 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Novel LLM Experts via Task-Capability Coevolution
Apr 16, 2026Frontier model developers aim to train models continually to possess emergent, diverse capabilities. To extend capabilities, the current pre-training and post-training paradigm requires manually starting training runs with static datasets or reward functions every time. Addressing this limitation, our work pursues the insight that open-endedness (via the coevolution of models and tasks) can discover models with increasingly novel skills in a single run. We introduce a new model development framework that extends coevolution to large language model (LLM) discovery, open-ended \textit{Assessment Coevolving with Diverse Capabilities} (AC/DC). AC/DC evolves both LLMs via model merging and natural language tasks via synthetic data generation. AC/DC discovers growing archives of LLMs that surpass the capabilities of larger LLMs while taking up less GPU memory. In particular, our LLM populations achieve a broader Coverage of expertise than other curated models or baselines on downstream benchmarks, without \textit{any} explicit benchmark optimization. Furthermore, AC/DC improves Coverage over time, continually innovates on tasks and models, and improves performance in multi-agent best-of-N selection. Our findings highlight the potential of coevolution as a means of discovering broader sets of capabilities from base LLMs. Overall, AC/DC brings us one step closer to a profoundly new paradigm of LLM development, where continual improvements to the diversity of model capabilities can be accelerated by leveraging existing models as stepping stones to increasingly powerful models.
Emergence of Painting Ability via Recognition-Driven Evolution
Jan 09, 2025From Paleolithic cave paintings to Impressionism, human painting has evolved to depict increasingly complex and detailed scenes, conveying more nuanced messages. This paper attempts to emerge this artistic capability by simulating the evolutionary pressures that enhance visual communication efficiency. Specifically, we present a model with a stroke branch and a palette branch that together simulate human-like painting. The palette branch learns a limited colour palette, while the stroke branch parameterises each stroke using B\'ezier curves to render an image, subsequently evaluated by a high-level recognition module. We quantify the efficiency of visual communication by measuring the recognition accuracy achieved with machine vision. The model then optimises the control points and colour choices for each stroke to maximise recognition accuracy with minimal strokes and colours. Experimental results show that our model achieves superior performance in high-level recognition tasks, delivering artistic expression and aesthetic appeal, especially in abstract sketches. Additionally, our approach shows promise as an efficient bit-level image compression technique, outperforming traditional methods.
Evolution of Collective AI Beyond Individual Optimization
Dec 03, 2024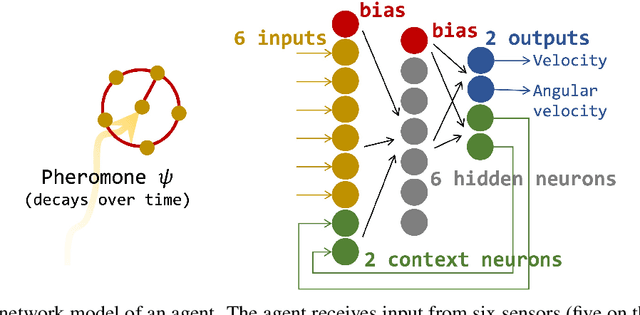

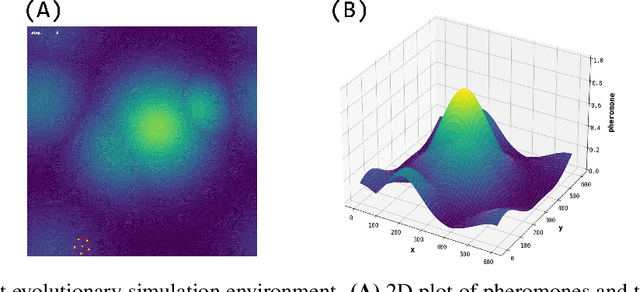
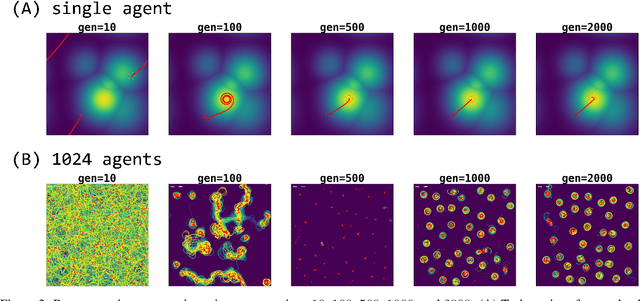
This study investigates collective behaviors that emerge from a group of homogeneous individuals optimized for a specific capability. We created a group of simple, identical neural network based agents modeled after chemotaxis-driven vehicles that follow pheromone trails and examined multi-agent simulations using clones of these evolved individuals. Our results show that the evolution of individuals led to population differentiation. Surprisingly, we observed that collective fitness significantly changed during later evolutionary stages, despite maintained high individual performance and simplified neural architectures. This decline occurred when agents developed reduced sensor-motor coupling, suggesting that over-optimization of individual agents almost always lead to less effective group behavior. Our research investigates how individual differentiation can evolve through what evolutionary pathways.
Position: Leverage Foundational Models for Black-Box Optimization
May 09, 2024

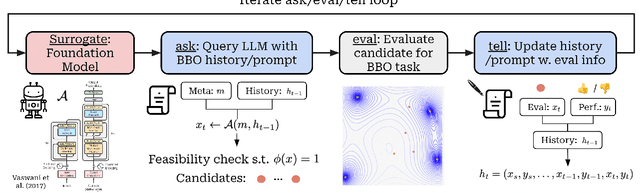

Undeniably, Large Language Models (LLMs) have stirred an extraordinary wave of innovation in the machine learning research domain, resulting in substantial impact across diverse fields such as reinforcement learning, robotics, and computer vision. Their incorporation has been rapid and transformative, marking a significant paradigm shift in the field of machine learning research. However, the field of experimental design, grounded on black-box optimization, has been much less affected by such a paradigm shift, even though integrating LLMs with optimization presents a unique landscape ripe for exploration. In this position paper, we frame the field of black-box optimization around sequence-based foundation models and organize their relationship with previous literature. We discuss the most promising ways foundational language models can revolutionize optimization, which include harnessing the vast wealth of information encapsulated in free-form text to enrich task comprehension, utilizing highly flexible sequence models such as Transformers to engineer superior optimization strategies, and enhancing performance prediction over previously unseen search spaces.
Position Paper: Leveraging Foundational Models for Black-Box Optimization: Benefits, Challenges, and Future Directions
May 06, 2024Undeniably, Large Language Models (LLMs) have stirred an extraordinary wave of innovation in the machine learning research domain, resulting in substantial impact across diverse fields such as reinforcement learning, robotics, and computer vision. Their incorporation has been rapid and transformative, marking a significant paradigm shift in the field of machine learning research. However, the field of experimental design, grounded on black-box optimization, has been much less affected by such a paradigm shift, even though integrating LLMs with optimization presents a unique landscape ripe for exploration. In this position paper, we frame the field of black-box optimization around sequence-based foundation models and organize their relationship with previous literature. We discuss the most promising ways foundational language models can revolutionize optimization, which include harnessing the vast wealth of information encapsulated in free-form text to enrich task comprehension, utilizing highly flexible sequence models such as Transformers to engineer superior optimization strategies, and enhancing performance prediction over previously unseen search spaces.
Shaping Realities: Enhancing 3D Generative AI with Fabrication Constraints
Apr 17, 2024
Generative AI tools are becoming more prevalent in 3D modeling, enabling users to manipulate or create new models with text or images as inputs. This makes it easier for users to rapidly customize and iterate on their 3D designs and explore new creative ideas. These methods focus on the aesthetic quality of the 3D models, refining them to look similar to the prompts provided by the user. However, when creating 3D models intended for fabrication, designers need to trade-off the aesthetic qualities of a 3D model with their intended physical properties. To be functional post-fabrication, 3D models have to satisfy structural constraints informed by physical principles. Currently, such requirements are not enforced by generative AI tools. This leads to the development of aesthetically appealing, but potentially non-functional 3D geometry, that would be hard to fabricate and use in the real world. This workshop paper highlights the limitations of generative AI tools in translating digital creations into the physical world and proposes new augmentations to generative AI tools for creating physically viable 3D models. We advocate for the development of tools that manipulate or generate 3D models by considering not only the aesthetic appearance but also using physical properties as constraints. This exploration seeks to bridge the gap between digital creativity and real-world applicability, extending the creative potential of generative AI into the tangible domain.
DiffCJK: Conditional Diffusion Model for High-Quality and Wide-coverage CJK Character Generation
Apr 08, 2024
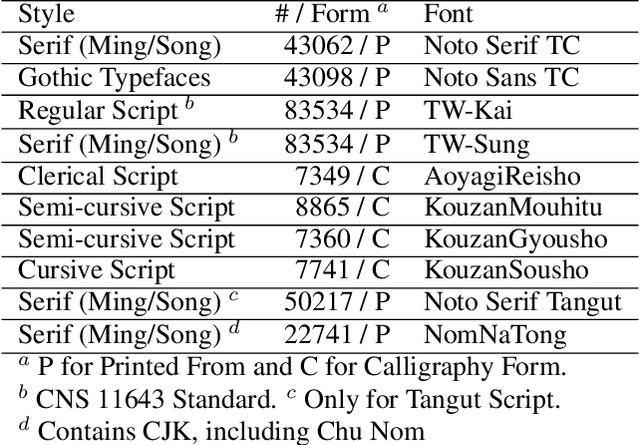


Chinese, Japanese, and Korean (CJK), with a vast number of native speakers, has profound influence on society and culture. The typesetting of CJK languages carries a wide range of requirements due to the complexity of their scripts and unique literary traditions. A critical aspect of this typesetting process is that CJK fonts need to provide a set of consistent-looking glyphs for approximately one hundred thousand characters. However, creating such a font is inherently labor-intensive and expensive, which significantly hampers the development of new CJK fonts for typesetting, historical, aesthetic, or artistic purposes. To bridge this gap, we are motivated by recent advancements in diffusion-based generative models and propose a novel diffusion method for generating glyphs in a targeted style from a \emph{single} conditioned, standard glyph form. Our experiments show that our method is capable of generating fonts of both printed and hand-written styles, the latter of which presents a greater challenge. Moreover, our approach shows remarkable zero-shot generalization capabilities for non-CJK but Chinese-inspired scripts. We also show our method facilitates smooth style interpolation and generates bitmap images suitable for vectorization, which is crucial in the font creation process. In summary, our proposed method opens the door to high-quality, generative model-assisted font creation for CJK characters, for both typesetting and artistic endeavors.
Evolution Transformer: In-Context Evolutionary Optimization
Mar 05, 2024



Evolutionary optimization algorithms are often derived from loose biological analogies and struggle to leverage information obtained during the sequential course of optimization. An alternative promising approach is to leverage data and directly discover powerful optimization principles via meta-optimization. In this work, we follow such a paradigm and introduce Evolution Transformer, a causal Transformer architecture, which can flexibly characterize a family of Evolution Strategies. Given a trajectory of evaluations and search distribution statistics, Evolution Transformer outputs a performance-improving update to the search distribution. The architecture imposes a set of suitable inductive biases, i.e. the invariance of the distribution update to the order of population members within a generation and equivariance to the order of the search dimensions. We train the model weights using Evolutionary Algorithm Distillation, a technique for supervised optimization of sequence models using teacher algorithm trajectories. The resulting model exhibits strong in-context optimization performance and shows strong generalization capabilities to otherwise challenging neuroevolution tasks. We analyze the resulting properties of the Evolution Transformer and propose a technique to fully self-referentially train the Evolution Transformer, starting from a random initialization and bootstrapping its own learning progress. We provide an open source implementation under https://github.com/RobertTLange/evosax.
Large Language Models As Evolution Strategies
Feb 28, 2024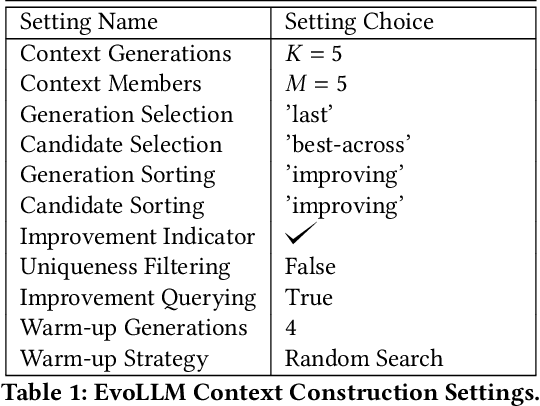

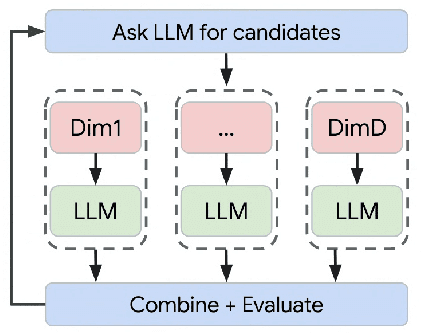
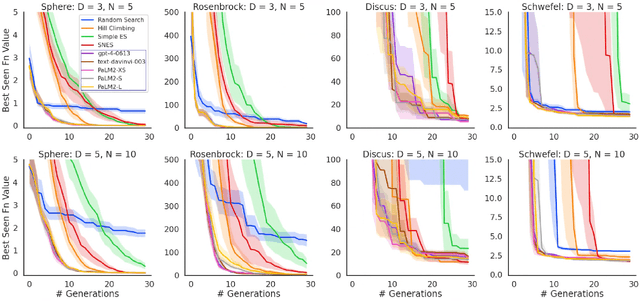
Large Transformer models are capable of implementing a plethora of so-called in-context learning algorithms. These include gradient descent, classification, sequence completion, transformation, and improvement. In this work, we investigate whether large language models (LLMs), which never explicitly encountered the task of black-box optimization, are in principle capable of implementing evolutionary optimization algorithms. While previous works have solely focused on language-based task specification, we move forward and focus on the zero-shot application of LLMs to black-box optimization. We introduce a novel prompting strategy, consisting of least-to-most sorting of discretized population members and querying the LLM to propose an improvement to the mean statistic, i.e. perform a type of black-box recombination operation. Empirically, we find that our setup allows the user to obtain an LLM-based evolution strategy, which we call `EvoLLM', that robustly outperforms baseline algorithms such as random search and Gaussian Hill Climbing on synthetic BBOB functions as well as small neuroevolution tasks. Hence, LLMs can act as `plug-in' in-context recombination operators. We provide several comparative studies of the LLM's model size, prompt strategy, and context construction. Finally, we show that one can flexibly improve EvoLLM's performance by providing teacher algorithm information via instruction fine-tuning on previously collected teacher optimization trajectories.
Digital Typhoon: Long-term Satellite Image Dataset for the Spatio-Temporal Modeling of Tropical Cyclones
Nov 05, 2023This paper presents the official release of the Digital Typhoon dataset, the longest typhoon satellite image dataset for 40+ years aimed at benchmarking machine learning models for long-term spatio-temporal data. To build the dataset, we developed a workflow to create an infrared typhoon-centered image for cropping using Lambert azimuthal equal-area projection referring to the best track data. We also address data quality issues such as inter-satellite calibration to create a homogeneous dataset. To take advantage of the dataset, we organized machine learning tasks by the types and targets of inference, with other tasks for meteorological analysis, societal impact, and climate change. The benchmarking results on the analysis, forecasting, and reanalysis for the intensity suggest that the dataset is challenging for recent deep learning models, due to many choices that affect the performance of various models. This dataset reduces the barrier for machine learning researchers to meet large-scale real-world events called tropical cyclones and develop machine learning models that may contribute to advancing scientific knowledge on tropical cyclones as well as solving societal and sustainability issues such as disaster reduction and climate change. The dataset is publicly available at http://agora.ex.nii.ac.jp/digital-typhoon/dataset/ and https://github.com/kitamoto-lab/digital-typhoon/.