 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision
Feb 07, 2023We introduce SPEAR-TTS, a multi-speaker text-to-speech (TTS) system that can be trained with minimal supervision. By combining two types of discrete speech representations, we cast TTS as a composition of two sequence-to-sequence tasks: from text to high-level semantic tokens (akin to "reading") and from semantic tokens to low-level acoustic tokens ("speaking"). Decoupling these two tasks enables training of the "speaking" module using abundant audio-only data, and unlocks the highly efficient combination of pretraining and backtranslation to reduce the need for parallel data when training the "reading" component. To control the speaker identity, we adopt example prompting, which allows SPEAR-TTS to generalize to unseen speakers using only a short sample of 3 seconds, without any explicit speaker representation or speaker-id labels. Our experiments demonstrate that SPEAR-TTS achieves a character error rate that is competitive with state-of-the-art methods using only 15 minutes of parallel data, while matching ground-truth speech in terms of naturalness and acoustic quality, as measured in subjective tests.
AudioLM: a Language Modeling Approach to Audio Generation
Sep 07, 2022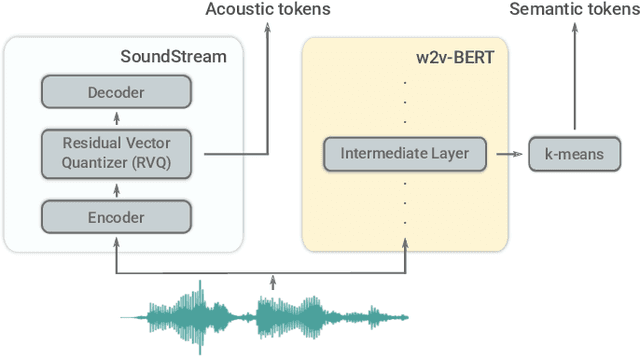

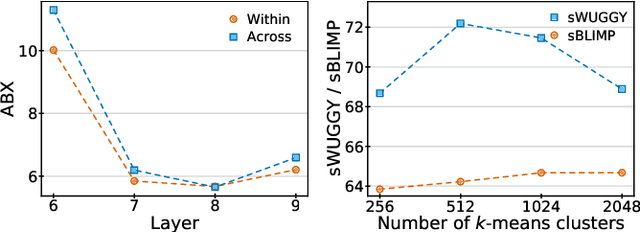

We introduce AudioLM, a framework for high-quality audio generation with long-term consistency. AudioLM maps the input audio to a sequence of discrete tokens and casts audio generation as a language modeling task in this representation space. We show how existing audio tokenizers provide different trade-offs between reconstruction quality and long-term structure, and we propose a hybrid tokenization scheme to achieve both objectives. Namely, we leverage the discretized activations of a masked language model pre-trained on audio to capture long-term structure and the discrete codes produced by a neural audio codec to achieve high-quality synthesis. By training on large corpora of raw audio waveforms, AudioLM learns to generate natural and coherent continuations given short prompts. When trained on speech, and without any transcript or annotation, AudioLM generates syntactically and semantically plausible speech continuations while also maintaining speaker identity and prosody for unseen speakers. Furthermore, we demonstrate how our approach extends beyond speech by generating coherent piano music continuations, despite being trained without any symbolic representation of music.
SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference
Oct 15, 2019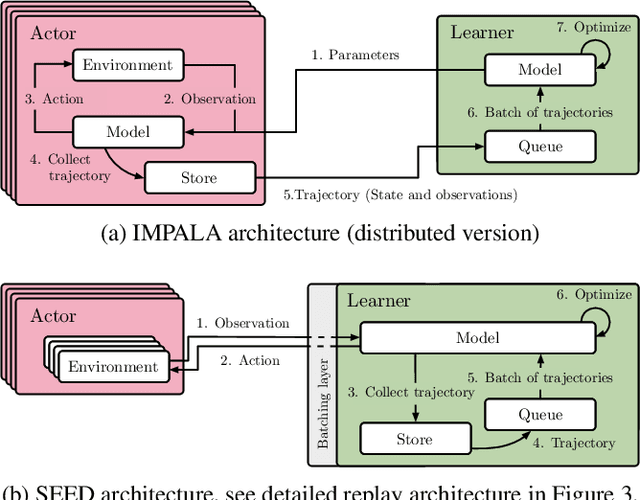
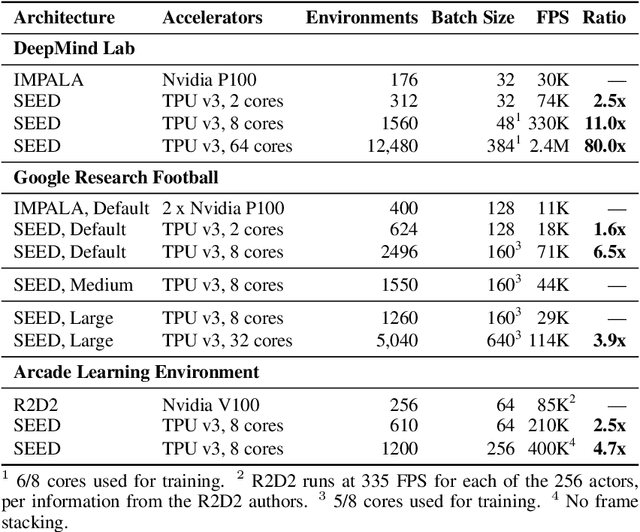
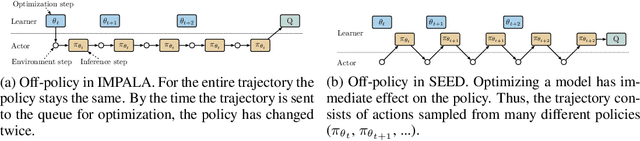
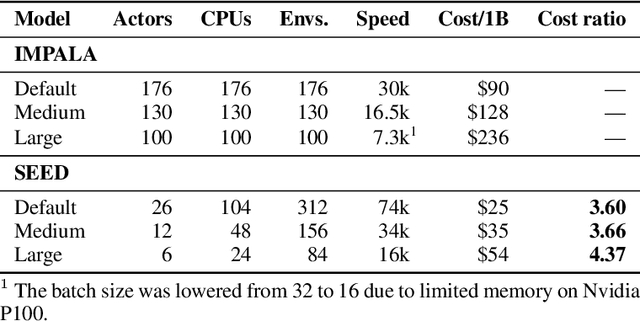
We present a modern scalable reinforcement learning agent called SEED (Scalable, Efficient Deep-RL). By effectively utilizing modern accelerators, we show that it is not only possible to train on millions of frames per second but also to lower the cost of experiments compared to current methods. We achieve this with a simple architecture that features centralized inference and an optimized communication layer. SEED adopts two state of the art distributed algorithms, IMPALA/V-trace (policy gradients) and R2D2 (Q-learning), and is evaluated on Atari-57, DeepMind Lab and Google Research Football. We improve the state of the art on Football and are able to reach state of the art on Atari-57 twice as fast in wall-time. For the scenarios we consider, a 40% to 80% cost reduction for running experiments is achieved. The implementation along with experiments is open-sourced so that results can be reproduced and novel ideas tried out.
Credit Assignment as a Proxy for Transfer in Reinforcement Learning
Jul 18, 2019

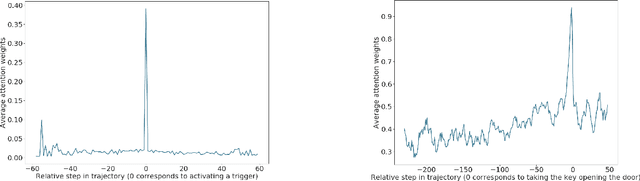
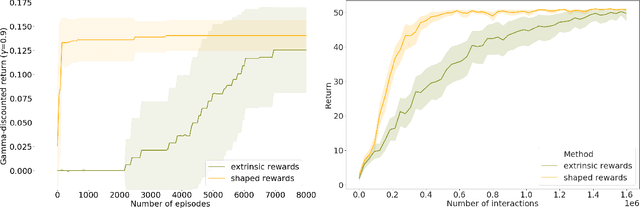
The ability to transfer representations to novel environments and tasks is a sensible requirement for general learning agents. Despite the apparent promises, transfer in Reinforcement Learning is still an open and under-exploited research area. In this paper, we suggest that credit assignment, regarded as a supervised learning task, could be used to accomplish transfer. Our contribution is twofold: we introduce a new credit assignment mechanism based on self-attention, and show that the learned credit can be transferred to in-domain and out-of-domain scenarios.
Episodic Curiosity through Reachability
Feb 22, 2019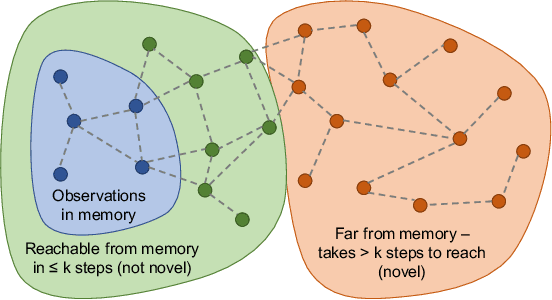

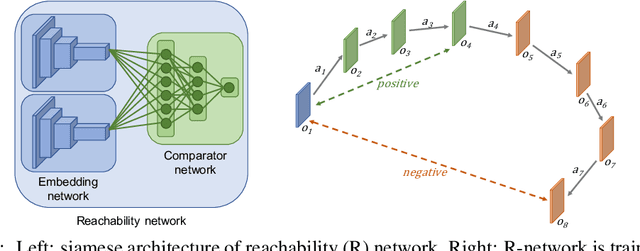
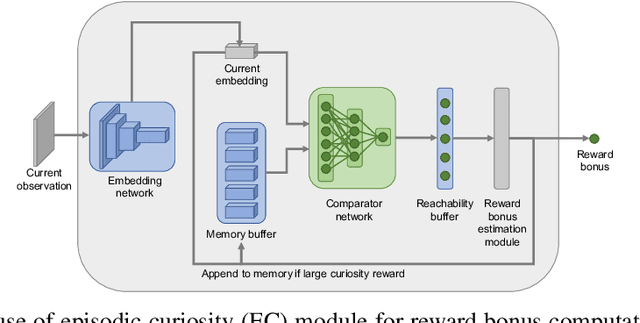
Rewards are sparse in the real world and most today's reinforcement learning algorithms struggle with such sparsity. One solution to this problem is to allow the agent to create rewards for itself - thus making rewards dense and more suitable for learning. In particular, inspired by curious behaviour in animals, observing something novel could be rewarded with a bonus. Such bonus is summed up with the real task reward - making it possible for RL algorithms to learn from the combined reward. We propose a new curiosity method which uses episodic memory to form the novelty bonus. To determine the bonus, the current observation is compared with the observations in memory. Crucially, the comparison is done based on how many environment steps it takes to reach the current observation from those in memory - which incorporates rich information about environment dynamics. This allows us to overcome the known "couch-potato" issues of prior work - when the agent finds a way to instantly gratify itself by exploiting actions which lead to hardly predictable consequences. We test our approach in visually rich 3D environments in ViZDoom, DMLab and MuJoCo. In navigational tasks from ViZDoom and DMLab, our agent outperforms the state-of-the-art curiosity method ICM. In MuJoCo, an ant equipped with our curiosity module learns locomotion out of the first-person-view curiosity only.