 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Data Difficulty: Improving Coding Models via Reinforcement Learning on Fresh and Challenging Problems
Mar 08, 2026Training next-generation code generation models requires high-quality datasets, yet existing datasets face difficulty imbalance, format inconsistency, and data quality problems. We address these challenges through systematic data processing and difficulty scaling. We introduce a four-stage Data Processing Framework encompassing collection, processing, filtering, and verification, incorporating Automatic Difficulty Filtering via an LLM-based predict-calibrate-select framework that leverages multi-dimensional difficulty metrics across five weighted dimensions to retain challenging problems while removing simplistic ones. The resulting MicroCoder dataset comprises tens of thousands of curated real competitive programming problems from diverse platforms, emphasizing recency and difficulty. Evaluations on strictly unseen LiveCodeBench demonstrate that MicroCoder achieves 3x larger performance gains within 300 training steps compared to widely-used baseline datasets of comparable size, with consistent advantages under both GRPO and its variant training algorithms. The MicroCoder dataset delivers obvious improvements on medium and hard problems across different model sizes, achieving up to 17.2% relative gains in overall performance where model capabilities are most stretched. These results validate that difficulty-aware data curation improves model performance on challenging tasks, providing multiple insights for dataset creation in code generation.
Breaking Training Bottlenecks: Effective and Stable Reinforcement Learning for Coding Models
Mar 08, 2026Modern code generation models exhibit longer outputs, accelerated capability growth, and changed training dynamics, rendering traditional training methodologies, algorithms, and datasets ineffective for improving their performance. To address these training bottlenecks, we propose MicroCoder-GRPO, an improved Group Relative Policy Optimization approach with three innovations: conditional truncation masking to improve long output potential while maintaining training stability, diversity-determined temperature selection to maintain and encourage output diversity, and removal of KL loss with high clipping ratios to facilitate solution diversity. MicroCoder-GRPO achieves up to 17.6% relative improvement over strong baselines on LiveCodeBench v6, with more pronounced gains under extended context evaluation. Additionally, we release MicroCoder-Dataset, a more challenging training corpus that achieves 3x larger performance gains than mainstream datasets on LiveCodeBench v6 within 300 training steps, and MicroCoder-Evaluator, a robust framework with approximately 25% improved evaluation accuracy and around 40% faster execution. Through comprehensive analysis across more than thirty controlled experiments, we reveal 34 training insights across seven main aspects, demonstrating that properly trained models can achieve competitive performance with larger counterparts.
A Survey on Prompt Tuning
Jul 09, 2025This survey reviews prompt tuning, a parameter-efficient approach for adapting language models by prepending trainable continuous vectors while keeping the model frozen. We classify existing approaches into two categories: direct prompt learning and transfer learning. Direct prompt learning methods include: general optimization approaches, encoder-based methods, decomposition strategies, and mixture-of-experts frameworks. Transfer learning methods consist of: general transfer approaches, encoder-based methods, and decomposition strategies. For each method, we analyze method designs, innovations, insights, advantages, and disadvantages, with illustrative visualizations comparing different frameworks. We identify challenges in computational efficiency and training stability, and discuss future directions in improving training robustness and broadening application scope.
PT-MoE: An Efficient Finetuning Framework for Integrating Mixture-of-Experts into Prompt Tuning
May 14, 2025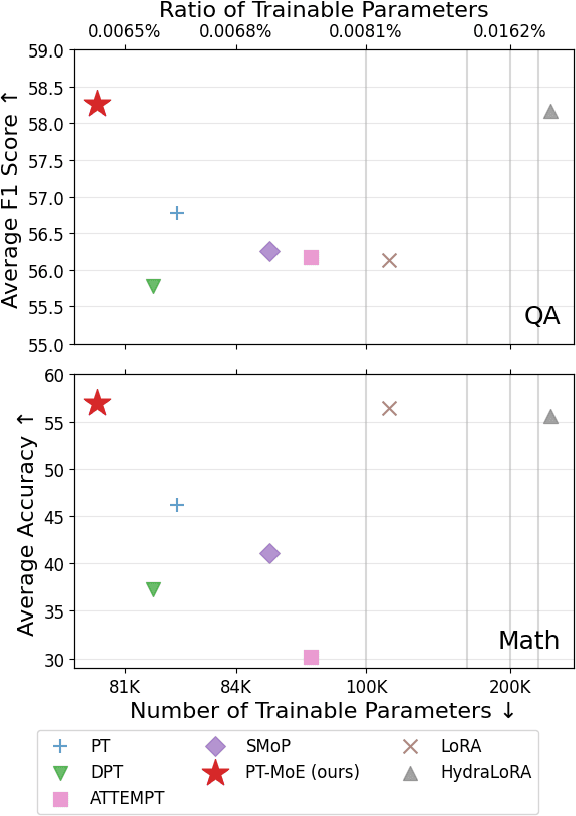

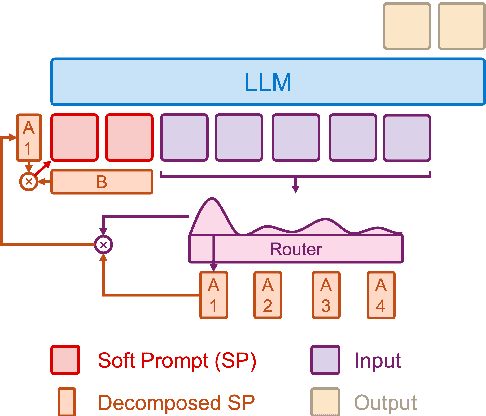
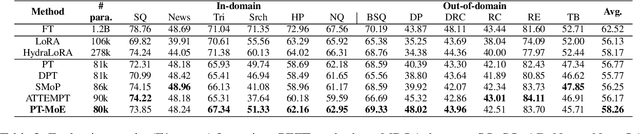
Parameter-efficient fine-tuning (PEFT) methods have shown promise in adapting large language models, yet existing approaches exhibit counter-intuitive phenomena: integrating router into prompt tuning (PT) increases training efficiency yet does not improve performance universally; parameter reduction through matrix decomposition can improve performance in specific domains. Motivated by these observations and the modular nature of PT, we propose PT-MoE, a novel framework that integrates matrix decomposition with mixture-of-experts (MoE) routing for efficient PT. Results across 17 datasets demonstrate that PT-MoE achieves state-of-the-art performance in both question answering (QA) and mathematical problem solving tasks, improving F1 score by 1.49 points over PT and 2.13 points over LoRA in QA tasks, while enhancing mathematical accuracy by 10.75 points over PT and 0.44 points over LoRA, all while using 25% fewer parameters than LoRA. Our analysis reveals that while PT methods generally excel in QA tasks and LoRA-based methods in math datasets, the integration of matrix decomposition and MoE in PT-MoE yields complementary benefits: decomposition enables efficient parameter sharing across experts while MoE provides dynamic adaptation, collectively enabling PT-MoE to demonstrate cross-task consistency and generalization abilities. These findings, along with ablation studies on routing mechanisms and architectural components, provide insights for future PEFT methods.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Prompt Compression for Large Language Models: A Survey
Oct 17, 2024Leveraging large language models (LLMs) for complex natural language tasks typically requires long-form prompts to convey detailed requirements and information, which results in increased memory usage and inference costs. To mitigate these challenges, multiple efficient methods have been proposed, with prompt compression gaining significant research interest. This survey provides an overview of prompt compression techniques, categorized into hard prompt methods and soft prompt methods. First, the technical approaches of these methods are compared, followed by an exploration of various ways to understand their mechanisms, including the perspectives of attention optimization, Parameter-Efficient Fine-Tuning (PEFT), modality integration, and new synthetic language. We also examine the downstream adaptations of various prompt compression techniques. Finally, the limitations of current prompt compression methods are analyzed, and several future directions are outlined, such as optimizing the compression encoder, combining hard and soft prompts methods, and leveraging insights from multimodality.
ALR$^2$: A Retrieve-then-Reason Framework for Long-context Question Answering
Oct 04, 2024



The context window of large language models (LLMs) has been extended significantly in recent years. However, while the context length that the LLM can process has grown, the capability of the model to accurately reason over that context degrades noticeably. This occurs because modern LLMs often become overwhelmed by the vast amount of information in the context; when answering questions, the model must identify and reason over relevant evidence sparsely distributed throughout the text. To alleviate the challenge of long-context reasoning, we develop a retrieve-then-reason framework, enabling LLMs to reason over relevant evidence collected during an intermediate retrieval step. We find that modern LLMs struggle to accurately retrieve relevant facts and instead, often hallucinate "retrieved facts", resulting in flawed reasoning and the production of incorrect answers. To address these issues, we introduce ALR$^2$, a method that augments the long-context reasoning capability of LLMs via an explicit two-stage procedure, i.e., aligning LLMs with the objectives of both retrieval and reasoning. We demonstrate the efficacy of ALR$^2$ for mitigating performance degradation in long-context reasoning tasks. Through extensive experiments on long-context QA benchmarks, we find our method to outperform competitive baselines by large margins, achieving at least 8.4 and 7.9 EM gains on the long-context versions of HotpotQA and SQuAD datasets, respectively.
To Code, or Not To Code? Exploring Impact of Code in Pre-training
Aug 20, 2024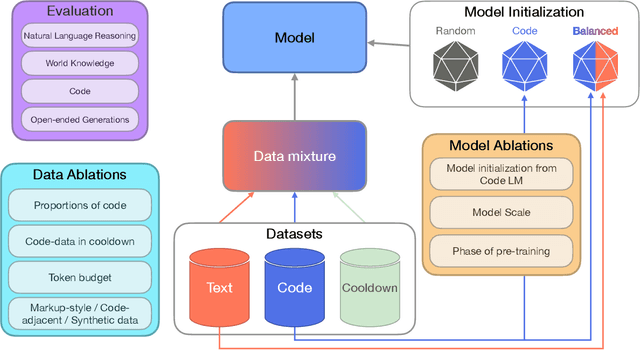
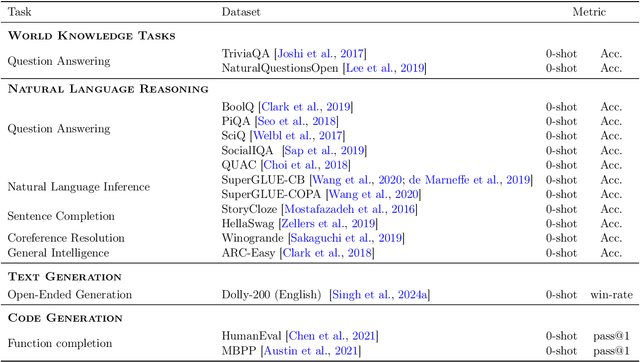
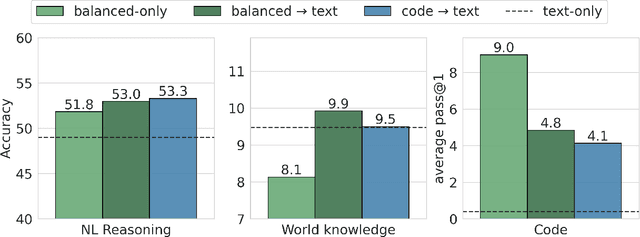
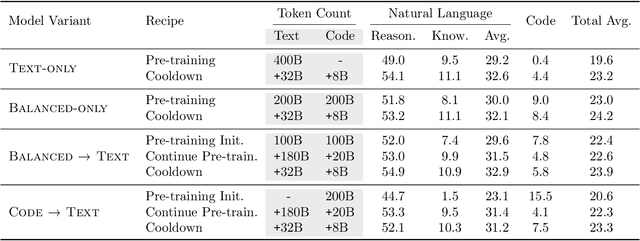
Including code in the pre-training data mixture, even for models not specifically designed for code, has become a common practice in LLMs pre-training. While there has been anecdotal consensus among practitioners that code data plays a vital role in general LLMs' performance, there is only limited work analyzing the precise impact of code on non-code tasks. In this work, we systematically investigate the impact of code data on general performance. We ask "what is the impact of code data used in pre-training on a large variety of downstream tasks beyond code generation". We conduct extensive ablations and evaluate across a broad range of natural language reasoning tasks, world knowledge tasks, code benchmarks, and LLM-as-a-judge win-rates for models with sizes ranging from 470M to 2.8B parameters. Across settings, we find a consistent results that code is a critical building block for generalization far beyond coding tasks and improvements to code quality have an outsized impact across all tasks. In particular, compared to text-only pre-training, the addition of code results in up to relative increase of 8.2% in natural language (NL) reasoning, 4.2% in world knowledge, 6.6% improvement in generative win-rates, and a 12x boost in code performance respectively. Our work suggests investments in code quality and preserving code during pre-training have positive impacts.
500xCompressor: Generalized Prompt Compression for Large Language Models
Aug 06, 2024Prompt compression is crucial for enhancing inference speed, reducing costs, and improving user experience. However, current methods face challenges such as low compression ratios and potential data leakage during evaluation. To address these issues, we propose 500xCompressor, a method that compresses extensive natural language contexts into a minimum of one single special token. The 500xCompressor introduces approximately 0.3% additional parameters and achieves compression ratios ranging from 6x to 480x. It is designed to compress any text, answer various types of questions, and could be utilized by the original large language model (LLM) without requiring fine-tuning. Initially, 500xCompressor was pretrained on the Arxiv Corpus, followed by fine-tuning on the ArxivQA dataset, and subsequently evaluated on strictly unseen and classical question answering (QA) datasets. The results demonstrate that the LLM retained 62.26-72.89% of its capabilities compared to using non-compressed prompts. This study also shows that not all the compressed tokens are equally utilized and that K V values have significant advantages over embeddings in preserving information at high compression ratios. The highly compressive nature of natural language prompts, even for fine-grained complex information, suggests promising potential for future applications and further research into developing a new LLM language.
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
May 01, 2024



As Large Language Models (LLMs) have become more advanced, they have outpaced our abilities to accurately evaluate their quality. Not only is finding data to adequately probe particular model properties difficult, but evaluating the correctness of a model's freeform generation alone is a challenge. To address this, many evaluations now rely on using LLMs themselves as judges to score the quality of outputs from other LLMs. Evaluations most commonly use a single large model like GPT4. While this method has grown in popularity, it is costly, has been shown to introduce intramodel bias, and in this work, we find that very large models are often unnecessary. We propose instead to evaluate models using a Panel of LLm evaluators (PoLL). Across three distinct judge settings and spanning six different datasets, we find that using a PoLL composed of a larger number of smaller models outperforms a single large judge, exhibits less intra-model bias due to its composition of disjoint model families, and does so while being over seven times less expensive.