 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Vizier Gaussian Process Bandit Algorithm
Aug 21, 2024Google Vizier has performed millions of optimizations and accelerated numerous research and production systems at Google, demonstrating the success of Bayesian optimization as a large-scale service. Over multiple years, its algorithm has been improved considerably, through the collective experiences of numerous research efforts and user feedback. In this technical report, we discuss the implementation details and design choices of the current default algorithm provided by Open Source Vizier. Our experiments on standardized benchmarks reveal its robustness and versatility against well-established industry baselines on multiple practical modes.
Embedded-model flows: Combining the inductive biases of model-free deep learning and explicit probabilistic modeling
Oct 17, 2021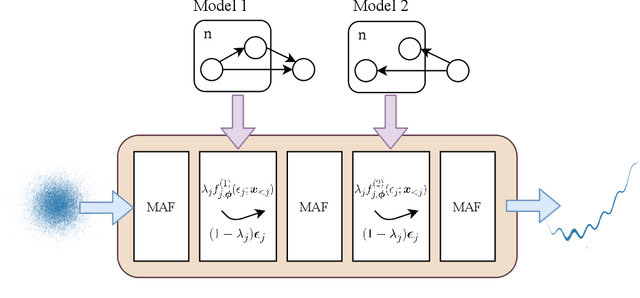



Normalizing flows have shown great success as general-purpose density estimators. However, many real world applications require the use of domain-specific knowledge, which normalizing flows cannot readily incorporate. We propose embedded-model flows (EMF), which alternate general-purpose transformations with structured layers that embed domain-specific inductive biases. These layers are automatically constructed by converting user-specified differentiable probabilistic models into equivalent bijective transformations. We also introduce gated structured layers, which allow bypassing the parts of the models that fail to capture the statistics of the data. We demonstrate that EMFs can be used to induce desirable properties such as multimodality, hierarchical coupling and continuity. Furthermore, we show that EMFs enable a high performance form of variational inference where the structure of the prior model is embedded in the variational architecture. In our experiments, we show that this approach outperforms state-of-the-art methods in common structured inference problems.
Likelihood Ratios for Out-of-Distribution Detection
Jun 07, 2019
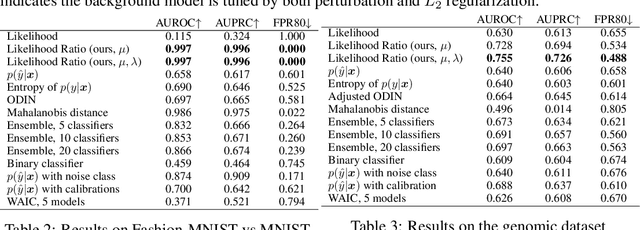

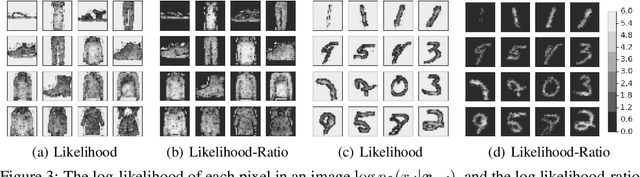
Discriminative neural networks offer little or no performance guarantees when deployed on data not generated by the same process as the training distribution. On such out-of-distribution (OOD) inputs, the prediction may not only be erroneous, but confidently so, limiting the safe deployment of classifiers in real-world applications. One such challenging application is bacteria identification based on genomic sequences, which holds the promise of early detection of diseases, but requires a model that can output low confidence predictions on OOD genomic sequences from new bacteria that were not present in the training data. We introduce a genomics dataset for OOD detection that allows other researchers to benchmark progress on this important problem. We investigate deep generative model based approaches for OOD detection and observe that the likelihood score is heavily affected by population level background statistics. We propose a likelihood ratio method for deep generative models which effectively corrects for these confounding background statistics. We benchmark the OOD detection performance of the proposed method against existing approaches on the genomics dataset and show that our method achieves state-of-the-art performance. We demonstrate the generality of the proposed method by showing that it significantly improves OOD detection when applied to deep generative models of images.
Can You Trust Your Model's Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift
Jun 06, 2019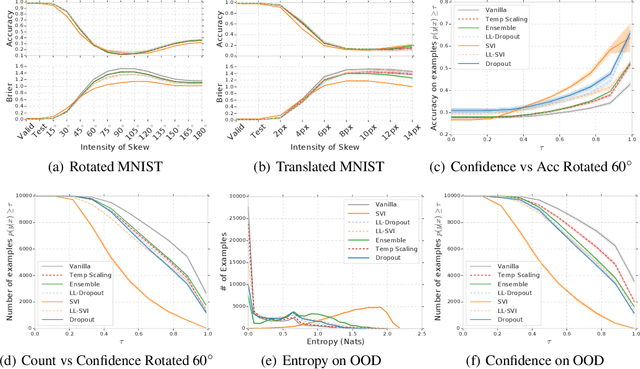
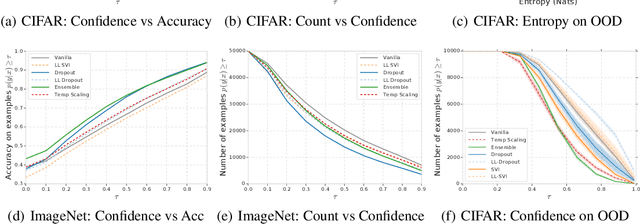
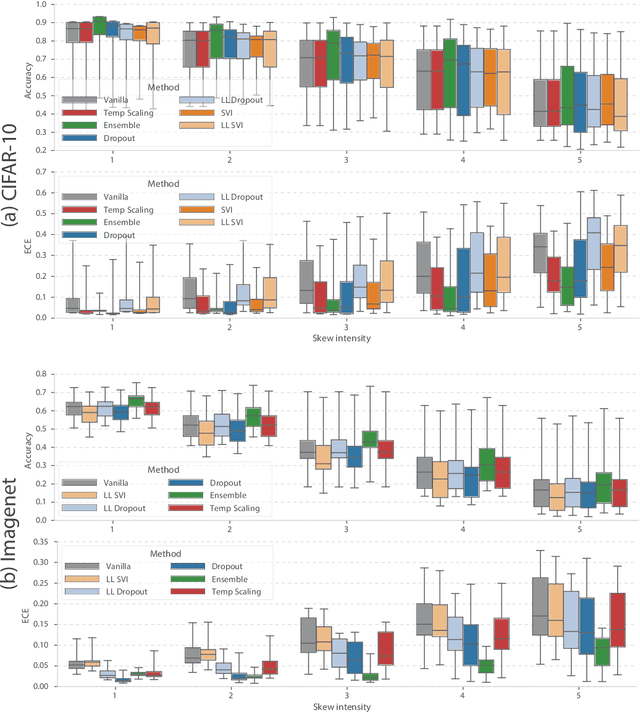
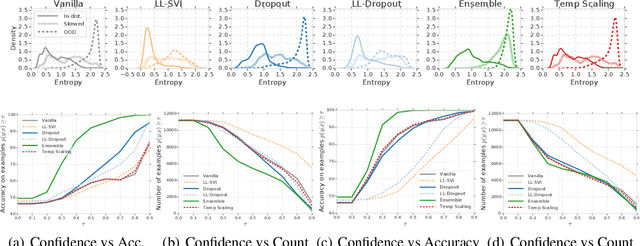
Modern machine learning methods including deep learning have achieved great success in predictive accuracy for supervised learning tasks, but may still fall short in giving useful estimates of their predictive {\em uncertainty}. Quantifying uncertainty is especially critical in real-world settings, which often involve input distributions that are shifted from the training distribution due to a variety of factors including sample bias and non-stationarity. In such settings, well calibrated uncertainty estimates convey information about when a model's output should (or should not) be trusted. Many probabilistic deep learning methods, including Bayesian-and non-Bayesian methods, have been proposed in the literature for quantifying predictive uncertainty, but to our knowledge there has not previously been a rigorous large-scale empirical comparison of these methods under dataset shift. We present a large-scale benchmark of existing state-of-the-art methods on classification problems and investigate the effect of dataset shift on accuracy and calibration. We find that traditional post-hoc calibration does indeed fall short, as do several other previous methods. However, some methods that marginalize over models give surprisingly strong results across a broad spectrum of tasks.
Dueling Decoders: Regularizing Variational Autoencoder Latent Spaces
May 17, 2019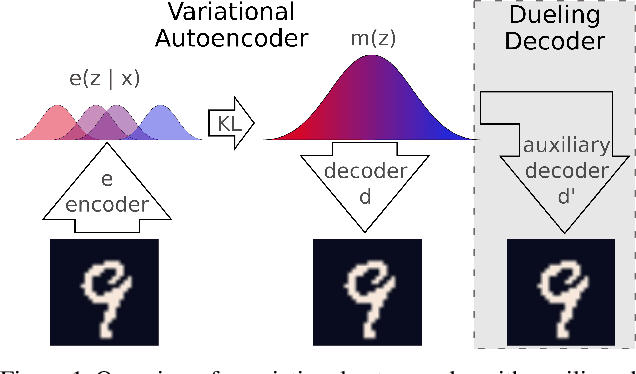
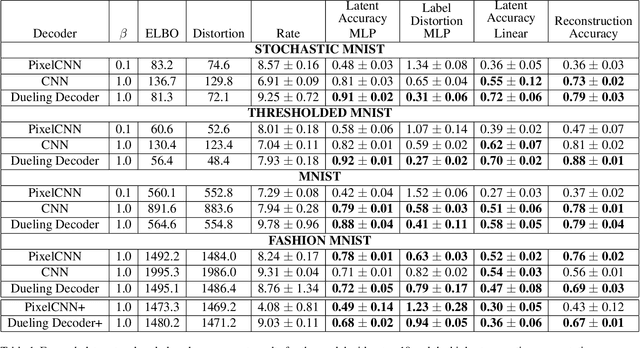

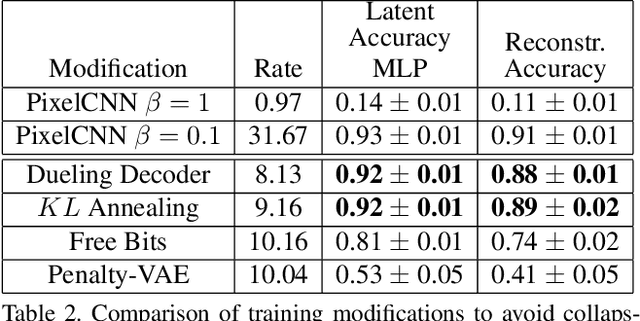
Variational autoencoders learn unsupervised data representations, but these models frequently converge to minima that fail to preserve meaningful semantic information. For example, variational autoencoders with autoregressive decoders often collapse into autodecoders, where they learn to ignore the encoder input. In this work, we demonstrate that adding an auxiliary decoder to regularize the latent space can prevent this collapse, but successful auxiliary decoding tasks are domain dependent. Auxiliary decoders can increase the amount of semantic information encoded in the latent space and visible in the reconstructions. The semantic information in the variational autoencoder's representation is only weakly correlated with its rate, distortion, or evidence lower bound. Compared to other popular strategies that modify the training objective, our regularization of the latent space generally increased the semantic information content.
$β$-VAEs can retain label information even at high compression
Dec 06, 2018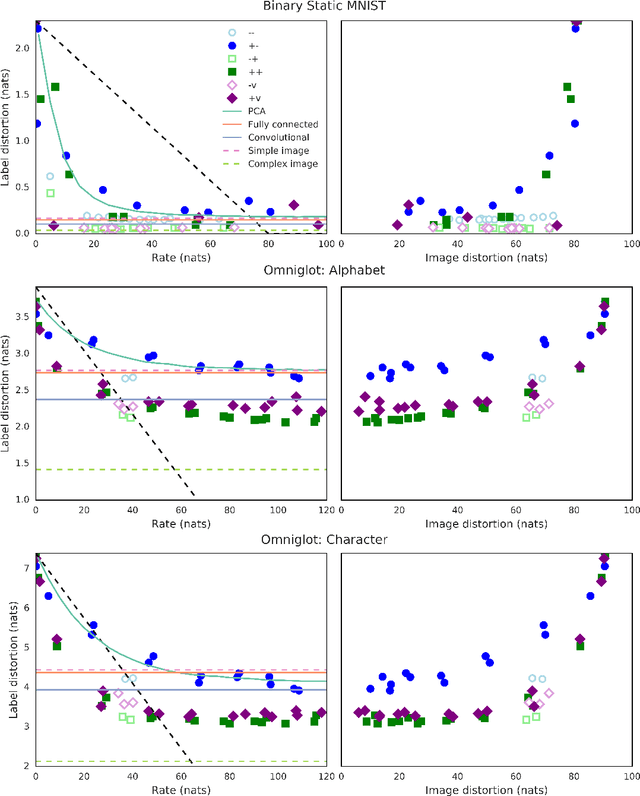
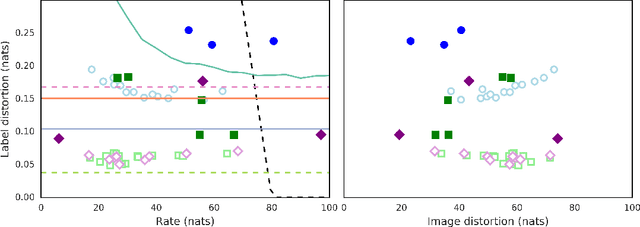
In this paper, we investigate the degree to which the encoding of a $\beta$-VAE captures label information across multiple architectures on Binary Static MNIST and Omniglot. Even though they are trained in a completely unsupervised manner, we demonstrate that a $\beta$-VAE can retain a large amount of label information, even when asked to learn a highly compressed representation.