 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Multi-Decadal Forest Disturbances: A Spatio-Temporal Transformer Approach
Jun 05, 2026Accurate monitoring of forest disturbances is essential for understanding carbon dynamics and land management, yet traditional approaches typically rely on pixel-wise analysis of satellite time-series, ignoring spatial context. We present a deep learning framework that maps 38 years (1984-2022) of forest disturbance across the contiguous United States by modeling temporal trajectories and spatial neighborhoods simultaneously. By leveraging a vision transformer architecture, our approach effectively filters noise from weak supervision signals to produce spatially coherent disturbance maps. We perform exhaustive evaluations across multiple satellites (Landsat, Sentinel-1, Sentinel-2) and temporal windows (38 years and the more recent 6 years), validating performance against a novel, manually annotated validation dataset (n=300) and independent fire perimeter dataset (n=706). The results highlight the complexity of the task: while our spatio-temporal model demonstrates high precision (up to 98.2% for +-1 year detection on MTBS and up to 71.3% on the CONUS validation datasets, with F1-scores up to 75.8% and 47.3%, respectively) and effectively reduces spatial artifacts, it exhibits performance trade-offs across different disturbance regimes compared to pixel-wise baselines. Our method offers a promising foundation for consistent forest monitoring.
Tree crop mapping of South America reveals links to deforestation and conservation
Feb 19, 2026Monitoring tree crop expansion is vital for zero-deforestation policies like the European Union's Regulation on Deforestation-free Products (EUDR). However, these efforts are hindered by a lack of highresolution data distinguishing diverse agricultural systems from forests. Here, we present the first 10m-resolution tree crop map for South America, generated using a multi-modal, spatio-temporal deep learning model trained on Sentinel-1 and Sentinel-2 satellite imagery time series. The map identifies approximately 11 million hectares of tree crops, 23% of which is linked to 2000-2020 forest cover loss. Critically, our analysis reveals that existing regulatory maps supporting the EUDR often classify established agriculture, particularly smallholder agroforestry, as "forest". This discrepancy risks false deforestation alerts and unfair penalties for small-scale farmers. Our work mitigates this risk by providing a high-resolution baseline, supporting conservation policies that are effective, inclusive, and equitable.
vec2text with Round-Trip Translations
Sep 14, 2022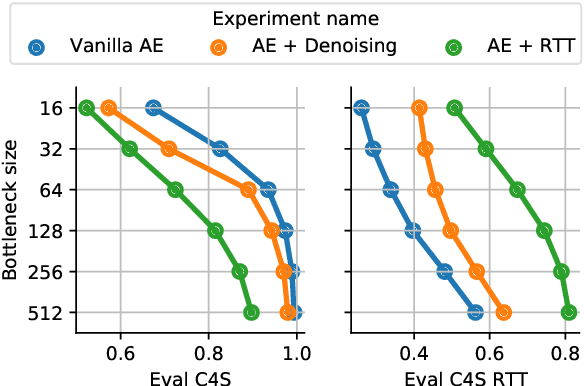

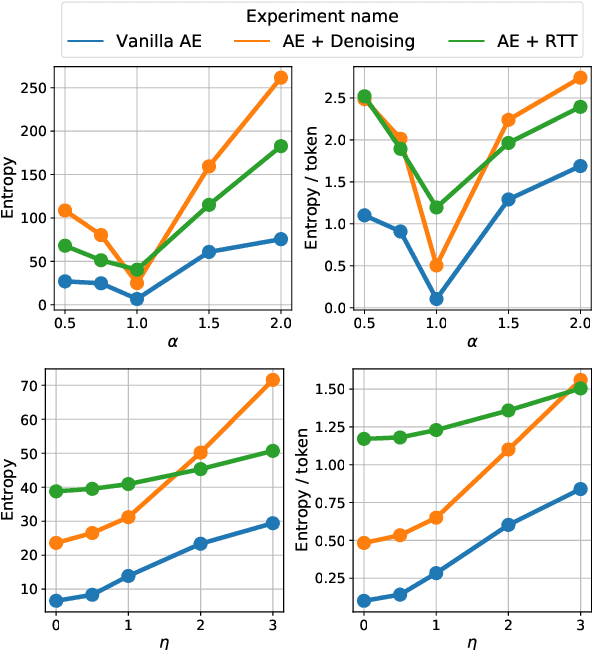

We investigate models that can generate arbitrary natural language text (e.g. all English sentences) from a bounded, convex and well-behaved control space. We call them universal vec2text models. Such models would allow making semantic decisions in the vector space (e.g. via reinforcement learning) while the natural language generation is handled by the vec2text model. We propose four desired properties: universality, diversity, fluency, and semantic structure, that such vec2text models should possess and we provide quantitative and qualitative methods to assess them. We implement a vec2text model by adding a bottleneck to a 250M parameters Transformer model and training it with an auto-encoding objective on 400M sentences (10B tokens) extracted from a massive web corpus. We propose a simple data augmentation technique based on round-trip translations and show in extensive experiments that the resulting vec2text model surprisingly leads to vector spaces that fulfill our four desired properties and that this model strongly outperforms both standard and denoising auto-encoders.
Continuous Control with Action Quantization from Demonstrations
Oct 19, 2021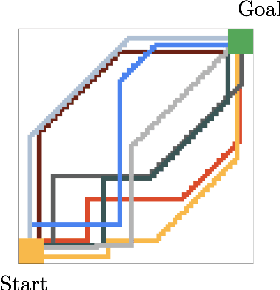
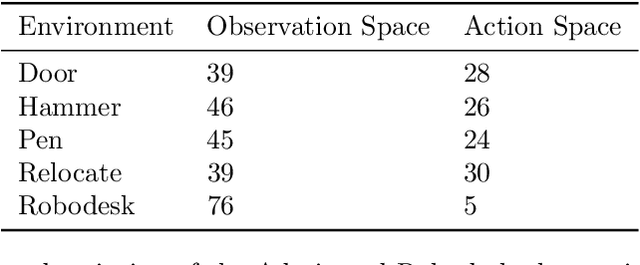

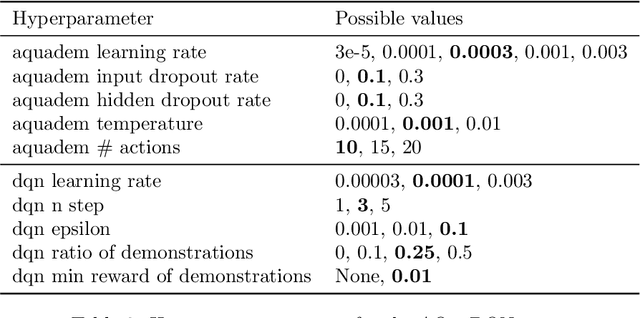
In Reinforcement Learning (RL), discrete actions, as opposed to continuous actions, result in less complex exploration problems and the immediate computation of the maximum of the action-value function which is central to dynamic programming-based methods. In this paper, we propose a novel method: Action Quantization from Demonstrations (AQuaDem) to learn a discretization of continuous action spaces by leveraging the priors of demonstrations. This dramatically reduces the exploration problem, since the actions faced by the agent not only are in a finite number but also are plausible in light of the demonstrator's behavior. By discretizing the action space we can apply any discrete action deep RL algorithm to the continuous control problem. We evaluate the proposed method on three different setups: RL with demonstrations, RL with play data --demonstrations of a human playing in an environment but not solving any specific task-- and Imitation Learning. For all three setups, we only consider human data, which is more challenging than synthetic data. We found that AQuaDem consistently outperforms state-of-the-art continuous control methods, both in terms of performance and sample efficiency. We provide visualizations and videos in the paper's website: https://google-research.github.io/aquadem.
Braxlines: Fast and Interactive Toolkit for RL-driven Behavior Engineering beyond Reward Maximization
Oct 10, 2021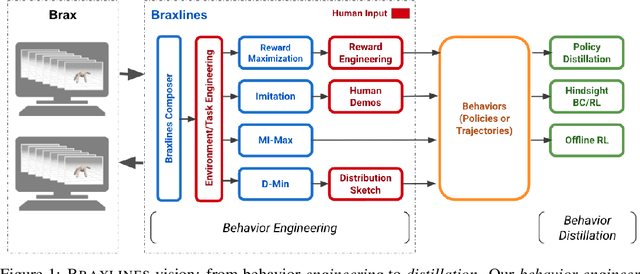



The goal of continuous control is to synthesize desired behaviors. In reinforcement learning (RL)-driven approaches, this is often accomplished through careful task reward engineering for efficient exploration and running an off-the-shelf RL algorithm. While reward maximization is at the core of RL, reward engineering is not the only -- sometimes nor the easiest -- way for specifying complex behaviors. In this paper, we introduce \braxlines, a toolkit for fast and interactive RL-driven behavior generation beyond simple reward maximization that includes Composer, a programmatic API for generating continuous control environments, and set of stable and well-tested baselines for two families of algorithms -- mutual information maximization (MiMax) and divergence minimization (DMin) -- supporting unsupervised skill learning and distribution sketching as other modes of behavior specification. In addition, we discuss how to standardize metrics for evaluating these algorithms, which can no longer rely on simple reward maximization. Our implementations build on a hardware-accelerated Brax simulator in Jax with minimal modifications, enabling behavior synthesis within minutes of training. We hope Braxlines can serve as an interactive toolkit for rapid creation and testing of environments and behaviors, empowering explosions of future benchmark designs and new modes of RL-driven behavior generation and their algorithmic research.
Implicitly Regularized RL with Implicit Q-Values
Aug 16, 2021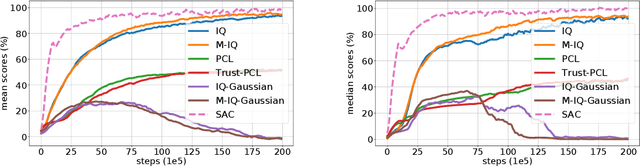
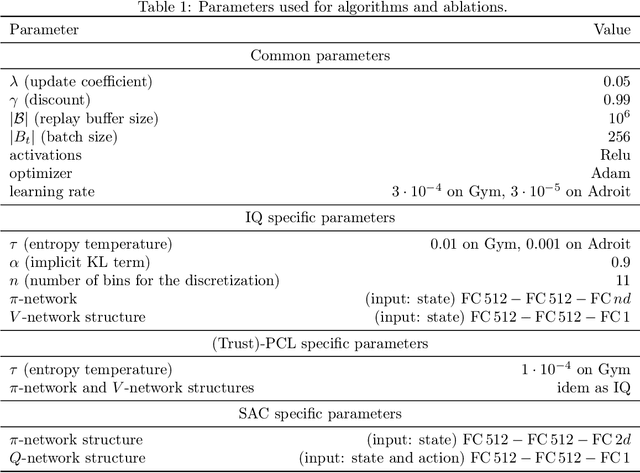
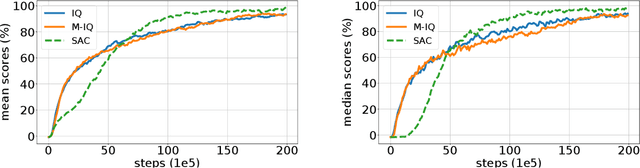

The $Q$-function is a central quantity in many Reinforcement Learning (RL) algorithms for which RL agents behave following a (soft)-greedy policy w.r.t. to $Q$. It is a powerful tool that allows action selection without a model of the environment and even without explicitly modeling the policy. Yet, this scheme can only be used in discrete action tasks, with small numbers of actions, as the softmax cannot be computed exactly otherwise. Especially the usage of function approximation, to deal with continuous action spaces in modern actor-critic architectures, intrinsically prevents the exact computation of a softmax. We propose to alleviate this issue by parametrizing the $Q$-function implicitly, as the sum of a log-policy and of a value function. We use the resulting parametrization to derive a practical off-policy deep RL algorithm, suitable for large action spaces, and that enforces the softmax relation between the policy and the $Q$-value. We provide a theoretical analysis of our algorithm: from an Approximate Dynamic Programming perspective, we show its equivalence to a regularized version of value iteration, accounting for both entropy and Kullback-Leibler regularization, and that enjoys beneficial error propagation results. We then evaluate our algorithm on classic control tasks, where its results compete with state-of-the-art methods.
Brax -- A Differentiable Physics Engine for Large Scale Rigid Body Simulation
Jun 24, 2021
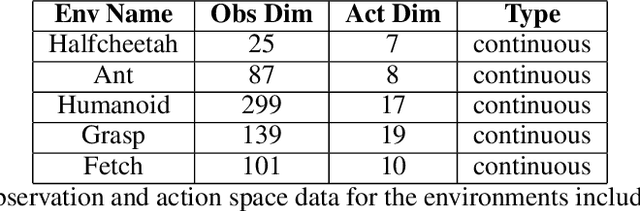
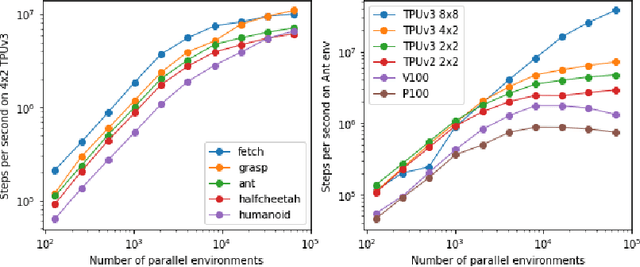
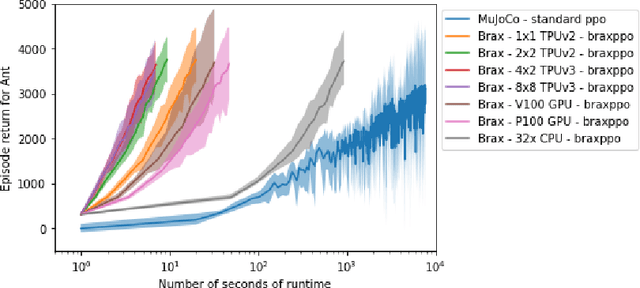
We present Brax, an open source library for rigid body simulation with a focus on performance and parallelism on accelerators, written in JAX. We present results on a suite of tasks inspired by the existing reinforcement learning literature, but remade in our engine. Additionally, we provide reimplementations of PPO, SAC, ES, and direct policy optimization in JAX that compile alongside our environments, allowing the learning algorithm and the environment processing to occur on the same device, and to scale seamlessly on accelerators. Finally, we include notebooks that facilitate training of performant policies on common OpenAI Gym MuJoCo-like tasks in minutes.
What Matters for Adversarial Imitation Learning?
Jun 01, 2021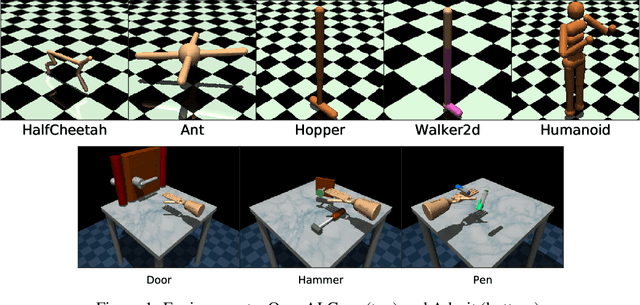


Adversarial imitation learning has become a popular framework for imitation in continuous control. Over the years, several variations of its components were proposed to enhance the performance of the learned policies as well as the sample complexity of the algorithm. In practice, these choices are rarely tested all together in rigorous empirical studies. It is therefore difficult to discuss and understand what choices, among the high-level algorithmic options as well as low-level implementation details, matter. To tackle this issue, we implement more than 50 of these choices in a generic adversarial imitation learning framework and investigate their impacts in a large-scale study (>500k trained agents) with both synthetic and human-generated demonstrations. While many of our findings confirm common practices, some of them are surprising or even contradict prior work. In particular, our results suggest that artificial demonstrations are not a good proxy for human data and that the very common practice of evaluating imitation algorithms only with synthetic demonstrations may lead to algorithms which perform poorly in the more realistic scenarios with human demonstrations.
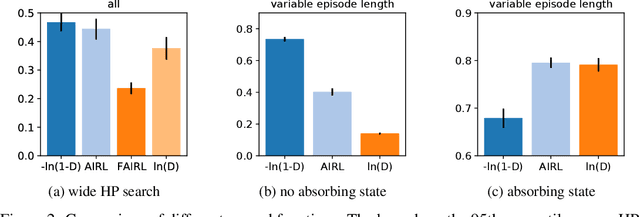
Hyperparameter Selection for Imitation Learning
May 25, 2021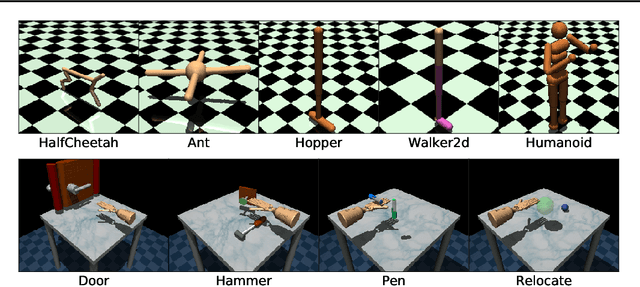
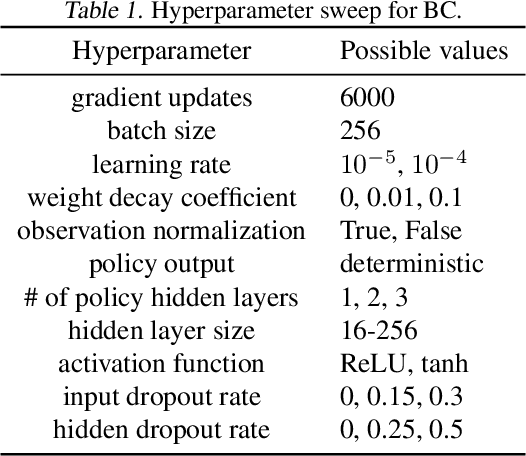
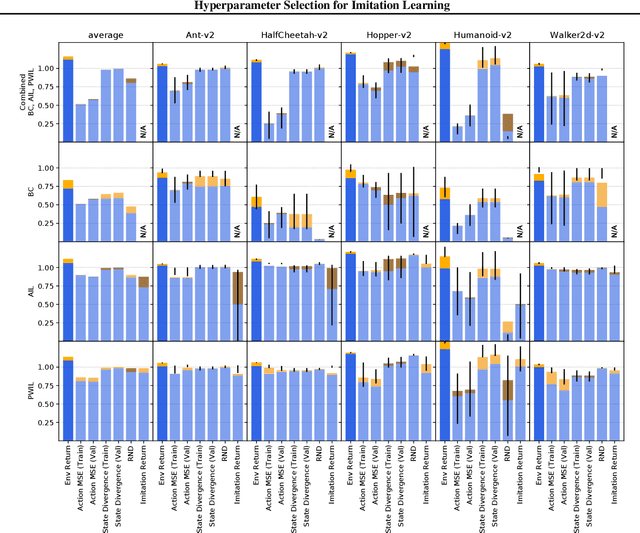
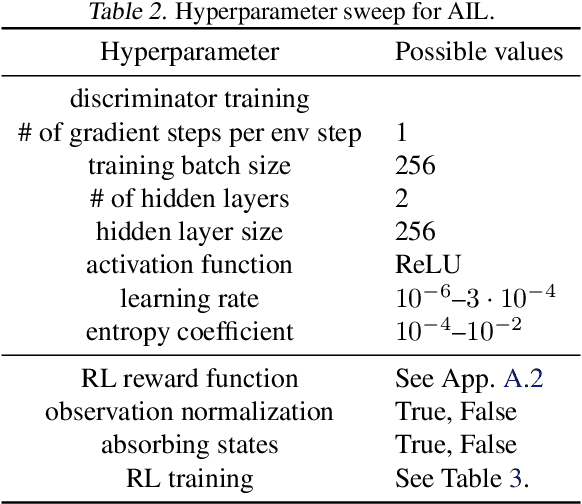
We address the issue of tuning hyperparameters (HPs) for imitation learning algorithms in the context of continuous-control, when the underlying reward function of the demonstrating expert cannot be observed at any time. The vast literature in imitation learning mostly considers this reward function to be available for HP selection, but this is not a realistic setting. Indeed, would this reward function be available, it could then directly be used for policy training and imitation would not be necessary. To tackle this mostly ignored problem, we propose a number of possible proxies to the external reward. We evaluate them in an extensive empirical study (more than 10'000 agents across 9 environments) and make practical recommendations for selecting HPs. Our results show that while imitation learning algorithms are sensitive to HP choices, it is often possible to select good enough HPs through a proxy to the reward function.
Agent-Centric Representations for Multi-Agent Reinforcement Learning
Apr 19, 2021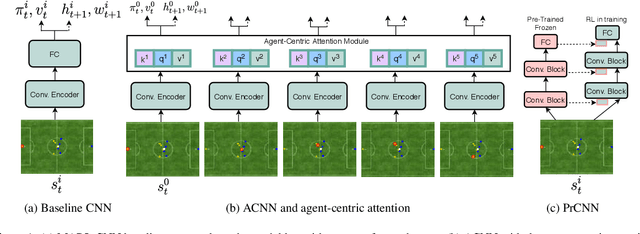

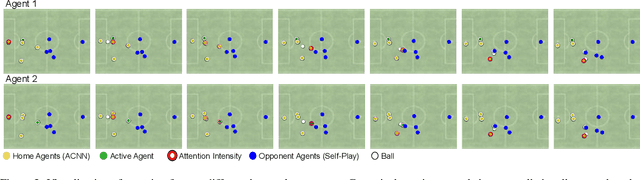

Object-centric representations have recently enabled significant progress in tackling relational reasoning tasks. By building a strong object-centric inductive bias into neural architectures, recent efforts have improved generalization and data efficiency of machine learning algorithms for these problems. One problem class involving relational reasoning that still remains under-explored is multi-agent reinforcement learning (MARL). Here we investigate whether object-centric representations are also beneficial in the fully cooperative MARL setting. Specifically, we study two ways of incorporating an agent-centric inductive bias into our RL algorithm: 1. Introducing an agent-centric attention module with explicit connections across agents 2. Adding an agent-centric unsupervised predictive objective (i.e. not using action labels), to be used as an auxiliary loss for MARL, or as the basis of a pre-training step. We evaluate these approaches on the Google Research Football environment as well as DeepMind Lab 2D. Empirically, agent-centric representation learning leads to the emergence of more complex cooperation strategies between agents as well as enhanced sample efficiency and generalization.