 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
May 28, 2026We demonstrate that sparse autoencoders can extract interpretable features from Claude 3 Sonnet, a production-scale language model, addressing the open question of whether dictionary learning methods scale beyond small transformers. We trained sparse autoencoders with up to 34 million features on the model's middle layer residual stream, using scaling laws to guide hyperparameter selection. The resulting features are multilingual and multimodal (generalizing to images despite text-only training), respond to both concrete instances and abstract discussions of concepts, and can be used to steer model behavior in ways consistent with their interpretations. We find features corresponding to famous entities and locations, as well as more abstract concepts like sarcasm or errors in code. We also identify features relevant to ways in which language models might cause harm--including features representing deception, power-seeking, sycophancy, and bias--and show that these causally influence model outputs when manipulated. Additionally, we conduct analyses of feature interpretability, geometry, and computational function. However, significant limitations remain: our suite of features is incomplete, and we lack rigorous methods for evaluating whether our features faithfully capture model computations.
Learned Neural Physics Simulation for Articulated 3D Human Pose Reconstruction
Oct 15, 2024We propose a novel neural network approach, LARP (Learned Articulated Rigid body Physics), to model the dynamics of articulated human motion with contact. Our goal is to develop a faster and more convenient methodological alternative to traditional physics simulators for use in computer vision tasks such as human motion reconstruction from video. To that end we introduce a training procedure and model components that support the construction of a recurrent neural architecture to accurately simulate articulated rigid body dynamics. Our neural architecture supports features typically found in traditional physics simulators, such as modeling of joint motors, variable dimensions of body parts, contact between body parts and objects, and is an order of magnitude faster than traditional systems when multiple simulations are run in parallel. To demonstrate the value of LARP we use it as a drop-in replacement for a state of the art classical non-differentiable simulator in an existing video-based reconstruction framework and show comparative or better 3D human pose reconstruction accuracy.
Training Language Models on the Knowledge Graph: Insights on Hallucinations and Their Detectability
Aug 14, 2024



While many capabilities of language models (LMs) improve with increased training budget, the influence of scale on hallucinations is not yet fully understood. Hallucinations come in many forms, and there is no universally accepted definition. We thus focus on studying only those hallucinations where a correct answer appears verbatim in the training set. To fully control the training data content, we construct a knowledge graph (KG)-based dataset, and use it to train a set of increasingly large LMs. We find that for a fixed dataset, larger and longer-trained LMs hallucinate less. However, hallucinating on $\leq5$% of the training data requires an order of magnitude larger model, and thus an order of magnitude more compute, than Hoffmann et al. (2022) reported was optimal. Given this costliness, we study how hallucination detectors depend on scale. While we see detector size improves performance on fixed LM's outputs, we find an inverse relationship between the scale of the LM and the detectability of its hallucinations.
Frontier Language Models are not Robust to Adversarial Arithmetic, or "What do I need to say so you agree 2+2=5?
Nov 15, 2023



We introduce and study the problem of adversarial arithmetic, which provides a simple yet challenging testbed for language model alignment. This problem is comprised of arithmetic questions posed in natural language, with an arbitrary adversarial string inserted before the question is complete. Even in the simple setting of 1-digit addition problems, it is easy to find adversarial prompts that make all tested models (including PaLM2, GPT4, Claude2) misbehave, and even to steer models to a particular wrong answer. We additionally provide a simple algorithm for finding successful attacks by querying those same models, which we name "prompt inversion rejection sampling" (PIRS). We finally show that models can be partially hardened against these attacks via reinforcement learning and via agentic constitutional loops. However, we were not able to make a language model fully robust against adversarial arithmetic attacks.
Improving Large Language Model Fine-tuning for Solving Math Problems
Oct 16, 2023Despite their success in many natural language tasks, solving math problems remains a significant challenge for large language models (LLMs). A large gap exists between LLMs' pass-at-one and pass-at-N performance in solving math problems, suggesting LLMs might be close to finding correct solutions, motivating our exploration of fine-tuning methods to unlock LLMs' performance. Using the challenging MATH dataset, we investigate three fine-tuning strategies: (1) solution fine-tuning, where we fine-tune to generate a detailed solution for a given math problem; (2) solution-cluster re-ranking, where the LLM is fine-tuned as a solution verifier/evaluator to choose among generated candidate solution clusters; (3) multi-task sequential fine-tuning, which integrates both solution generation and evaluation tasks together efficiently to enhance the LLM performance. With these methods, we present a thorough empirical study on a series of PaLM 2 models and find: (1) The quality and style of the step-by-step solutions used for fine-tuning can make a significant impact on the model performance; (2) While solution re-ranking and majority voting are both effective for improving the model performance when used separately, they can also be used together for an even greater performance boost; (3) Multi-task fine-tuning that sequentially separates the solution generation and evaluation tasks can offer improved performance compared with the solution fine-tuning baseline. Guided by these insights, we design a fine-tuning recipe that yields approximately 58.8% accuracy on the MATH dataset with fine-tuned PaLM 2-L models, an 11.2% accuracy improvement over the few-shot performance of pre-trained PaLM 2-L model with majority voting.
Transformer-Based Learned Optimization
Dec 02, 2022



In this paper, we propose a new approach to learned optimization. As common in the literature, we represent the computation of the update step of the optimizer with a neural network. The parameters of the optimizer are then learned on a set of training optimization tasks, in order to perform minimisation efficiently. Our main innovation is to propose a new neural network architecture for the learned optimizer inspired by the classic BFGS algorithm. As in BFGS, we estimate a preconditioning matrix as a sum of rank-one updates but use a transformer-based neural network to predict these updates jointly with the step length and direction. In contrast to several recent learned optimization approaches, our formulation allows for conditioning across different dimensions of the parameter space of the target problem while remaining applicable to optimization tasks of variable dimensionality without retraining. We demonstrate the advantages of our approach on a benchmark composed of objective functions traditionally used for evaluation of optimization algorithms, as well as on the real world-task of physics-based reconstruction of articulated 3D human motion.
VeLO: Training Versatile Learned Optimizers by Scaling Up
Nov 17, 2022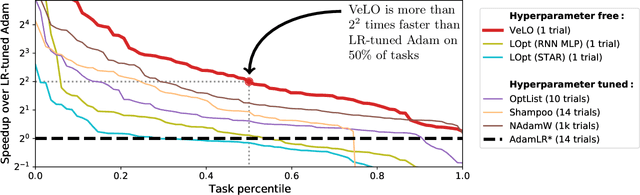
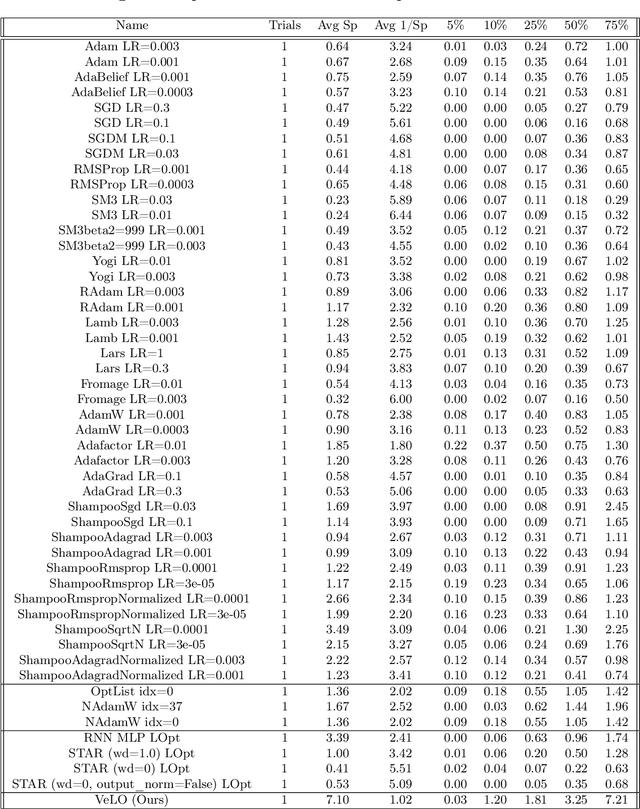
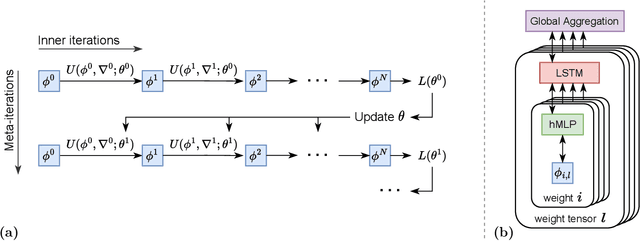
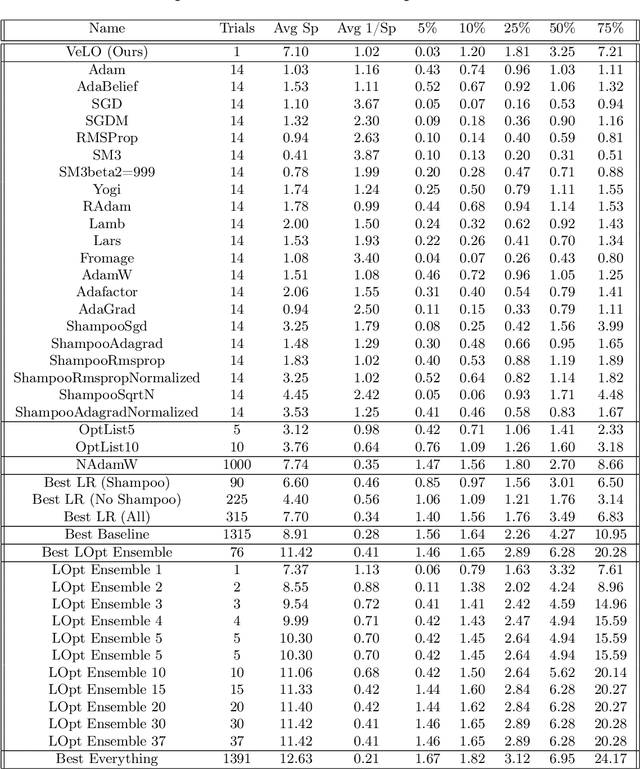
While deep learning models have replaced hand-designed features across many domains, these models are still trained with hand-designed optimizers. In this work, we leverage the same scaling approach behind the success of deep learning to learn versatile optimizers. We train an optimizer for deep learning which is itself a small neural network that ingests gradients and outputs parameter updates. Meta-trained with approximately four thousand TPU-months of compute on a wide variety of optimization tasks, our optimizer not only exhibits compelling performance, but optimizes in interesting and unexpected ways. It requires no hyperparameter tuning, instead automatically adapting to the specifics of the problem being optimized. We open source our learned optimizer, meta-training code, the associated train and test data, and an extensive optimizer benchmark suite with baselines at velo-code.github.io.
Allowing Safe Contact in Robotic Goal-Reaching: Planning and Tracking in Operational and Null Spaces
Oct 31, 2022



In recent years, impressive results have been achieved in robotic manipulation. While many efforts focus on generating collision-free reference signals, few allow safe contact between the robot bodies and the environment. However, in human's daily manipulation, contact between arms and obstacles is prevalent and even necessary. This paper investigates the benefit of allowing safe contact during robotic manipulation and advocates generating and tracking compliance reference signals in both operational and null spaces. In addition, to optimize the collision-allowed trajectories, we present a hybrid solver that integrates sampling- and gradient-based approaches. We evaluate the proposed method on a goal-reaching task in five simulated and real-world environments with different collisional conditions. We show that allowing safe contact improves goal-reaching efficiency and provides feasible solutions in highly collisional scenarios where collision-free constraints cannot be enforced. Moreover, we demonstrate that planning in null space, in addition to operational space, improves trajectory safety.
Practical tradeoffs between memory, compute, and performance in learned optimizers
Apr 01, 2022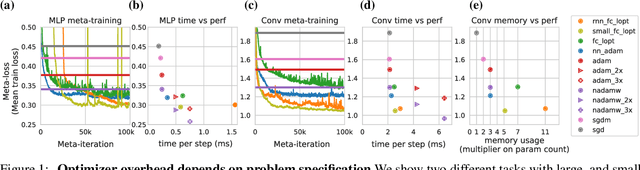

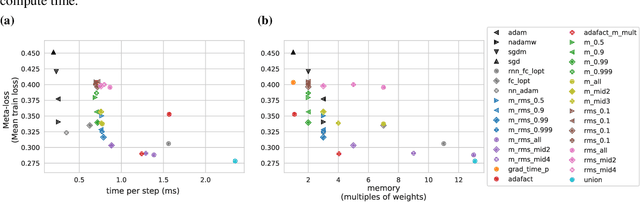
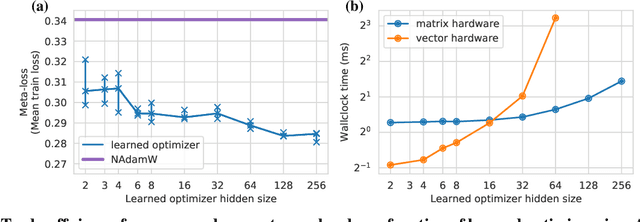
Optimization plays a costly and crucial role in developing machine learning systems. In learned optimizers, the few hyperparameters of commonly used hand-designed optimizers, e.g. Adam or SGD, are replaced with flexible parametric functions. The parameters of these functions are then optimized so that the resulting learned optimizer minimizes a target loss on a chosen class of models. Learned optimizers can both reduce the number of required training steps and improve the final test loss. However, they can be expensive to train, and once trained can be expensive to use due to computational and memory overhead for the optimizer itself. In this work, we identify and quantify the design features governing the memory, compute, and performance trade-offs for many learned and hand-designed optimizers. We further leverage our analysis to construct a learned optimizer that is both faster and more memory efficient than previous work.
Gradients are Not All You Need
Nov 10, 2021
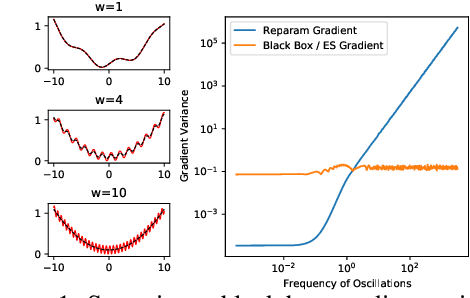
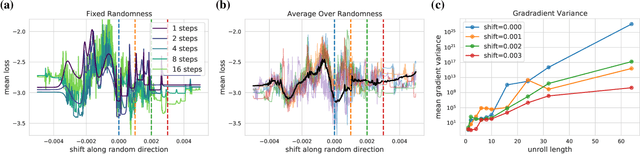
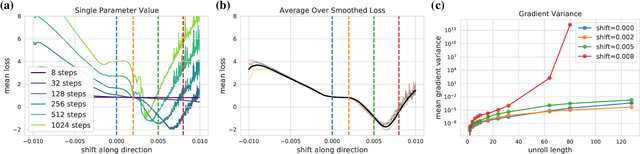
Differentiable programming techniques are widely used in the community and are responsible for the machine learning renaissance of the past several decades. While these methods are powerful, they have limits. In this short report, we discuss a common chaos based failure mode which appears in a variety of differentiable circumstances, ranging from recurrent neural networks and numerical physics simulation to training learned optimizers. We trace this failure to the spectrum of the Jacobian of the system under study, and provide criteria for when a practitioner might expect this failure to spoil their differentiation based optimization algorithms.