 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM Planning Capabilities through Intrinsic Self-Critique
Dec 30, 2025We demonstrate an approach for LLMs to critique their \emph{own} answers with the goal of enhancing their performance that leads to significant improvements over established planning benchmarks. Despite the findings of earlier research that has cast doubt on the effectiveness of LLMs leveraging self critique methods, we show significant performance gains on planning datasets in the Blocksworld domain through intrinsic self-critique, without external source such as a verifier. We also demonstrate similar improvements on Logistics and Mini-grid datasets, exceeding strong baseline accuracies. We employ a few-shot learning technique and progressively extend it to a many-shot approach as our base method and demonstrate that it is possible to gain substantial improvement on top of this already competitive approach by employing an iterative process for correction and refinement. We illustrate how self-critique can significantly boost planning performance. Our empirical results present new state-of-the-art on the class of models considered, namely LLM model checkpoints from October 2024. Our primary focus lies on the method itself, demonstrating intrinsic self-improvement capabilities that are applicable regardless of the specific model version, and we believe that applying our method to more complex search techniques and more capable models will lead to even better performance.
Improving Large Language Model Planning with Action Sequence Similarity
May 02, 2025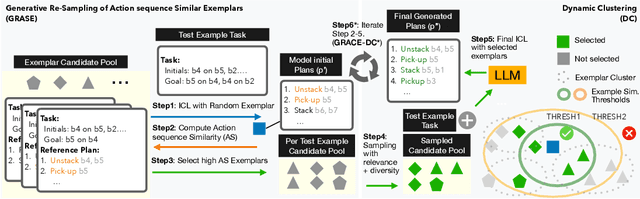

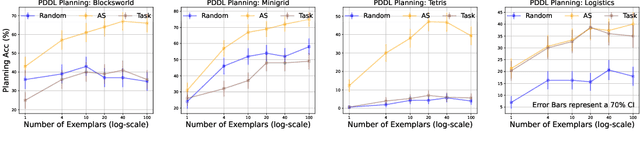

Planning is essential for artificial intelligence systems to look ahead and proactively determine a course of actions to reach objectives in the virtual and real world. Recent work on large language models (LLMs) sheds light on their planning capability in various tasks. However, it remains unclear what signals in the context influence the model performance. In this work, we explore how to improve the model planning capability through in-context learning (ICL), specifically, what signals can help select the exemplars. Through extensive experiments, we observe that commonly used problem similarity may result in false positives with drastically different plans, which can mislead the model. In response, we propose to sample and filter exemplars leveraging plan side action sequence similarity (AS). We propose GRASE-DC: a two-stage pipeline that first re-samples high AS exemplars and then curates the selected exemplars with dynamic clustering on AS to achieve a balance of relevance and diversity. Our experimental result confirms that GRASE-DC achieves significant performance improvement on various planning tasks (up to ~11-40 point absolute accuracy improvement with 27.3% fewer exemplars needed on average). With GRASE-DC* + VAL, where we iteratively apply GRASE-DC with a validator, we are able to even boost the performance by 18.9% more. Extensive analysis validates the consistent performance improvement of GRASE-DC with various backbone LLMs and on both classical planning and natural language planning benchmarks. GRASE-DC can further boost the planning accuracy by ~24 absolute points on harder problems using simpler problems as exemplars over a random baseline. This demonstrates its ability to generalize to out-of-distribution problems.
* 25 pages, 11 figures
Training Language Models on the Knowledge Graph: Insights on Hallucinations and Their Detectability
Aug 14, 2024



While many capabilities of language models (LMs) improve with increased training budget, the influence of scale on hallucinations is not yet fully understood. Hallucinations come in many forms, and there is no universally accepted definition. We thus focus on studying only those hallucinations where a correct answer appears verbatim in the training set. To fully control the training data content, we construct a knowledge graph (KG)-based dataset, and use it to train a set of increasingly large LMs. We find that for a fixed dataset, larger and longer-trained LMs hallucinate less. However, hallucinating on $\leq5$% of the training data requires an order of magnitude larger model, and thus an order of magnitude more compute, than Hoffmann et al. (2022) reported was optimal. Given this costliness, we study how hallucination detectors depend on scale. While we see detector size improves performance on fixed LM's outputs, we find an inverse relationship between the scale of the LM and the detectability of its hallucinations.
Exploring and Benchmarking the Planning Capabilities of Large Language Models
Jun 18, 2024



We seek to elevate the planning capabilities of Large Language Models (LLMs)investigating four main directions. First, we construct a comprehensive benchmark suite encompassing both classical planning domains and natural language scenarios. This suite includes algorithms to generate instances with varying levels of difficulty, allowing for rigorous and systematic evaluation of LLM performance. Second, we investigate the use of in-context learning (ICL) to enhance LLM planning, exploring the direct relationship between increased context length and improved planning performance. Third, we demonstrate the positive impact of fine-tuning LLMs on optimal planning paths, as well as the effectiveness of incorporating model-driven search procedures. Finally, we investigate the performance of the proposed methods in out-of-distribution scenarios, assessing the ability to generalize to novel and unseen planning challenges.
Long-Span Question-Answering: Automatic Question Generation and QA-System Ranking via Side-by-Side Evaluation
May 31, 2024



We explore the use of long-context capabilities in large language models to create synthetic reading comprehension data from entire books. Previous efforts to construct such datasets relied on crowd-sourcing, but the emergence of transformers with a context size of 1 million or more tokens now enables entirely automatic approaches. Our objective is to test the capabilities of LLMs to analyze, understand, and reason over problems that require a detailed comprehension of long spans of text, such as questions involving character arcs, broader themes, or the consequences of early actions later in the story. We propose a holistic pipeline for automatic data generation including question generation, answering, and model scoring using an ``Evaluator''. We find that a relative approach, comparing answers between models in a pairwise fashion and ranking with a Bradley-Terry model, provides a more consistent and differentiating scoring mechanism than an absolute scorer that rates answers individually. We also show that LLMs from different model families produce moderate agreement in their ratings. We ground our approach using the manually curated NarrativeQA dataset, where our evaluator shows excellent agreement with human judgement and even finds errors in the dataset. Using our automatic evaluation approach, we show that using an entire book as context produces superior reading comprehension performance compared to baseline no-context (parametric knowledge only) and retrieval-based approaches.
Many-Shot In-Context Learning
Apr 17, 2024



Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases and can learn high-dimensional functions with numerical inputs. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains
Feb 02, 2024
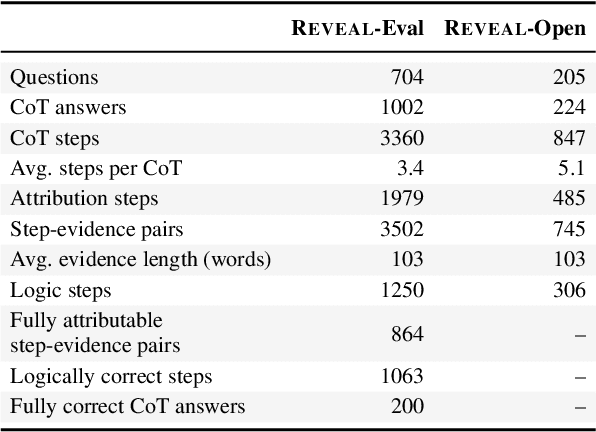
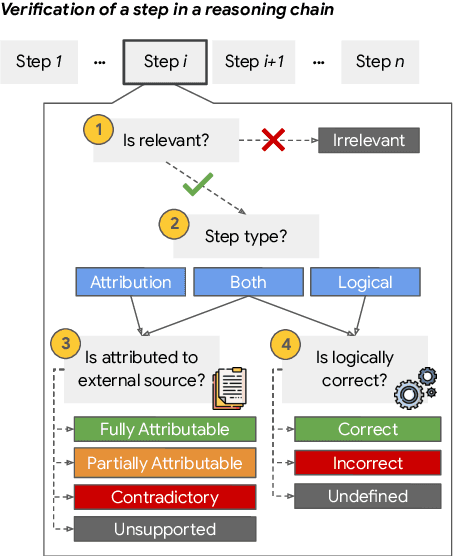
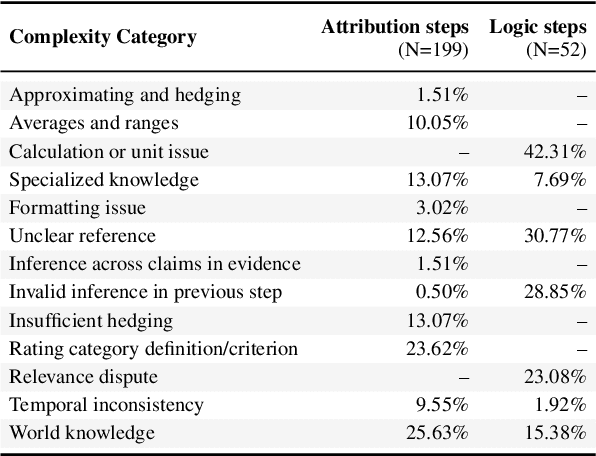
Prompting language models to provide step-by-step answers (e.g., "Chain-of-Thought") is the prominent approach for complex reasoning tasks, where more accurate reasoning chains typically improve downstream task performance. Recent literature discusses automatic methods to verify reasoning steps to evaluate and improve their correctness. However, no fine-grained step-level datasets are available to enable thorough evaluation of such verification methods, hindering progress in this direction. We introduce Reveal: Reasoning Verification Evaluation, a new dataset to benchmark automatic verifiers of complex Chain-of-Thought reasoning in open-domain question answering settings. Reveal includes comprehensive labels for the relevance, attribution to evidence passages, and logical correctness of each reasoning step in a language model's answer, across a wide variety of datasets and state-of-the-art language models.
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
Dec 22, 2023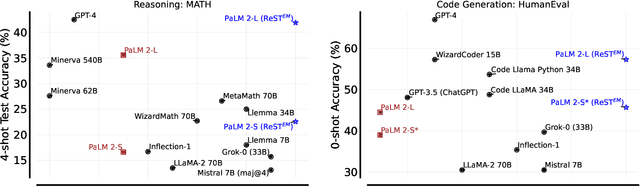
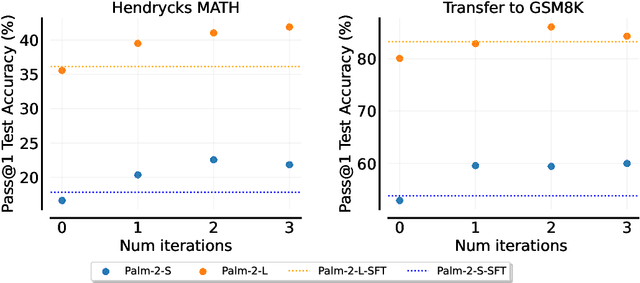
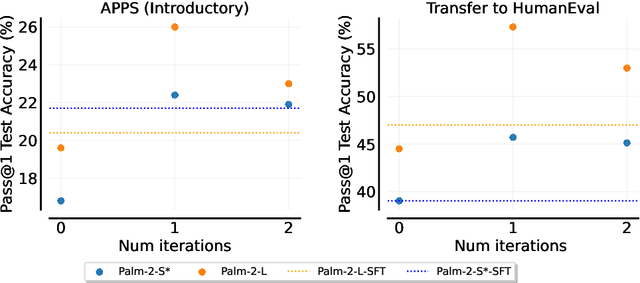
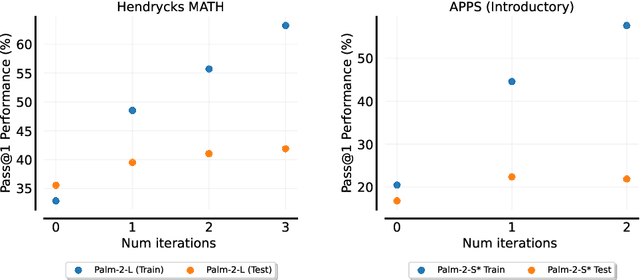
Fine-tuning language models~(LMs) on human-generated data remains a prevalent practice. However, the performance of such models is often limited by the quantity and diversity of high-quality human data. In this paper, we explore whether we can go beyond human data on tasks where we have access to scalar feedback, for example, on math problems where one can verify correctness. To do so, we investigate a simple self-training method based on expectation-maximization, which we call ReST$^{EM}$, where we (1) generate samples from the model and filter them using binary feedback, (2) fine-tune the model on these samples, and (3) repeat this process a few times. Testing on advanced MATH reasoning and APPS coding benchmarks using PaLM-2 models, we find that ReST$^{EM}$ scales favorably with model size and significantly surpasses fine-tuning only on human data. Overall, our findings suggest self-training with feedback can substantially reduce dependence on human-generated data.
Frontier Language Models are not Robust to Adversarial Arithmetic, or "What do I need to say so you agree 2+2=5?
Nov 15, 2023



We introduce and study the problem of adversarial arithmetic, which provides a simple yet challenging testbed for language model alignment. This problem is comprised of arithmetic questions posed in natural language, with an arbitrary adversarial string inserted before the question is complete. Even in the simple setting of 1-digit addition problems, it is easy to find adversarial prompts that make all tested models (including PaLM2, GPT4, Claude2) misbehave, and even to steer models to a particular wrong answer. We additionally provide a simple algorithm for finding successful attacks by querying those same models, which we name "prompt inversion rejection sampling" (PIRS). We finally show that models can be partially hardened against these attacks via reinforcement learning and via agentic constitutional loops. However, we were not able to make a language model fully robust against adversarial arithmetic attacks.