 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAesthetic Camera Viewpoint Suggestion with 3D Aesthetic Field
Feb 23, 2026The aesthetic quality of a scene depends strongly on camera viewpoint. Existing approaches for aesthetic viewpoint suggestion are either single-view adjustments, predicting limited camera adjustments from a single image without understanding scene geometry, or 3D exploration approaches, which rely on dense captures or prebuilt 3D environments coupled with costly reinforcement learning (RL) searches. In this work, we introduce the notion of 3D aesthetic field that enables geometry-grounded aesthetic reasoning in 3D with sparse captures, allowing efficient viewpoint suggestions in contrast to costly RL searches. We opt to learn this 3D aesthetic field using a feedforward 3D Gaussian Splatting network that distills high-level aesthetic knowledge from a pretrained 2D aesthetic model into 3D space, enabling aesthetic prediction for novel viewpoints from only sparse input views. Building on this field, we propose a two-stage search pipeline that combines coarse viewpoint sampling with gradient-based refinement, efficiently identifying aesthetically appealing viewpoints without dense captures or RL exploration. Extensive experiments show that our method consistently suggests viewpoints with superior framing and composition compared to existing approaches, establishing a new direction toward 3D-aware aesthetic modeling.
Quark Medical Alignment: A Holistic Multi-Dimensional Alignment and Collaborative Optimization Paradigm
Feb 12, 2026While reinforcement learning for large language model alignment has progressed rapidly in recent years, transferring these paradigms to high-stakes medical question answering reveals a fundamental paradigm mismatch. Reinforcement Learning from Human Feedback relies on preference annotations that are prohibitively expensive and often fail to reflect the absolute correctness of medical facts. Reinforcement Learning from Verifiable Rewards lacks effective automatic verifiers and struggles to handle complex clinical contexts. Meanwhile, medical alignment requires the simultaneous optimization of correctness, safety, and compliance, yet multi-objective heterogeneous reward signals are prone to scale mismatch and optimization conflicts.To address these challenges, we propose a robust medical alignment paradigm. We first construct a holistic multi-dimensional medical alignment matrix that decomposes alignment objectives into four categories: fundamental capabilities, expert knowledge, online feedback, and format specifications. Within each category, we establish a closed loop of where observable metrics inform attributable diagnosis, which in turn drives optimizable rewards, thereby providing fine-grained, high-resolution supervision signals for subsequent iterative optimization. To resolve gradient domination and optimization instability problem caused by heterogeneous signals, we further propose a unified optimization mechanism. This mechanism employs Reference-Frozen Normalization to align reward scales and implements a Tri-Factor Adaptive Dynamic Weighting strategy to achieve collaborative optimization that is weakness-oriented, risk-prioritized, and redundancy-reducing. Experimental results demonstrate the effectiveness of our proposed paradigm in real-world medical scenario evaluations, establishing a new paradigm for complex alignment in vertical domains.
We Need a More Robust Classifier: Dual Causal Learning Empowers Domain-Incremental Time Series Classification
Jan 15, 2026The World Wide Web thrives on intelligent services that rely on accurate time series classification, which has recently witnessed significant progress driven by advances in deep learning. However, existing studies face challenges in domain incremental learning. In this paper, we propose a lightweight and robust dual-causal disentanglement framework (DualCD) to enhance the robustness of models under domain incremental scenarios, which can be seamlessly integrated into time series classification models. Specifically, DualCD first introduces a temporal feature disentanglement module to capture class-causal features and spurious features. The causal features can offer sufficient predictive power to support the classifier in domain incremental learning settings. To accurately capture these causal features, we further design a dual-causal intervention mechanism to eliminate the influence of both intra-class and inter-class confounding features. This mechanism constructs variant samples by combining the current class's causal features with intra-class spurious features and with causal features from other classes. The causal intervention loss encourages the model to accurately predict the labels of these variant samples based solely on the causal features. Extensive experiments on multiple datasets and models demonstrate that DualCD effectively improves performance in domain incremental scenarios. We summarize our rich experiments into a comprehensive benchmark to facilitate research in domain incremental time series classification.
PandaGPT: One Model To Instruction-Follow Them All
May 25, 2023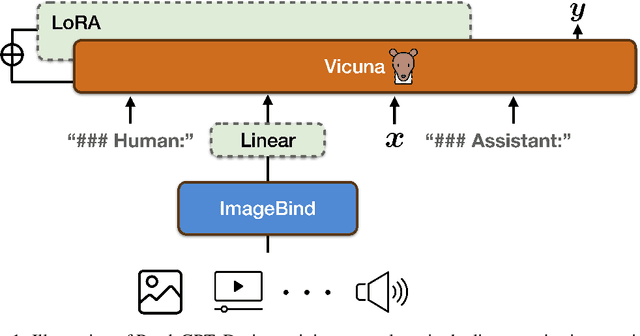



We present PandaGPT, an approach to emPower large lANguage moDels with visual and Auditory instruction-following capabilities. Our pilot experiments show that PandaGPT can perform complex tasks such as detailed image description generation, writing stories inspired by videos, and answering questions about audios. More interestingly, PandaGPT can take multimodal inputs simultaneously and compose their semantics naturally. For example, PandaGPT can connect how objects look in an image/video and how they sound in an audio. To do so, PandaGPT combines the multimodal encoders from ImageBind and the large language models from Vicuna. Notably, only aligned image-text pairs are required for the training of PandaGPT. Thanks to the strong capability of ImageBind in embedding data from different modalities into the same space, PandaGPT displays emergent, i.e. zero-shot, cross-modal behaviors for data other than image and text (e.g., video, audio, depth, thermal, and IMU). We hope that PandaGPT serves as an initial step toward building AGI that can perceive and understand inputs in different modalities holistically, as we humans do. Our project page is at https://panda-gpt.github.io/.
An Empirical Study On Contrastive Search And Contrastive Decoding For Open-ended Text Generation
Nov 19, 2022



In the study, we empirically compare the two recently proposed decoding methods, i.e. Contrastive Search (CS) and Contrastive Decoding (CD), for open-ended text generation. The automatic evaluation results suggest that, while CS performs worse than CD on the MAUVE metric, it substantially surpasses CD on the diversity and coherence metrics. More notably, extensive human evaluations across three different domains demonstrate that human annotators are universally more in favor of CS over CD with substantial margins. The contradicted results between MAUVE and human evaluations reveal that MAUVE does not accurately reflect human preferences. Therefore, we call upon the research community to develop better evaluation metrics for open-ended text generation. To ensure the reproducibility of our work, we have open-sourced all our code, evaluation results, as well as human annotations at https://github.com/yxuansu/Contrastive_Search_versus_Contrastive_Decoding.