 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study
Jun 10, 2020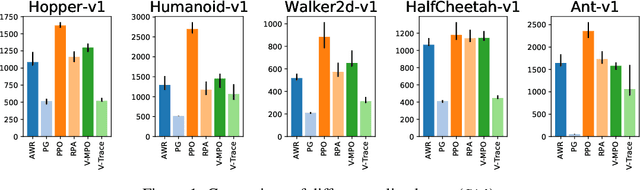

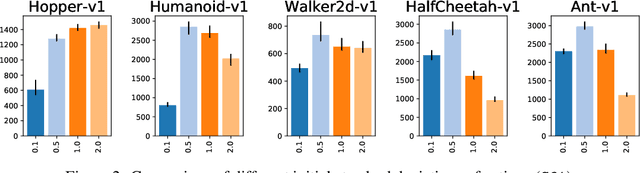

In recent years, on-policy reinforcement learning (RL) has been successfully applied to many different continuous control tasks. While RL algorithms are often conceptually simple, their state-of-the-art implementations take numerous low- and high-level design decisions that strongly affect the performance of the resulting agents. Those choices are usually not extensively discussed in the literature, leading to discrepancy between published descriptions of algorithms and their implementations. This makes it hard to attribute progress in RL and slows down overall progress [Engstrom'20]. As a step towards filling that gap, we implement >50 such ``choices'' in a unified on-policy RL framework, allowing us to investigate their impact in a large-scale empirical study. We train over 250'000 agents in five continuous control environments of different complexity and provide insights and practical recommendations for on-policy training of RL agents.
SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference
Oct 15, 2019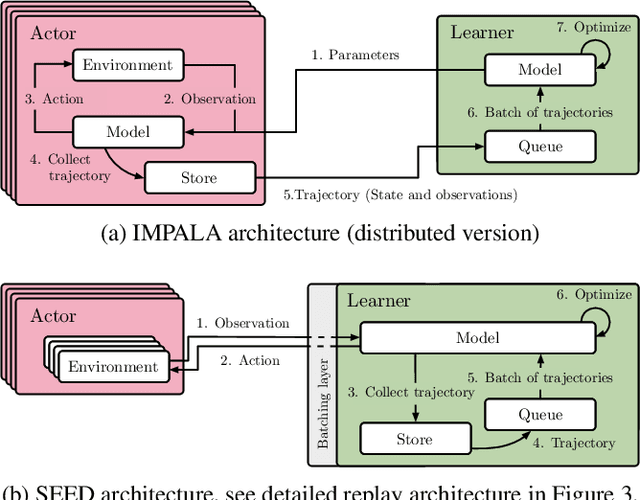
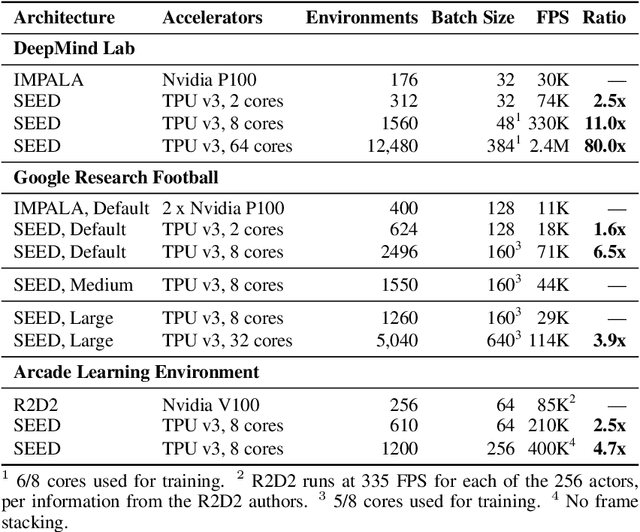
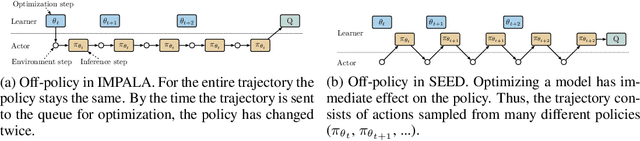
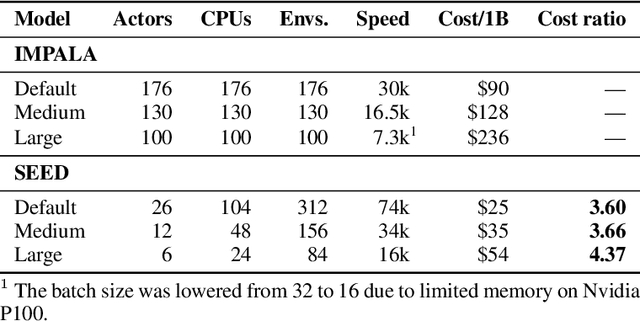
We present a modern scalable reinforcement learning agent called SEED (Scalable, Efficient Deep-RL). By effectively utilizing modern accelerators, we show that it is not only possible to train on millions of frames per second but also to lower the cost of experiments compared to current methods. We achieve this with a simple architecture that features centralized inference and an optimized communication layer. SEED adopts two state of the art distributed algorithms, IMPALA/V-trace (policy gradients) and R2D2 (Q-learning), and is evaluated on Atari-57, DeepMind Lab and Google Research Football. We improve the state of the art on Football and are able to reach state of the art on Atari-57 twice as fast in wall-time. For the scenarios we consider, a 40% to 80% cost reduction for running experiments is achieved. The implementation along with experiments is open-sourced so that results can be reproduced and novel ideas tried out.
The Visual Task Adaptation Benchmark
Oct 01, 2019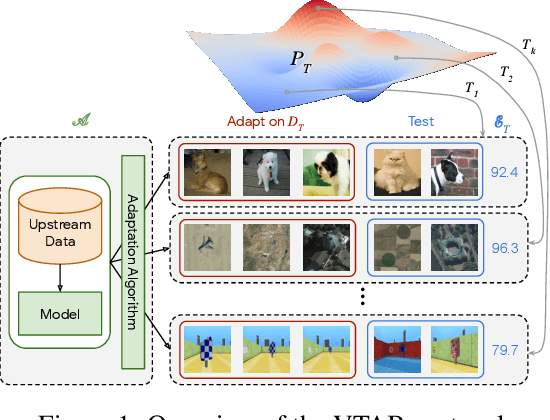
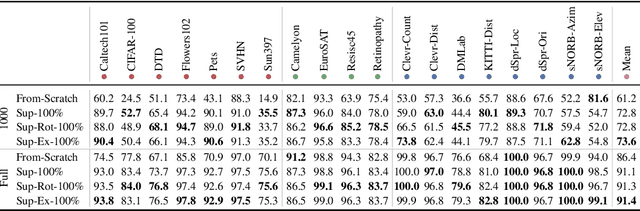
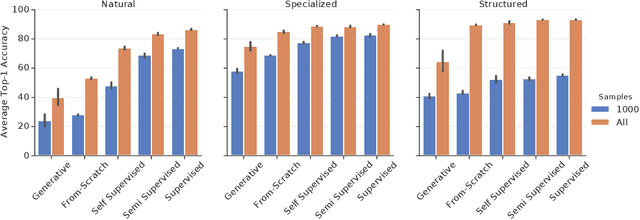
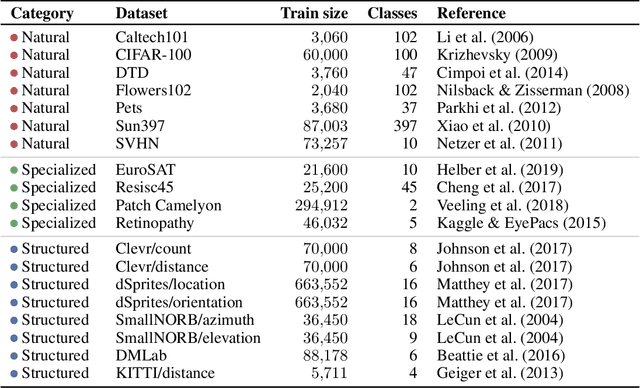
Representation learning promises to unlock deep learning for the long tail of vision tasks without expansive labelled datasets. Yet, the absence of a unified yardstick to evaluate general visual representations hinders progress. Many sub-fields promise representations, but each has different evaluation protocols that are either too constrained (linear classification), limited in scope (ImageNet, CIFAR, Pascal-VOC), or only loosely related to representation quality (generation). We present the Visual Task Adaptation Benchmark (VTAB): a diverse, realistic, and challenging benchmark to evaluate representations. VTAB embodies one principle: good representations adapt to unseen tasks with few examples. We run a large VTAB study of popular algorithms, answering questions like: How effective are ImageNet representation on non-standard datasets? Are generative models competitive? Is self-supervision useful if one already has labels?
Google Research Football: A Novel Reinforcement Learning Environment
Jul 25, 2019


Recent progress in the field of reinforcement learning has been accelerated by virtual learning environments such as video games, where novel algorithms and ideas can be quickly tested in a safe and reproducible manner. We introduce the Google Research Football Environment, a new reinforcement learning environment where agents are trained to play football in an advanced, physics-based 3D simulator. The resulting environment is challenging, easy to use and customize, and it is available under a permissive open-source license. In addition, it provides support for multiplayer and multi-agent experiments. We propose three full-game scenarios of varying difficulty with the Football Benchmarks and report baseline results for three commonly used reinforcement algorithms (IMPALA, PPO, and Ape-X DQN). We also provide a diverse set of simpler scenarios with the Football Academy and showcase several promising research directions.
Towards Accurate Generative Models of Video: A New Metric & Challenges
Dec 03, 2018



Recent advances in deep generative models have lead to remarkable progress in synthesizing high quality images. Following their successful application in image processing and representation learning, an important next step is to consider videos. Learning generative models of video is a much harder task, requiring a model to capture the temporal dynamics of a scene, in addition to the visual presentation of objects. Although recent attempts at formulating generative models of video have had some success, current progress is hampered by (1) the lack of qualitative metrics that consider visual quality, temporal coherence, and diversity of samples, and (2) the wide gap between purely synthetic video datasets and challenging real-world datasets in terms of complexity. To this extent we propose Fr\'echet Video Distance (FVD), a new metric for generative models of video based on FID, and StarCraft 2 Videos (SCV), a collection of progressively harder datasets that challenge the capabilities of the current iteration of generative models for video. We conduct a large-scale human study, which confirms that FVD correlates well with qualitative human judgment of generated videos, and provide initial benchmark results on SCV.
Are GANs Created Equal? A Large-Scale Study
Oct 29, 2018
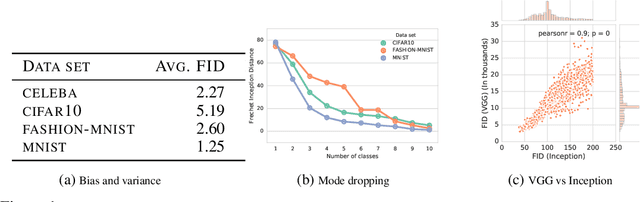
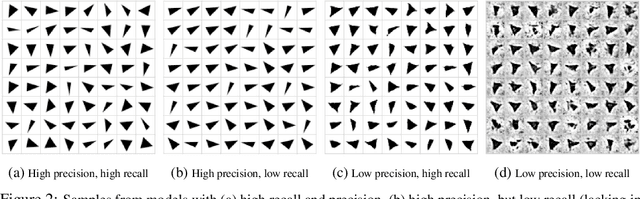
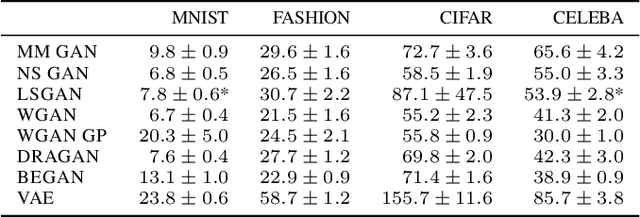
Generative adversarial networks (GAN) are a powerful subclass of generative models. Despite a very rich research activity leading to numerous interesting GAN algorithms, it is still very hard to assess which algorithm(s) perform better than others. We conduct a neutral, multi-faceted large-scale empirical study on state-of-the art models and evaluation measures. We find that most models can reach similar scores with enough hyperparameter optimization and random restarts. This suggests that improvements can arise from a higher computational budget and tuning more than fundamental algorithmic changes. To overcome some limitations of the current metrics, we also propose several data sets on which precision and recall can be computed. Our experimental results suggest that future GAN research should be based on more systematic and objective evaluation procedures. Finally, we did not find evidence that any of the tested algorithms consistently outperforms the non-saturating GAN introduced in \cite{goodfellow2014generative}.
The GAN Landscape: Losses, Architectures, Regularization, and Normalization
Oct 26, 2018



Generative adversarial networks (GANs) are a class of deep generative models which aim to learn a target distribution in an unsupervised fashion. While they were successfully applied to many problems, training a GAN is a notoriously challenging task and requires a significant amount of hyperparameter tuning, neural architecture engineering, and a non-trivial amount of "tricks". The success in many practical applications coupled with the lack of a measure to quantify the failure modes of GANs resulted in a plethora of proposed losses, regularization and normalization schemes, and neural architectures. In this work we take a sober view of the current state of GANs from a practical perspective. We reproduce the current state of the art and go beyond fairly exploring the GAN landscape. We discuss common pitfalls and reproducibility issues, open-source our code on Github, and provide pre-trained models on TensorFlow Hub.
MemGEN: Memory is All You Need
Mar 29, 2018



We propose a new learning paradigm called Deep Memory. It has the potential to completely revolutionize the Machine Learning field. Surprisingly, this paradigm has not been reinvented yet, unlike Deep Learning. At the core of this approach is the \textit{Learning By Heart} principle, well studied in primary schools all over the world. Inspired by poem recitation, or by $\pi$ decimal memorization, we propose a concrete algorithm that mimics human behavior. We implement this paradigm on the task of generative modeling, and apply to images, natural language and even the $\pi$ decimals as long as one can print them as text. The proposed algorithm even generated this paper, in a one-shot learning setting. In carefully designed experiments, we show that the generated samples are indistinguishable from the training examples, as measured by any statistical tests or metrics.