 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
FLARE: Faithful Logic-Aided Reasoning and Exploration
Oct 14, 2024
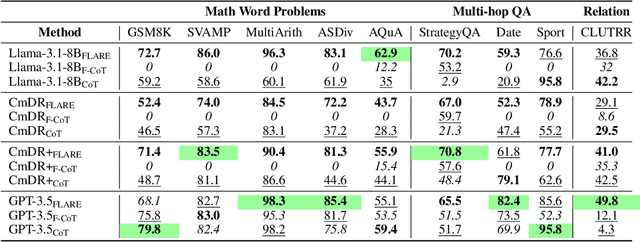
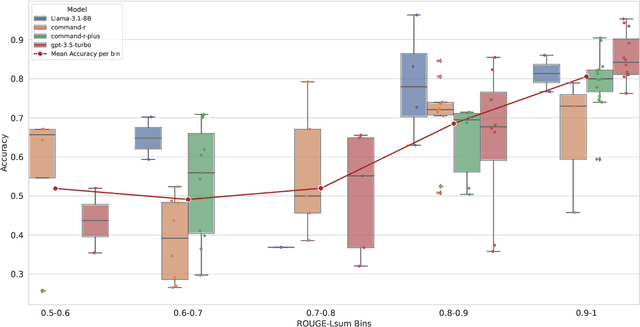

Modern Question Answering (QA) and Reasoning approaches based on Large Language Models (LLMs) commonly use prompting techniques, such as Chain-of-Thought (CoT), assuming the resulting generation will have a more granular exploration and reasoning over the question space and scope. However, such methods struggle with generating outputs that are faithful to the intermediate chain of reasoning produced by the model. On the other end of the spectrum, neuro-symbolic methods such as Faithful CoT (F-CoT) propose to combine LLMs with external symbolic solvers. While such approaches boast a high degree of faithfulness, they usually require a model trained for code generation and struggle with tasks that are ambiguous or hard to formalise strictly. We introduce \textbf{F}aithful \textbf{L}ogic-\textbf{A}ided \textbf{R}easoning and \textbf{E}xploration (\textbf{\ours}), a novel interpretable approach for traversing the problem space using task decompositions. We use the LLM to plan a solution, soft-formalise the query into facts and predicates using a logic programming code and simulate that code execution using an exhaustive multi-hop search over the defined space. Our method allows us to compute the faithfulness of the reasoning process w.r.t. the generated code and analyse the steps of the multi-hop search without relying on external solvers. Our methods achieve SOTA results on $\mathbf{7}$ out of $\mathbf{9}$ diverse reasoning benchmarks. We also show that model faithfulness positively correlates with overall performance and further demonstrate that {\textbf{\ours}} allows pinpointing the decisive factors sufficient for and leading to the correct answer with optimal reasoning during the multi-hop search.
ALR$^2$: A Retrieve-then-Reason Framework for Long-context Question Answering
Oct 04, 2024



The context window of large language models (LLMs) has been extended significantly in recent years. However, while the context length that the LLM can process has grown, the capability of the model to accurately reason over that context degrades noticeably. This occurs because modern LLMs often become overwhelmed by the vast amount of information in the context; when answering questions, the model must identify and reason over relevant evidence sparsely distributed throughout the text. To alleviate the challenge of long-context reasoning, we develop a retrieve-then-reason framework, enabling LLMs to reason over relevant evidence collected during an intermediate retrieval step. We find that modern LLMs struggle to accurately retrieve relevant facts and instead, often hallucinate "retrieved facts", resulting in flawed reasoning and the production of incorrect answers. To address these issues, we introduce ALR$^2$, a method that augments the long-context reasoning capability of LLMs via an explicit two-stage procedure, i.e., aligning LLMs with the objectives of both retrieval and reasoning. We demonstrate the efficacy of ALR$^2$ for mitigating performance degradation in long-context reasoning tasks. Through extensive experiments on long-context QA benchmarks, we find our method to outperform competitive baselines by large margins, achieving at least 8.4 and 7.9 EM gains on the long-context versions of HotpotQA and SQuAD datasets, respectively.
Multilingual Arbitrage: Optimizing Data Pools to Accelerate Multilingual Progress
Aug 27, 2024



The use of synthetic data has played a critical role in recent state-of-art breakthroughs. However, overly relying on a single oracle teacher model to generate data has been shown to lead to model collapse and invite propagation of biases. These limitations are particularly evident in multilingual settings, where the absence of a universally effective teacher model that excels across all languages presents significant challenges. In this work, we address these extreme difference by introducing "multilingual arbitrage", which capitalizes on performance variations between multiple models for a given language. To do so, we strategically route samples through a diverse pool of models, each with unique strengths in different languages. Across exhaustive experiments on state-of-art models, our work suggests that arbitrage techniques allow for spectacular gains in performance that far outperform relying on a single teacher. In particular, compared to the best single teacher, we observe gains of up to 56.5% improvement in win rates averaged across all languages when switching to multilingual arbitrage. We observe the most significant gains for the least resourced languages in our pool.
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
May 01, 2024



As Large Language Models (LLMs) have become more advanced, they have outpaced our abilities to accurately evaluate their quality. Not only is finding data to adequately probe particular model properties difficult, but evaluating the correctness of a model's freeform generation alone is a challenge. To address this, many evaluations now rely on using LLMs themselves as judges to score the quality of outputs from other LLMs. Evaluations most commonly use a single large model like GPT4. While this method has grown in popularity, it is costly, has been shown to introduce intramodel bias, and in this work, we find that very large models are often unnecessary. We propose instead to evaluate models using a Panel of LLm evaluators (PoLL). Across three distinct judge settings and spanning six different datasets, we find that using a PoLL composed of a larger number of smaller models outperforms a single large judge, exhibits less intra-model bias due to its composition of disjoint model families, and does so while being over seven times less expensive.
To Adapt or to Annotate: Challenges and Interventions for Domain Adaptation in Open-Domain Question Answering
Dec 20, 2022Recent advances in open-domain question answering (ODQA) have demonstrated impressive accuracy on standard Wikipedia style benchmarks. However, it is less clear how robust these models are and how well they perform when applied to real-world applications in drastically different domains. While there has been some work investigating how well ODQA models perform when tested for out-of-domain (OOD) generalization, these studies have been conducted only under conservative shifts in data distribution and typically focus on a single component (ie. retrieval) rather than an end-to-end system. In response, we propose a more realistic and challenging domain shift evaluation setting and, through extensive experiments, study end-to-end model performance. We find that not only do models fail to generalize, but high retrieval scores often still yield poor answer prediction accuracy. We then categorize different types of shifts and propose techniques that, when presented with a new dataset, predict if intervention methods are likely to be successful. Finally, using insights from this analysis, we propose and evaluate several intervention methods which improve end-to-end answer F1 score by up to 24 points.
Attributed Question Answering: Evaluation and Modeling for Attributed Large Language Models
Dec 15, 2022



Large language models (LLMs) have shown impressive results across a variety of tasks while requiring little or no direct supervision. Further, there is mounting evidence that LLMs may have potential in information-seeking scenarios. We believe the ability of an LLM to attribute the text that it generates is likely to be crucial for both system developers and users in this setting. We propose and study Attributed QA as a key first step in the development of attributed LLMs. We develop a reproducable evaluation framework for the task, using human annotations as a gold standard and a correlated automatic metric that we show is suitable for development settings. We describe and benchmark a broad set of architectures for the task. Our contributions give some concrete answers to two key questions (How to measure attribution?, and How well do current state-of-the-art methods perform on attribution?), and give some hints as to how to address a third key question (How to build LLMs with attribution?).
MuRAG: Multimodal Retrieval-Augmented Generator for Open Question Answering over Images and Text
Oct 06, 2022

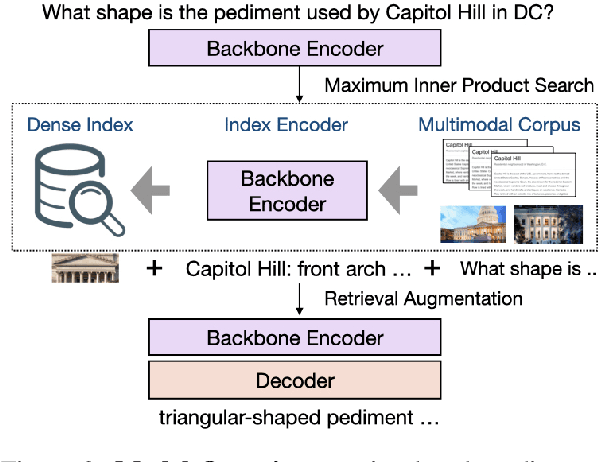

While language Models store a massive amount of world knowledge implicitly in their parameters, even very large models often fail to encode information about rare entities and events, while incurring huge computational costs. Recently, retrieval-augmented models, such as REALM, RAG, and RETRO, have incorporated world knowledge into language generation by leveraging an external non-parametric index and have demonstrated impressive performance with constrained model sizes. However, these methods are restricted to retrieving only textual knowledge, neglecting the ubiquitous amount of knowledge in other modalities like images -- much of which contains information not covered by any text. To address this limitation, we propose the first Multimodal Retrieval-Augmented Transformer (MuRAG), which accesses an external non-parametric multimodal memory to augment language generation. MuRAG is pre-trained with a mixture of large-scale image-text and text-only corpora using a joint contrastive and generative loss. We perform experiments on two different datasets that require retrieving and reasoning over both images and text to answer a given query: WebQA, and MultimodalQA. Our results show that MuRAG achieves state-of-the-art accuracy, outperforming existing models by 10-20\% absolute on both datasets and under both distractor and full-wiki settings.
QA Is the New KR: Question-Answer Pairs as Knowledge Bases
Jul 01, 2022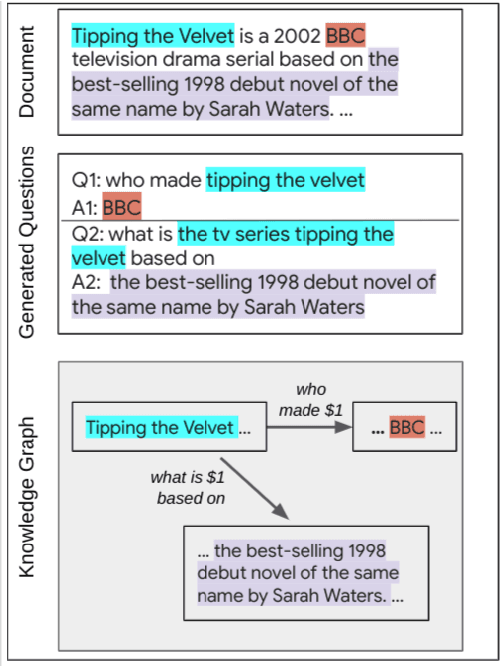
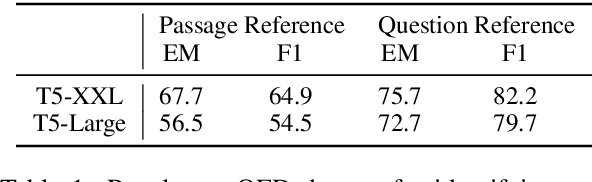
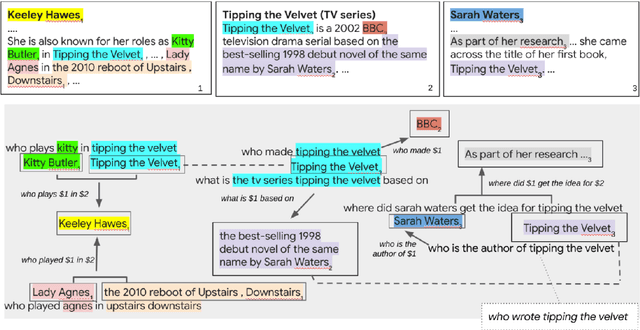
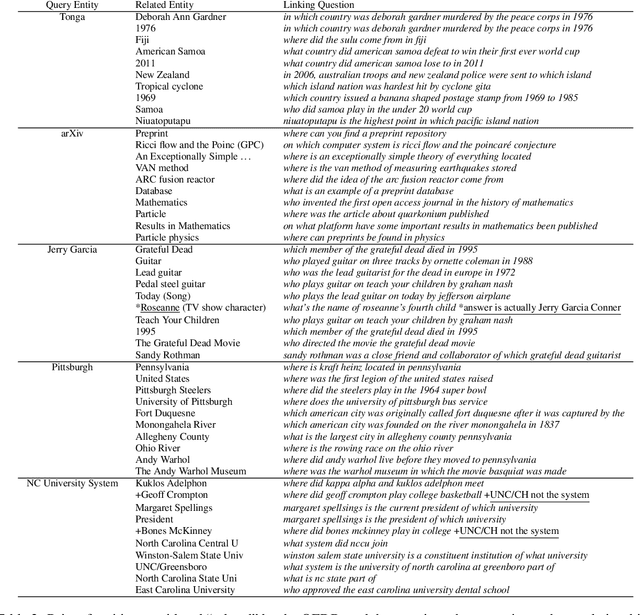
In this position paper, we propose a new approach to generating a type of knowledge base (KB) from text, based on question generation and entity linking. We argue that the proposed type of KB has many of the key advantages of a traditional symbolic KB: in particular, it consists of small modular components, which can be combined compositionally to answer complex queries, including relational queries and queries involving "multi-hop" inferences. However, unlike a traditional KB, this information store is well-aligned with common user information needs.
Faithful to the Document or to the World? Mitigating Hallucinations via Entity-linked Knowledge in Abstractive Summarization
Apr 28, 2022



Despite recent advances in abstractive summarization, current summarization systems still suffer from content hallucinations where models generate text that is either irrelevant or contradictory to the source document. However, prior work has been predicated on the assumption that any generated facts not appearing explicitly in the source are undesired hallucinations. Methods have been proposed to address this scenario by ultimately improving `faithfulness' to the source document, but in reality, there is a large portion of entities in the gold reference targets that are not directly in the source. In this work, we show that these entities are not aberrations, but they instead require utilizing external world knowledge to infer reasoning paths from entities in the source. We show that by utilizing an external knowledge base, we can improve the faithfulness of summaries without simply making them more extractive, and additionally, we show that external knowledge bases linked from the source can benefit the factuality of generated summaries.