 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting from Strings: Language Model Embeddings for Bayesian Optimization
Oct 15, 2024


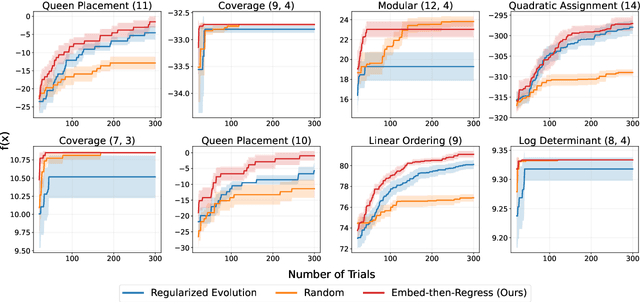
Bayesian Optimization is ubiquitous in the field of experimental design and blackbox optimization for improving search efficiency, but has been traditionally restricted to regression models which are only applicable to fixed search spaces and tabular input features. We propose Embed-then-Regress, a paradigm for applying in-context regression over string inputs, through the use of string embedding capabilities of pretrained language models. By expressing all inputs as strings, we are able to perform general-purpose regression for Bayesian Optimization over various domains including synthetic, combinatorial, and hyperparameter optimization, obtaining comparable results to state-of-the-art Gaussian Process-based algorithms. Code can be found at https://github.com/google-research/optformer/tree/main/optformer/embed_then_regress.
The Vizier Gaussian Process Bandit Algorithm
Aug 21, 2024Google Vizier has performed millions of optimizations and accelerated numerous research and production systems at Google, demonstrating the success of Bayesian optimization as a large-scale service. Over multiple years, its algorithm has been improved considerably, through the collective experiences of numerous research efforts and user feedback. In this technical report, we discuss the implementation details and design choices of the current default algorithm provided by Open Source Vizier. Our experiments on standardized benchmarks reveal its robustness and versatility against well-established industry baselines on multiple practical modes.
Position: Leverage Foundational Models for Black-Box Optimization
May 09, 2024

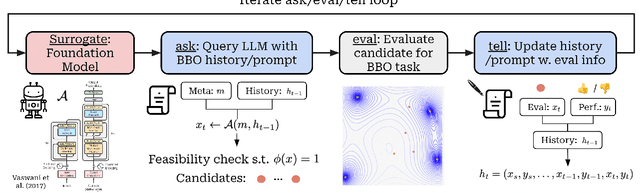

Undeniably, Large Language Models (LLMs) have stirred an extraordinary wave of innovation in the machine learning research domain, resulting in substantial impact across diverse fields such as reinforcement learning, robotics, and computer vision. Their incorporation has been rapid and transformative, marking a significant paradigm shift in the field of machine learning research. However, the field of experimental design, grounded on black-box optimization, has been much less affected by such a paradigm shift, even though integrating LLMs with optimization presents a unique landscape ripe for exploration. In this position paper, we frame the field of black-box optimization around sequence-based foundation models and organize their relationship with previous literature. We discuss the most promising ways foundational language models can revolutionize optimization, which include harnessing the vast wealth of information encapsulated in free-form text to enrich task comprehension, utilizing highly flexible sequence models such as Transformers to engineer superior optimization strategies, and enhancing performance prediction over previously unseen search spaces.
Position Paper: Leveraging Foundational Models for Black-Box Optimization: Benefits, Challenges, and Future Directions
May 06, 2024Undeniably, Large Language Models (LLMs) have stirred an extraordinary wave of innovation in the machine learning research domain, resulting in substantial impact across diverse fields such as reinforcement learning, robotics, and computer vision. Their incorporation has been rapid and transformative, marking a significant paradigm shift in the field of machine learning research. However, the field of experimental design, grounded on black-box optimization, has been much less affected by such a paradigm shift, even though integrating LLMs with optimization presents a unique landscape ripe for exploration. In this position paper, we frame the field of black-box optimization around sequence-based foundation models and organize their relationship with previous literature. We discuss the most promising ways foundational language models can revolutionize optimization, which include harnessing the vast wealth of information encapsulated in free-form text to enrich task comprehension, utilizing highly flexible sequence models such as Transformers to engineer superior optimization strategies, and enhancing performance prediction over previously unseen search spaces.
OmniPred: Language Models as Universal Regressors
Mar 04, 2024Over the broad landscape of experimental design, regression has been a powerful tool to accurately predict the outcome metrics of a system or model given a set of parameters, but has been traditionally restricted to methods which are only applicable to a specific task. In this paper, we propose OmniPred, a framework for training language models as universal end-to-end regressors over $(x,y)$ evaluation data from diverse real world experiments. Using data sourced from Google Vizier, one of the largest blackbox optimization databases in the world, our extensive experiments demonstrate that through only textual representations of mathematical parameters and values, language models are capable of very precise numerical regression, and if given the opportunity to train over multiple tasks, can significantly outperform traditional regression models.
Task Selection for AutoML System Evaluation
Aug 26, 2022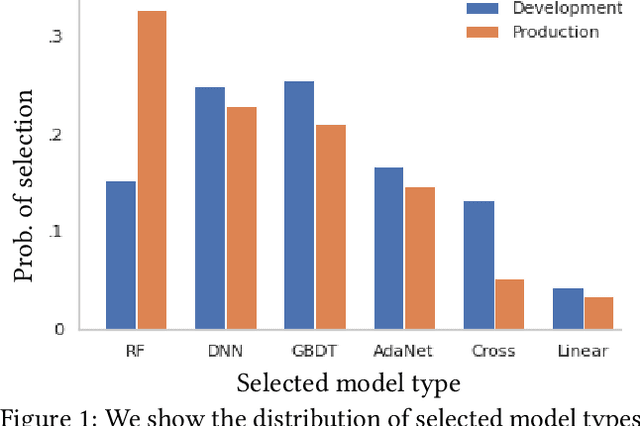

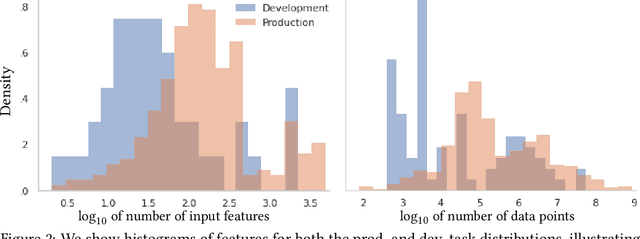

Our goal is to assess if AutoML system changes - i.e., to the search space or hyperparameter optimization - will improve the final model's performance on production tasks. However, we cannot test the changes on production tasks. Instead, we only have access to limited descriptors about tasks that our AutoML system previously executed, like the number of data points or features. We also have a set of development tasks to test changes, ex., sampled from OpenML with no usage constraints. However, the development and production task distributions are different leading us to pursue changes that only improve development and not production. This paper proposes a method to leverage descriptor information about AutoML production tasks to select a filtered subset of the most relevant development tasks. Empirical studies show that our filtering strategy improves the ability to assess AutoML system changes on holdout tasks with different distributions than development.
Open Source Vizier: Distributed Infrastructure and API for Reliable and Flexible Blackbox Optimization
Jul 27, 2022
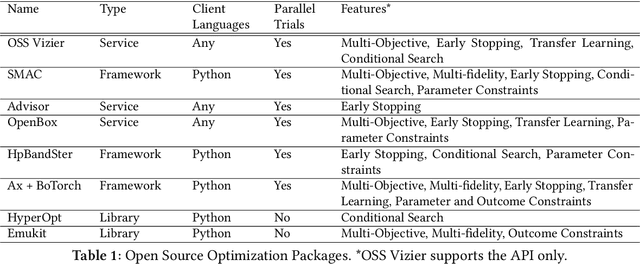

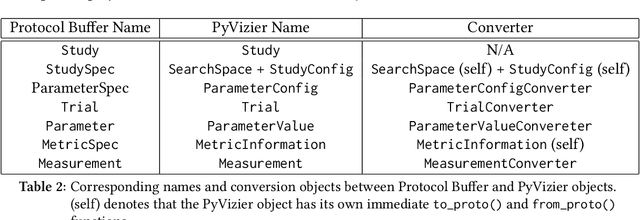
Vizier is the de-facto blackbox and hyperparameter optimization service across Google, having optimized some of Google's largest products and research efforts. To operate at the scale of tuning thousands of users' critical systems, Google Vizier solved key design challenges in providing multiple different features, while remaining fully fault-tolerant. In this paper, we introduce Open Source (OSS) Vizier, a standalone Python-based interface for blackbox optimization and research, based on the Google-internal Vizier infrastructure and framework. OSS Vizier provides an API capable of defining and solving a wide variety of optimization problems, including multi-metric, early stopping, transfer learning, and conditional search. Furthermore, it is designed to be a distributed system that assures reliability, and allows multiple parallel evaluations of the user's objective function. The flexible RPC-based infrastructure allows users to access OSS Vizier from binaries written in any language. OSS Vizier also provides a back-end ("Pythia") API that gives algorithm authors a way to interface new algorithms with the core OSS Vizier system. OSS Vizier is available at https://github.com/google/vizier.
Pre-training helps Bayesian optimization too
Jul 07, 2022
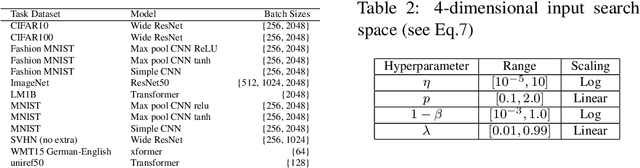
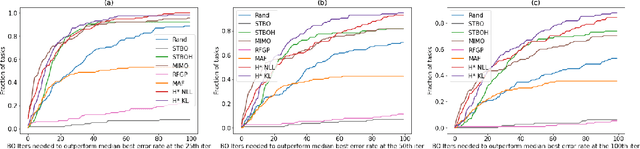
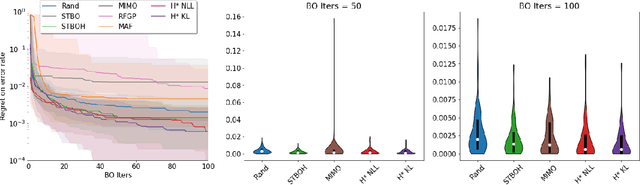
Bayesian optimization (BO) has become a popular strategy for global optimization of many expensive real-world functions. Contrary to a common belief that BO is suited to optimizing black-box functions, it actually requires domain knowledge on characteristics of those functions to deploy BO successfully. Such domain knowledge often manifests in Gaussian process priors that specify initial beliefs on functions. However, even with expert knowledge, it is not an easy task to select a prior. This is especially true for hyperparameter tuning problems on complex machine learning models, where landscapes of tuning objectives are often difficult to comprehend. We seek an alternative practice for setting these functional priors. In particular, we consider the scenario where we have data from similar functions that allow us to pre-train a tighter distribution a priori. To verify our approach in realistic model training setups, we collected a large multi-task hyperparameter tuning dataset by training tens of thousands of configurations of near-state-of-the-art models on popular image and text datasets, as well as a protein sequence dataset. Our results show that on average, our method is able to locate good hyperparameters at least 3 times more efficiently than the best competing methods.
Towards Learning Universal Hyperparameter Optimizers with Transformers
May 26, 2022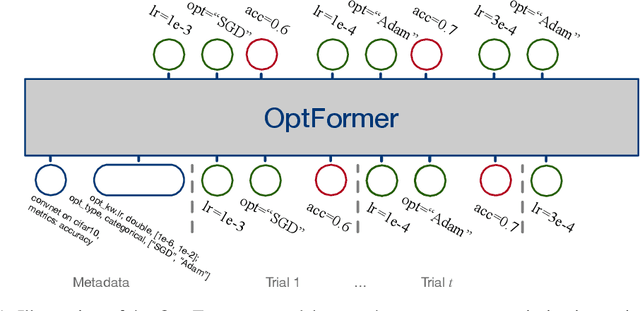


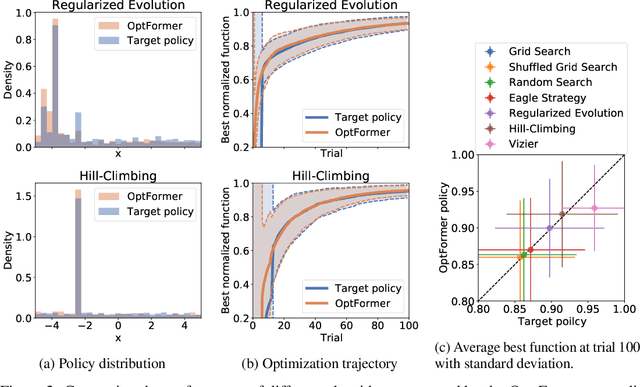
Meta-learning hyperparameter optimization (HPO) algorithms from prior experiments is a promising approach to improve optimization efficiency over objective functions from a similar distribution. However, existing methods are restricted to learning from experiments sharing the same set of hyperparameters. In this paper, we introduce the OptFormer, the first text-based Transformer HPO framework that provides a universal end-to-end interface for jointly learning policy and function prediction when trained on vast tuning data from the wild. Our extensive experiments demonstrate that the OptFormer can imitate at least 7 different HPO algorithms, which can be further improved via its function uncertainty estimates. Compared to a Gaussian Process, the OptFormer also learns a robust prior distribution for hyperparameter response functions, and can thereby provide more accurate and better calibrated predictions. This work paves the path to future extensions for training a Transformer-based model as a general HPO optimizer.
Automatic prior selection for meta Bayesian optimization with a case study on tuning deep neural network optimizers
Sep 16, 2021
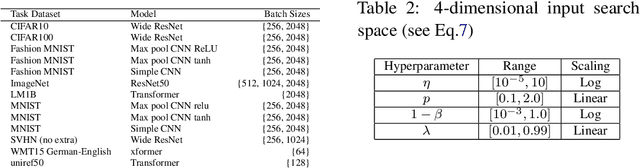
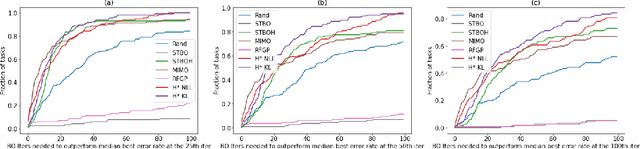

The performance of deep neural networks can be highly sensitive to the choice of a variety of meta-parameters, such as optimizer parameters and model hyperparameters. Tuning these well, however, often requires extensive and costly experimentation. Bayesian optimization (BO) is a principled approach to solve such expensive hyperparameter tuning problems efficiently. Key to the performance of BO is specifying and refining a distribution over functions, which is used to reason about the optima of the underlying function being optimized. In this work, we consider the scenario where we have data from similar functions that allows us to specify a tighter distribution a priori. Specifically, we focus on the common but potentially costly task of tuning optimizer parameters for training neural networks. Building on the meta BO method from Wang et al. (2018), we develop practical improvements that (a) boost its performance by leveraging tuning results on multiple tasks without requiring observations for the same meta-parameter points across all tasks, and (b) retain its regret bound for a special case of our method. As a result, we provide a coherent BO solution for iterative optimization of continuous optimizer parameters. To verify our approach in realistic model training setups, we collected a large multi-task hyperparameter tuning dataset by training tens of thousands of configurations of near-state-of-the-art models on popular image and text datasets, as well as a protein sequence dataset. Our results show that on average, our method is able to locate good hyperparameters at least 3 times more efficiently than the best competing methods.