 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioLM: a Language Modeling Approach to Audio Generation
Sep 07, 2022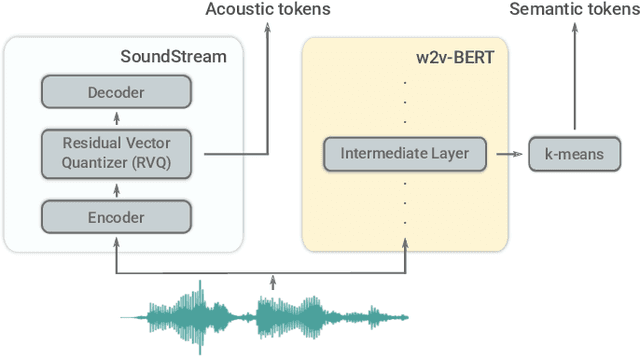

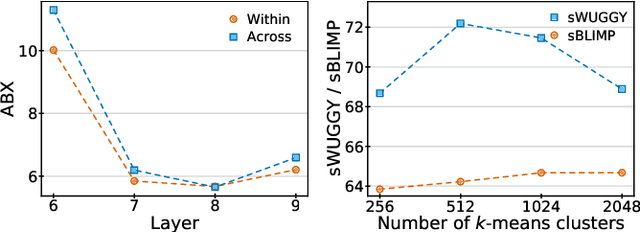

We introduce AudioLM, a framework for high-quality audio generation with long-term consistency. AudioLM maps the input audio to a sequence of discrete tokens and casts audio generation as a language modeling task in this representation space. We show how existing audio tokenizers provide different trade-offs between reconstruction quality and long-term structure, and we propose a hybrid tokenization scheme to achieve both objectives. Namely, we leverage the discretized activations of a masked language model pre-trained on audio to capture long-term structure and the discrete codes produced by a neural audio codec to achieve high-quality synthesis. By training on large corpora of raw audio waveforms, AudioLM learns to generate natural and coherent continuations given short prompts. When trained on speech, and without any transcript or annotation, AudioLM generates syntactically and semantically plausible speech continuations while also maintaining speaker identity and prosody for unseen speakers. Furthermore, we demonstrate how our approach extends beyond speech by generating coherent piano music continuations, despite being trained without any symbolic representation of music.
Learning strides in convolutional neural networks
Feb 03, 2022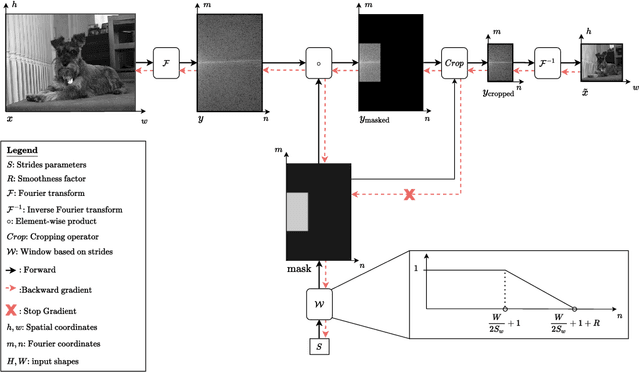
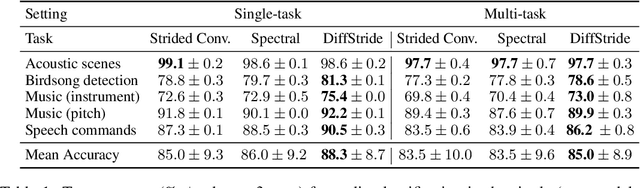
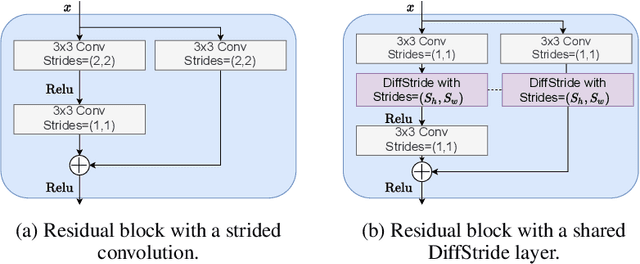
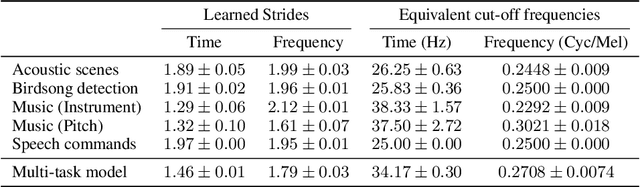
Convolutional neural networks typically contain several downsampling operators, such as strided convolutions or pooling layers, that progressively reduce the resolution of intermediate representations. This provides some shift-invariance while reducing the computational complexity of the whole architecture. A critical hyperparameter of such layers is their stride: the integer factor of downsampling. As strides are not differentiable, finding the best configuration either requires cross-validation or discrete optimization (e.g. architecture search), which rapidly become prohibitive as the search space grows exponentially with the number of downsampling layers. Hence, exploring this search space by gradient descent would allow finding better configurations at a lower computational cost. This work introduces DiffStride, the first downsampling layer with learnable strides. Our layer learns the size of a cropping mask in the Fourier domain, that effectively performs resizing in a differentiable way. Experiments on audio and image classification show the generality and effectiveness of our solution: we use DiffStride as a drop-in replacement to standard downsampling layers and outperform them. In particular, we show that introducing our layer into a ResNet-18 architecture allows keeping consistent high performance on CIFAR10, CIFAR100 and ImageNet even when training starts from poor random stride configurations. Moreover, formulating strides as learnable variables allows us to introduce a regularization term that controls the computational complexity of the architecture. We show how this regularization allows trading off accuracy for efficiency on ImageNet.
Optimal Transport Tools : A JAX Toolbox for all things Wasserstein
Jan 28, 2022
Optimal transport tools (OTT-JAX) is a Python toolbox that can solve optimal transport problems between point clouds and histograms. The toolbox builds on various JAX features, such as automatic and custom reverse mode differentiation, vectorization, just-in-time compilation and accelerators support. The toolbox covers elementary computations, such as the resolution of the regularized OT problem, and more advanced extensions, such as barycenters, Gromov-Wasserstein, low-rank solvers, estimation of convex maps, differentiable generalizations of quantiles and ranks, and approximate OT between Gaussian mixtures. The toolbox code is available at \texttt{https://github.com/ott-jax/ott}
DIVE: End-to-end Speech Diarization via Iterative Speaker Embedding
May 28, 2021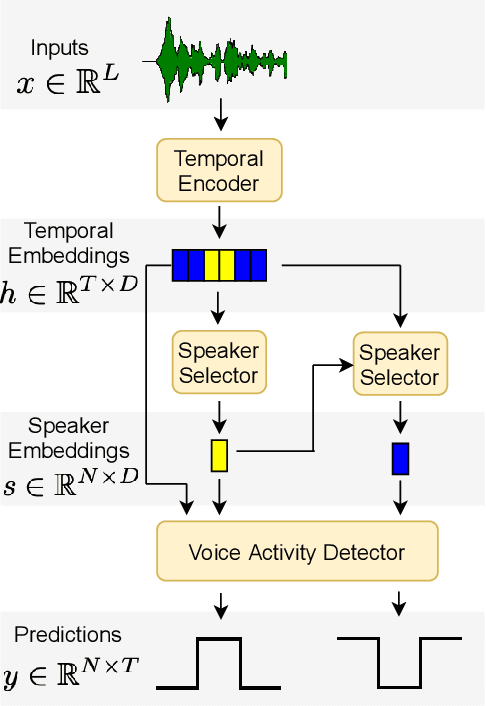
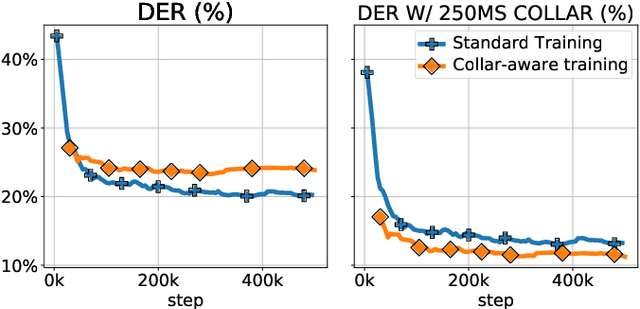
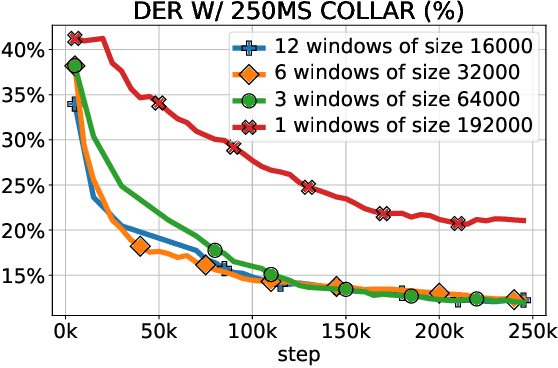

We introduce DIVE, an end-to-end speaker diarization algorithm. Our neural algorithm presents the diarization task as an iterative process: it repeatedly builds a representation for each speaker before predicting the voice activity of each speaker conditioned on the extracted representations. This strategy intrinsically resolves the speaker ordering ambiguity without requiring the classical permutation invariant training loss. In contrast with prior work, our model does not rely on pretrained speaker representations and optimizes all parameters of the system with a multi-speaker voice activity loss. Importantly, our loss explicitly excludes unreliable speaker turn boundaries from training, which is adapted to the standard collar-based Diarization Error Rate (DER) evaluation. Overall, these contributions yield a system redefining the state-of-the-art on the standard CALLHOME benchmark, with 6.7% DER compared to 7.8% for the best alternative.
Self-Supervised Learning of Audio Representations from Permutations with Differentiable Ranking
Mar 17, 2021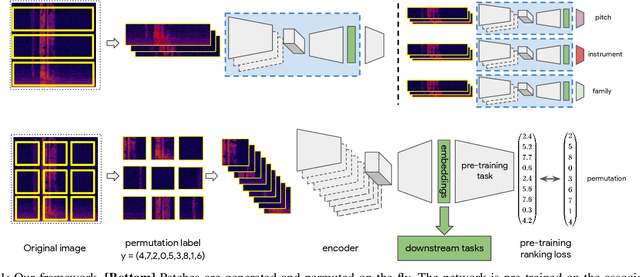
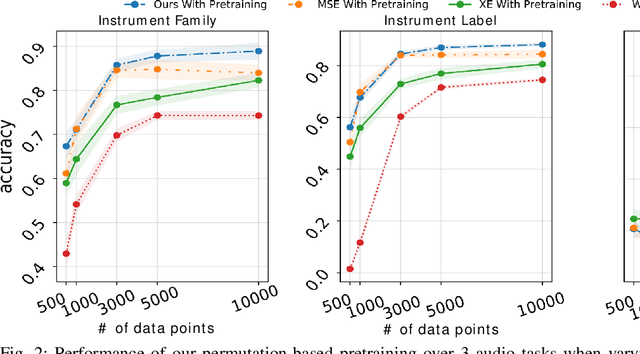
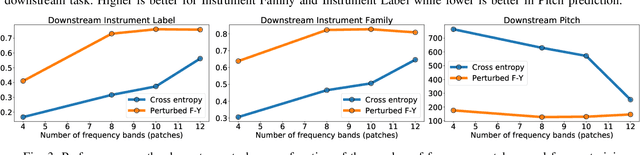
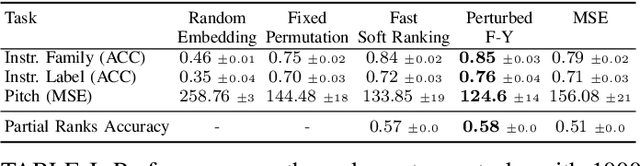
Self-supervised pre-training using so-called "pretext" tasks has recently shown impressive performance across a wide range of modalities. In this work, we advance self-supervised learning from permutations, by pre-training a model to reorder shuffled parts of the spectrogram of an audio signal, to improve downstream classification performance. We make two main contributions. First, we overcome the main challenges of integrating permutation inversions into an end-to-end training scheme, using recent advances in differentiable ranking. This was heretofore sidestepped by casting the reordering task as classification, fundamentally reducing the space of permutations that can be exploited. Our experiments validate that learning from all possible permutations improves the quality of the pre-trained representations over using a limited, fixed set. Second, we show that inverting permutations is a meaningful pretext task for learning audio representations in an unsupervised fashion. In particular, we improve instrument classification and pitch estimation of musical notes by reordering spectrogram patches in the time-frequency space.
LEAF: A Learnable Frontend for Audio Classification
Jan 21, 2021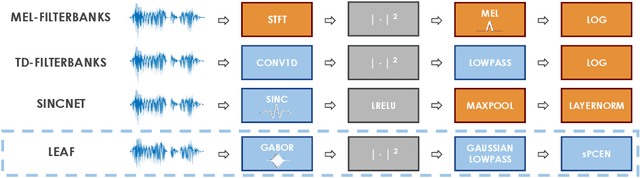
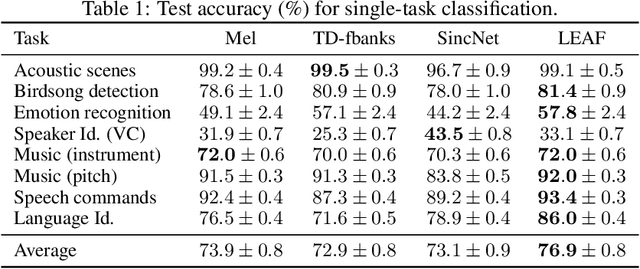
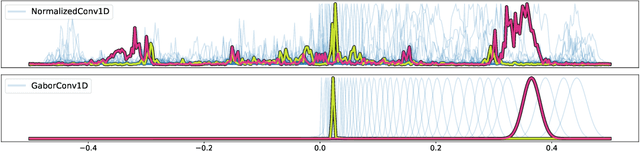

Mel-filterbanks are fixed, engineered audio features which emulate human perception and have been used through the history of audio understanding up to today. However, their undeniable qualities are counterbalanced by the fundamental limitations of handmade representations. In this work we show that we can train a single learnable frontend that outperforms mel-filterbanks on a wide range of audio signals, including speech, music, audio events and animal sounds, providing a general-purpose learned frontend for audio classification. To do so, we introduce a new principled, lightweight, fully learnable architecture that can be used as a drop-in replacement of mel-filterbanks. Our system learns all operations of audio features extraction, from filtering to pooling, compression and normalization, and can be integrated into any neural network at a negligible parameter cost. We perform multi-task training on eight diverse audio classification tasks, and show consistent improvements of our model over mel-filterbanks and previous learnable alternatives. Moreover, our system outperforms the current state-of-the-art learnable frontend on Audioset, with orders of magnitude fewer parameters.
Noisy Adaptive Group Testing using Bayesian Sequential Experimental Design
May 15, 2020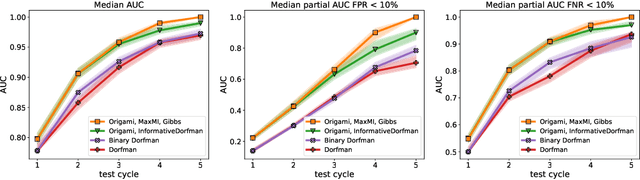

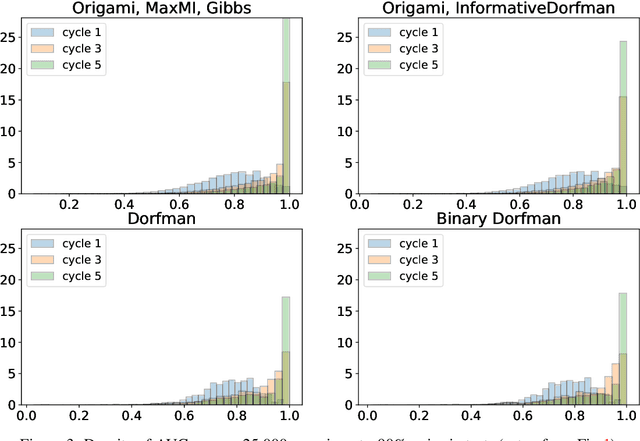

When test resources are scarce and infection prevalence is low, testing groups of individuals can be more efficient than testing individuals. This can be done by pooling individual samples (in groups, and only test those groups for the presence of a pathogen. The rationale is that if prevalence is low, many of these groups will ideally test negative, clearing all all individuals from such groups, whereas individuals appearing in (ideally few) positive groups will require further screening. Forming those groups in order to minimize testing costs while maintaining good detection is the goal of group testing algorithms. We propose a new framework to form such groups that takes into account various constraints of the testing environment, and which can easily incorporate individualized infection priors. Our solution solves a Bayesian sequential experimental design problem: Given previous group test results, we sample the posterior distribution of infection status vectors using sequential Monte Carlo samplers; these samples are then fed to an optimizer, which seeks to form groups that maximize an information gain if those future tests were to be known. To output marginal probabilities of infection, we use loopy belief propagation as a decoder. We show a significant empirical improvement over individualized tests in simulations: our G-MIMAX test procedure has an average specificity/sensitivity that significantly exceeds that of other baselines, including individual tests, as long as the disease prevalence $\leq 5\%$.
Fast Differentiable Sorting and Ranking
Feb 20, 2020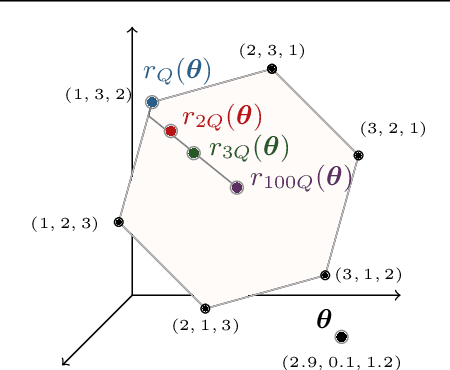
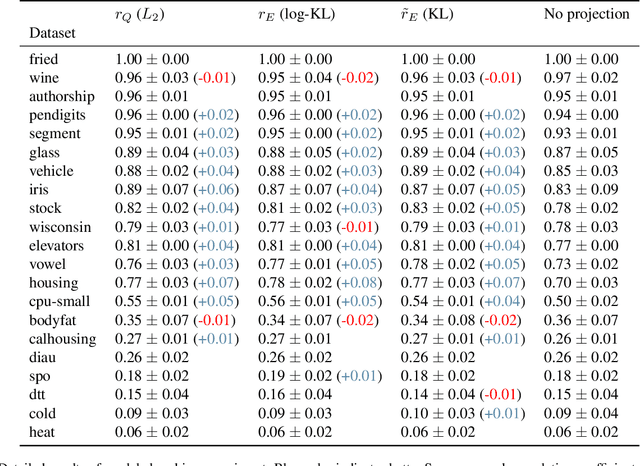
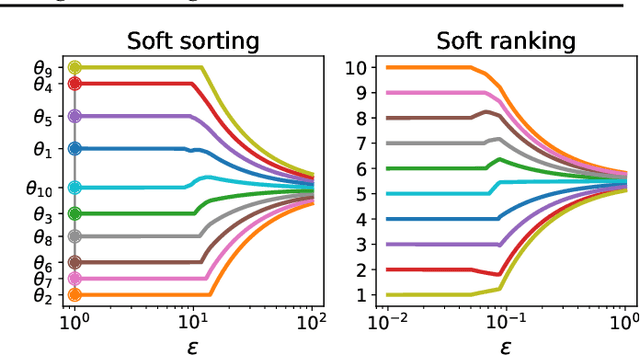
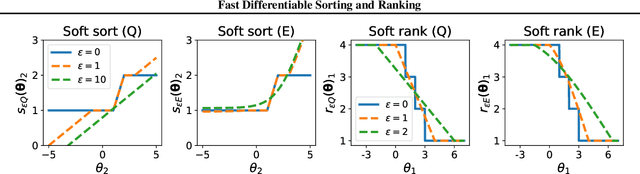
The sorting operation is one of the most basic and commonly used building blocks in computer programming. In machine learning, it is commonly used for robust statistics. However, seen as a function, it is piecewise linear and as a result includes many kinks at which it is non-differentiable. More problematic is the related ranking operator, commonly used for order statistics and ranking metrics. It is a piecewise constant function, meaning that its derivatives are null or undefined. While numerous works have proposed differentiable proxies to sorting and ranking, they do not achieve the $O(n \log n)$ time complexity one would expect from sorting and ranking operations. In this paper, we propose the first differentiable sorting and ranking operators with $O(n \log n)$ time and $O(n)$ space complexity. Our proposal in addition enjoys exact computation and differentiation. We achieve this feat by constructing differentiable sorting and ranking operators as projections onto the permutahedron, the convex hull of permutations, and using a reduction to isotonic optimization. Empirically, we confirm that our approach is an order of magnitude faster than existing approaches and showcase two novel applications: differentiable Spearman's rank correlation coefficient and soft least trimmed squares.
Learning with Differentiable Perturbed Optimizers
Feb 20, 2020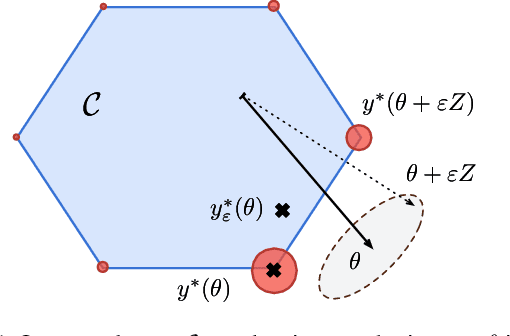
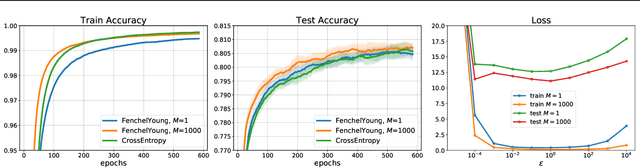

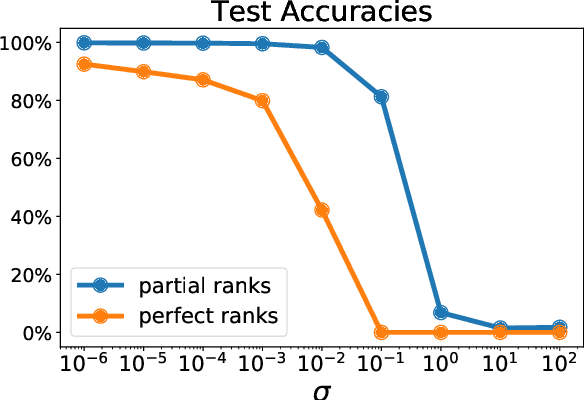
Machine learning pipelines often rely on optimization procedures to make discrete decisions (e.g. sorting, picking closest neighbors, finding shortest paths or optimal matchings). Although these discrete decisions are easily computed in a forward manner, they cannot be used to modify model parameters using first-order optimization techniques because they break the back-propagation of computational graphs. In order to expand the scope of learning problems that can be solved in an end-to-end fashion, we propose a systematic method to transform a block that outputs an optimal discrete decision into a differentiable operation. Our approach relies on stochastic perturbations of these parameters, and can be used readily within existing solvers without the need for ad hoc regularization or smoothing. These perturbed optimizers yield solutions that are differentiable and never locally constant. The amount of smoothness can be tuned via the chosen noise amplitude, whose impact we analyze. The derivatives of these perturbed solvers can be evaluated efficiently. We also show how this framework can be connected to a family of losses developed in structured prediction, and describe how these can be used in unsupervised and supervised learning, with theoretical guarantees. We demonstrate the performance of our approach on several machine learning tasks in experiments on synthetic and real data.
Supervised Quantile Normalization for Low-rank Matrix Approximation
Feb 08, 2020
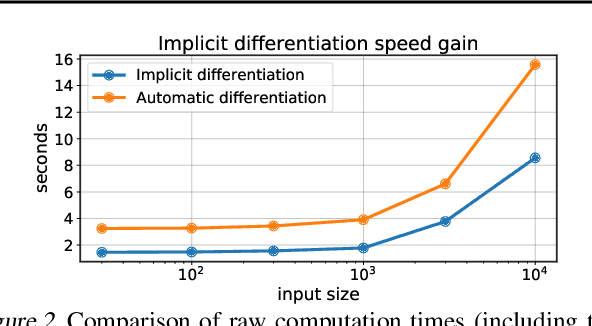

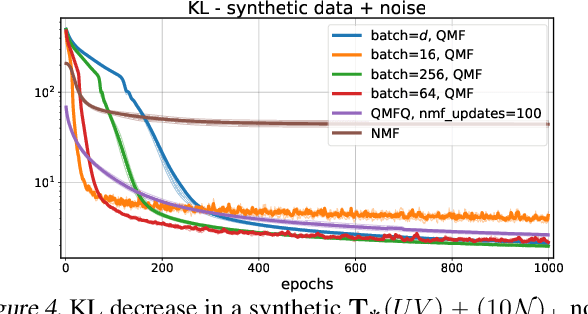
Low rank matrix factorization is a fundamental building block in machine learning, used for instance to summarize gene expression profile data or word-document counts. To be robust to outliers and differences in scale across features, a matrix factorization step is usually preceded by ad-hoc feature normalization steps, such as \texttt{tf-idf} scaling or data whitening. We propose in this work to learn these normalization operators jointly with the factorization itself. More precisely, given a $d\times n$ matrix $X$ of $d$ features measured on $n$ individuals, we propose to learn the parameters of quantile normalization operators that can operate row-wise on the values of $X$ and/or of its factorization $UV$ to improve the quality of the low-rank representation of $X$ itself. This optimization is facilitated by the introduction of a differentiable quantile normalization operator built using optimal transport, providing new results on top of existing work by Cuturi et al. (2019). We demonstrate the applicability of these techniques on synthetic and genomics datasets.