model, Parameter Update, and In-Context Prompt
Jun 24, 2024Despite the general capabilities of pre-trained large language models (LLMs), they still need further adaptation to better serve practical applications. In this paper, we demonstrate the interchangeability of three popular and distinct adaptation tools: parameter updating, reward modeling, and in-context prompting. This interchangeability establishes a triangular framework with six transformation directions, each of which facilitates a variety of applications. Our work offers a holistic view that unifies numerous existing studies and suggests potential research directions. We envision our work as a useful roadmap for future research on LLMs.
M3T: A New Benchmark Dataset for Multi-Modal Document-Level Machine Translation
Jun 12, 2024
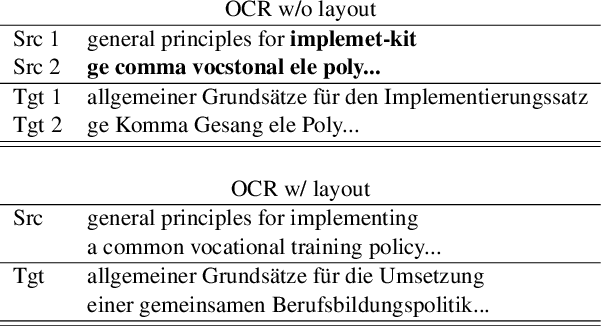

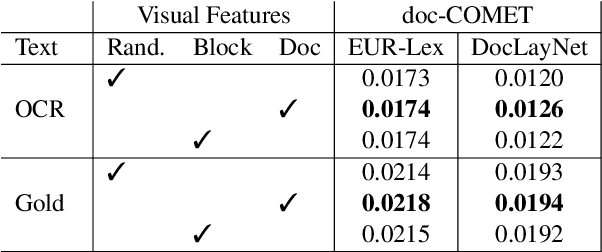
Document translation poses a challenge for Neural Machine Translation (NMT) systems. Most document-level NMT systems rely on meticulously curated sentence-level parallel data, assuming flawless extraction of text from documents along with their precise reading order. These systems also tend to disregard additional visual cues such as the document layout, deeming it irrelevant. However, real-world documents often possess intricate text layouts that defy these assumptions. Extracting information from Optical Character Recognition (OCR) or heuristic rules can result in errors, and the layout (e.g., paragraphs, headers) may convey relationships between distant sections of text. This complexity is particularly evident in widely used PDF documents, which represent information visually. This paper addresses this gap by introducing M3T, a novel benchmark dataset tailored to evaluate NMT systems on the comprehensive task of translating semi-structured documents. This dataset aims to bridge the evaluation gap in document-level NMT systems, acknowledging the challenges posed by rich text layouts in real-world applications.
Cross-lingual Contextualized Phrase Retrieval
Mar 25, 2024Phrase-level dense retrieval has shown many appealing characteristics in downstream NLP tasks by leveraging the fine-grained information that phrases offer. In our work, we propose a new task formulation of dense retrieval, cross-lingual contextualized phrase retrieval, which aims to augment cross-lingual applications by addressing polysemy using context information. However, the lack of specific training data and models are the primary challenges to achieve our goal. As a result, we extract pairs of cross-lingual phrases using word alignment information automatically induced from parallel sentences. Subsequently, we train our Cross-lingual Contextualized Phrase Retriever (CCPR) using contrastive learning, which encourages the hidden representations of phrases with similar contexts and semantics to align closely. Comprehensive experiments on both the cross-lingual phrase retrieval task and a downstream task, i.e, machine translation, demonstrate the effectiveness of CCPR. On the phrase retrieval task, CCPR surpasses baselines by a significant margin, achieving a top-1 accuracy that is at least 13 points higher. When utilizing CCPR to augment the large-language-model-based translator, it achieves average gains of 0.7 and 1.5 in BERTScore for translations from X=>En and vice versa, respectively, on WMT16 dataset. Our code and data are available at \url{https://github.com/ghrua/ccpr_release}.
Inferflow: an Efficient and Highly Configurable Inference Engine for Large Language Models
Jan 16, 2024We present Inferflow, an efficient and highly configurable inference engine for large language models (LLMs). With Inferflow, users can serve most of the common transformer models by simply modifying some lines in corresponding configuration files, without writing a single line of source code. Compared with most existing inference engines, Inferflow has some key features. First, by implementing a modular framework of atomic build-blocks and technologies, Inferflow is compositionally generalizable to new models. Second, 3.5-bit quantization is introduced in Inferflow as a tradeoff between 3-bit and 4-bit quantization. Third, hybrid model partitioning for multi-GPU inference is introduced in Inferflow to better balance inference speed and throughput than the existing partition-by-layer and partition-by-tensor strategies.
GPT4Video: A Unified Multimodal Large Language Model for lnstruction-Followed Understanding and Safety-Aware Generation
Nov 25, 2023



While the recent advances in Multimodal Large Language Models (MLLMs) constitute a significant leap forward in the field, these models are predominantly confined to the realm of input-side multimodal comprehension, lacking the capacity for multimodal content generation. To fill this gap, we present GPT4Video, a unified multi-model framework that empowers Large Language Models (LLMs) with the capability of both video understanding and generation. Specifically, we develop an instruction-following-based approach integrated with the stable diffusion generative model, which has demonstrated to effectively and securely handle video generation scenarios. GPT4Video offers the following benefits: 1) It exhibits impressive capabilities in both video understanding and generation scenarios. For example, GPT4Video outperforms Valley by 11.8\% on the Video Question Answering task, and surpasses NExt-GPT by 2.3\% on the Text to Video generation task. 2) it endows the LLM/MLLM with video generation capabilities without requiring additional training parameters and can flexibly interface with a wide range of models to perform video generation. 3) it maintains a safe and healthy conversation not only in output-side but also the input side in an end-to-end manner. Qualitative and qualitative experiments demonstrate that GPT4Video holds the potential to function as a effective, safe and Humanoid-like video assistant that can handle both video understanding and generation scenarios.
Repetition In Repetition Out: Towards Understanding Neural Text Degeneration from the Data Perspective
Oct 16, 2023
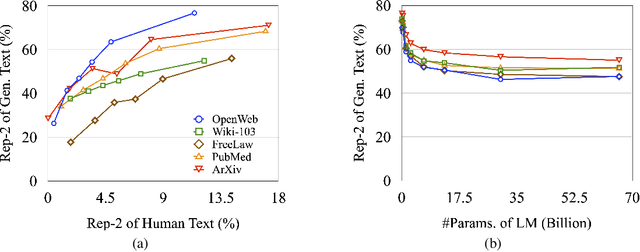
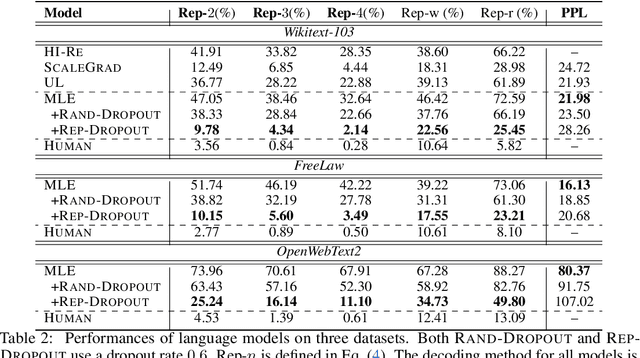
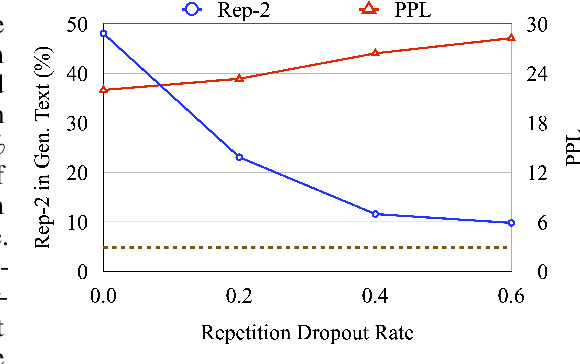
There are a number of diverging hypotheses about the neural text degeneration problem, i.e., generating repetitive and dull loops, which makes this problem both interesting and confusing. In this work, we aim to advance our understanding by presenting a straightforward and fundamental explanation from the data perspective. Our preliminary investigation reveals a strong correlation between the degeneration issue and the presence of repetitions in training data. Subsequent experiments also demonstrate that by selectively dropping out the attention to repetitive words in training data, degeneration can be significantly minimized. Furthermore, our empirical analysis illustrates that prior works addressing the degeneration issue from various standpoints, such as the high-inflow words, the likelihood objective, and the self-reinforcement phenomenon, can be interpreted by one simple explanation. That is, penalizing the repetitions in training data is a common and fundamental factor for their effectiveness. Moreover, our experiments reveal that penalizing the repetitions in training data remains critical even when considering larger model sizes and instruction tuning.
TextBind: Multi-turn Interleaved Multimodal Instruction-following in the Wild
Sep 19, 2023Large language models with instruction-following abilities have revolutionized the field of artificial intelligence. These models show exceptional generalizability to tackle various real-world tasks through their natural language interfaces. However, their performance heavily relies on high-quality exemplar data, which is often difficult to obtain. This challenge is further exacerbated when it comes to multimodal instruction following. We introduce TextBind, an almost annotation-free framework for empowering larger language models with the multi-turn interleaved multimodal instruction-following capabilities. Our approach requires only image-caption pairs and generates multi-turn multimodal instruction-response conversations from a language model. To accommodate interleaved image-text inputs and outputs, we devise MIM, a language model-centric architecture that seamlessly integrates image encoder and decoder models. We release our dataset, model, and demo to foster future research in the area of multimodal instruction following.
PandaGPT: One Model To Instruction-Follow Them All
May 25, 2023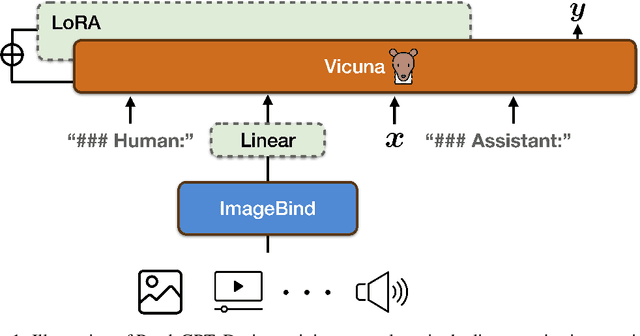



We present PandaGPT, an approach to emPower large lANguage moDels with visual and Auditory instruction-following capabilities. Our pilot experiments show that PandaGPT can perform complex tasks such as detailed image description generation, writing stories inspired by videos, and answering questions about audios. More interestingly, PandaGPT can take multimodal inputs simultaneously and compose their semantics naturally. For example, PandaGPT can connect how objects look in an image/video and how they sound in an audio. To do so, PandaGPT combines the multimodal encoders from ImageBind and the large language models from Vicuna. Notably, only aligned image-text pairs are required for the training of PandaGPT. Thanks to the strong capability of ImageBind in embedding data from different modalities into the same space, PandaGPT displays emergent, i.e. zero-shot, cross-modal behaviors for data other than image and text (e.g., video, audio, depth, thermal, and IMU). We hope that PandaGPT serves as an initial step toward building AGI that can perceive and understand inputs in different modalities holistically, as we humans do. Our project page is at https://panda-gpt.github.io/.